






预处理
原本使用数据为txt格式,并且主要就是不同时间序列的特征提取。使用普通的数据预处理方式。将数据先切分为训练集和测试集,接着将测试集切分为验证集和测试集
主要就是与原本的处理方式不同,核心还是对图卷积神经网络的学习
图卷积神经网络

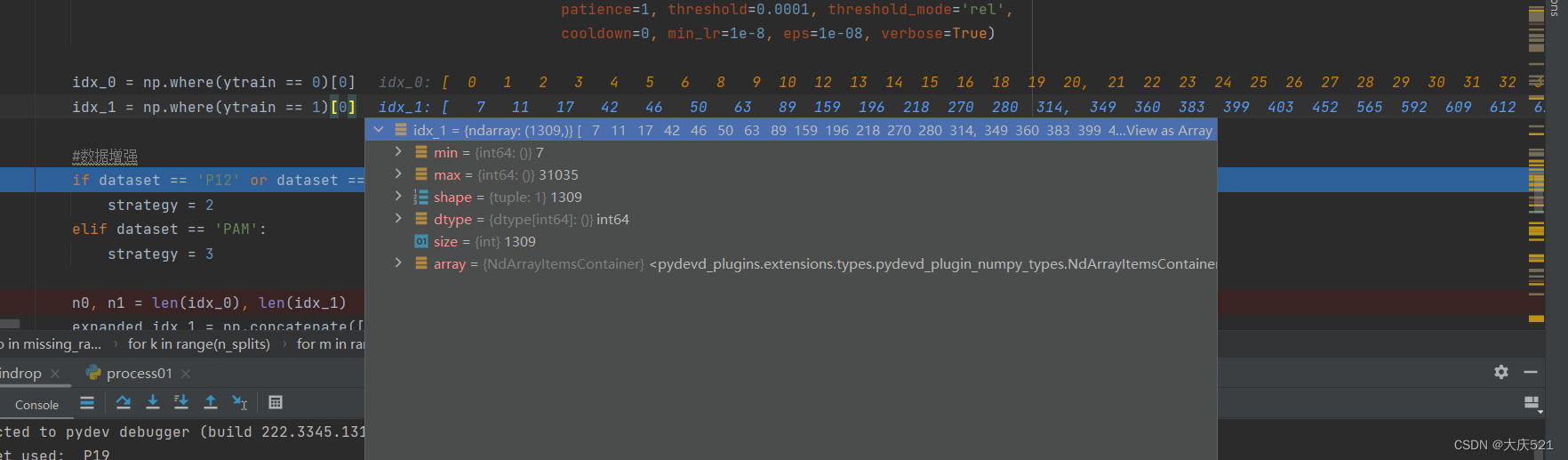
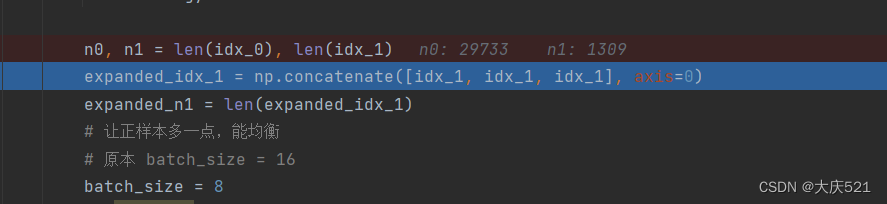
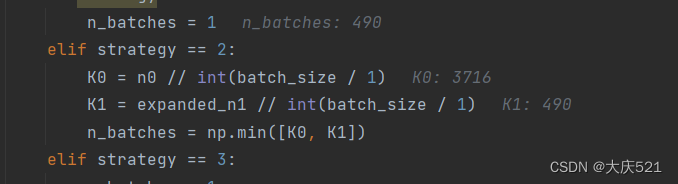
将embedding调到2,复制倍数调到2
# 定时清内存
import torch, gc
gc.collect()
torch.cuda.empty_cache()
放在了使用cuda之后
之后就是少一个文件夹,重新建立即可。
models_rd.py运行
代码函数运行顺序
首先运行顺序
class PositionalEncodingTF(nn.Module):
def __init__(self, d_model, max_len=500, MAX=10000):# 本身函数还未调用所以先没有运行
def getPE(self, P_time):
def forward(self, P_time):
class Raindrop(nn.Module):
class Raindrop_v2(nn.Module):进入Raindrop_V2函数
# 模型属性定义
def __init__(self, d_inp=36, d_model=64, nhead=4, nhid=128, nlayers=2, dropout=0.3,
max_len=215, d_static=9,MAX=100, perc=0.5, aggreg='mean', n_classes=2,
global_structure=None, sensor_wise_mask=False, static=True):
# 权重初始化
def init_weights(self):
# 前向传播
def forward(self, src, static, times, lengths):Raindrop函数和Raindrop_V2函数的内部运行顺序相同。
主程序学习结果
将主要的epoch值和复制倍数折半的减少,程序调通,主要问题在于电脑配置。剩下的问题等下次再写。















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









