







导入可能用到的Python库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import re
目标
- 学习机器学习算法——线性分类器
- 使用良性/恶性乳腺癌肿瘤数据集进行预测
理论学习
线性分类器
特征与分类结果存在线性关系的模型为线性分类器,模型通过累积特征和对应权值的方式决策,几何学上可看成一个n维空间中的超平面,学习的过程就是不断调整超平面的位置与倾斜程度,使该超平面可以最完美的将属于不同类别的特征点区分开,公式为:$$f(w,x,b) = w^{T}x+b$$
logistic 函数
线性分类器输出的是一个数,我们希望这个数在区间[0,1]之间,需要一个映射关系,这个映射关系就是logistic函数$$g(x) = \cfrac{1}{1 + e^{-x}}$$下面使用numpy和matplot绘制该函数的图像
x = np.linspace(start=-10,stop=10,num=1000)
y = 1 / (1 + np.exp(-x))
plt.plot(x,y)
plt.show()
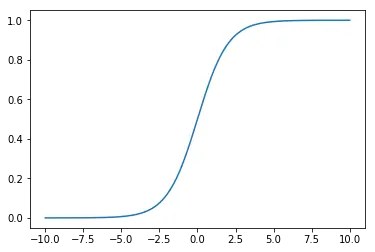
logistics.png
将线性分类器公式带入logistics函数后,可得logistics回归模型$$f(x,w,b) = \cfrac{1}{1 + e{-(w{T}x+b)}}$$
优化
完成了模型的构建之后,需要对算法进行优化已确定最优的W和b参数。这时,需要一个函数用于评价现有参数的质量,这个函数应该满足以下条件
- 连续可导(用于基于梯度的优化算法需要连续可导)
- 当预测结果越正确时,函数取值越大;预测结果越错误时,函数取值越小(反过来也可)
对于一个logistics的线性分类器,可以将输出看做取1值的概率,那么,该分类器可以视为一个条件概率$P(y|x)$,其中w与b是分布的参数,于是我们使用最大似然估计的方法确定这个评价函数(其中y是期望输出,即正确值)$$l(w,b) = \prod ((f(w,b,x))^{y}*(1 - f(w,b,x))^{1 - y})$$
- 是否连续可导
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









