






GRAPH-GUIDED NETWORK FOR IRREGULARLYSAMPLED MULTIVARIATE TIME SERIES论文附录
A1:编码时间戳
对于给定的时间值t,我们将其传递给频率为10,000的三角函数(V aswani et al, 2017),并通过(Horn et al, 2020)生成时间表示![]() ∈
∈![]() (为简洁起见省略样本指数i):
(为简洁起见省略样本指数i):
其中ξ为期望维数。在这项工作中,我们在所有模型的所有实验设置中设置ξ = 16。请注意,我们将时间值编码为连续的时间戳,而不是表示时间序列中观测顺序的离散整数时间位置。
A2:关于计算时间注意力权重的附加信息
公式4描述了我们如何学习传感器v的时间注意力权重向量βi,v,遵循自我注意形式主义。与生成自我注意矩阵的标准自我注意机制不同,我们生成了一个时间注意权重向量。这是因为我们只需要一个注意权重向量(而不是矩阵),通过加权和将观测嵌入聚合为单个传感器嵌入。
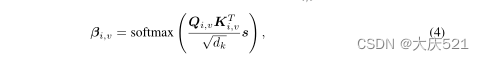
在标准的自注意矩阵中,每个元素表示一个观察嵌入对另一个观察嵌入的依赖关系。类似地,每行描述了一个观测嵌入对所有其他观测嵌入的依赖关系(所有观测都属于同一个传感器)。我们的直觉是将自注意矩阵中的一行聚合成一个标量,表示观测嵌入对整个传感器嵌入的重要性。
在实践中,我们将加权聚合(参数为s)应用于自注意矩阵中的每一行,并将生成的标量连接成一个注意向量。接下来,我们给出一个具体的例子来具体描述s的含义。自注意矩阵的每一行j都捕获了观测嵌入htj与所有观测嵌入![]() 的关系。然后,使用可学习的权重向量s,这些观测值之间的相关性随时间聚合,以获得时间重要性权重βtj。βtj代表了相应观测对整个传感器嵌入的重要性。
的关系。然后,使用可学习的权重向量s,这些观测值之间的相关性随时间聚合,以获得时间重要性权重βtj。βtj代表了相应观测对整个传感器嵌入的重要性。
A3:关于样本嵌入的附加信息
由于我们通过拼接所有传感器嵌入来生成样本嵌入,当传感器数量较多时,样本嵌入会相对较长。为了缓解这个问题,一方面,我们可以通过在拼接后增加一个神经层(比如简单的全连接层)来降低样本嵌入的维数。另一方面,当传感器数量非常大时,我们的模型是灵活的,可以毫不费力地将拼接切换到其他读出函数(例如平均聚合):这将自然地解决长向量的问题。我们的经验表明,在我们的情况下,串联比平均更好。我们发现,使用串联而不是平均来生成样本嵌入,AUROC分数提高了0.6% (P19;设置1)。
A4:关于样本相似性的附加信息
在这项工作中,我们假设所有样本在某种程度上具有一些共同的特征。在建模样本间的相似性时,我们不考虑样本在潜在组内相似而在组间不同的情况。
我们的研究重点是不规则性问题,而不是时间序列中的分布移位问题。为此,在我们的实验中,我们首先使用标准的评估设置(设置1,不规则时间序列的分类)对Raindrop进行严格的基准测试。这是大多数现有方法考虑的唯一设置(例如,Shukla & Marlin (2021);Che et al(2018)),我们希望确保我们的比较是公平的。为了对Raindrop的性能进行更严格的评估,我们还在实验中考虑了更具挑战性的设置(即设置2-4),当数据集以非标准的方式评估并且分割由选择数据属性通知时。
表3:数据集统计信息。
timestamps :数据集中测量的所有采样时间戳的数量
classes:数据集标签中类别的数量。
Static info:表示样本的静态属性(例如,身高和体重)是否可用。
missing ratio:如果数据集被完全观测,缺失观测的数量与所有可能观测的数量之间的比率。

我们在设置1上的结果与设置2-4上的结果一致。在更难的设置2-4上的结果表明Raindrop可以比基线表现得更好。在这些不同环境下的结果增加了我们对雨滴相当灵活和广泛适用的信心。
A5:关于数据集的进一步详细信息
P19: PhysioNet Sepsis Early Prediction Challenge 2019.P19数据集(Reyna et al, 2020)包含38,803例患者,每个患者由34个不规则采样传感器监测,包括8个生命体征和26个实验室值。原始数据集有40,336例患者,我们去掉时间序列过短或过长的样本,剩下38,803例患者(最长的患者时间序列有多于1次且少于60次观察)。每个患者都与一个静态向量相关,表示属性:年龄、性别、入院到ICU的间隔时间、ICU类型、ICU住院天数(天)。每个患者都有一个二进制标签,表示在接下来的6小时内发生败血症。数据集高度不平衡,只有~ 4%的阳性样本。
P12: PhysioNet Mortality Prediction Challenge 2012.P12数据集(Goldberger et al, 2000)包括11,988名患者(样本),之后删除了12个不适当的样本(Horn et al, 2020)。每个患者包含36个传感器(不包括体重)的多元时间序列,收集于ICU前48小时。每个样本都有一个包含年龄、性别等9个元素的静态向量。每个患者都有一个标明ICU住院时间的二元标签,其中阴性标签表示住院时间不超过3天,阳性标签表示住院时间超过3天。P12不平衡,有~ 93%的阳性样本。
PAM: PAMAP2 Physical Activity Monitoring.PAM数据集(Reiss & Stricker, 2012)用3个惯性测量单位测量9名受试者的日常生活活动。我们对其进行了修改,以适应我们的不规则时间序列分类场景。由于传感器读数较短,我们排除了第九名受试者。我们将连续信号分割成样本,时间窗口为600,重叠率为50%。PAM原本有18种日常生活活动。我们排除了小于500个样本的活动,剩下8个活动。修改后的PAM数据集包含5333个感觉信号片段(样本)。每个样本由17个传感器测量,包含600个连续观测值,采样频率为100 Hz。为了使时间序列不规则,我们随机移除60%的观测值。为了保持公平的比较,删除的观察是随机选择的,但对所有实验设置和方法保持相同。PAM分为8类,每一类代表一种日常生活活动。PAM不包括静态属性,并且样本在所有8个类别中大致平衡。
为了将给定的数据输入到神经网络中,如果没有测量值,我们将输入设为零。在高度不平衡的数据集(P19和P12)中,我们执行批少数类上抽样,这意味着每个处理的批具有相同数量的正类和负类样本。包括稀疏比在内的数据集统计数据见表3
A6:关于模型超参数的进一步细节
Baseline hyperparameters. 基线的实施遵循了相应的论文,包括SeFT (Horn et al, 2020), GRU-D (Che et al, 2018)和mTAND (Shukla & Marlin, 2021)。在我们的工作中实现Transformer时,我们遵循(Horn et al, 2020)中Transformer基线的设置。对于Trans-mean的平均imputation,我们用传感器中观测值的全局平均值替换缺失值(Shukla & Marlin, 2020)。我们使用批次大小为128,学习率为0.0001。注意,我们在每批中对少数群体进行了上抽样,使批间平衡(每批中64个正样本和64个负样本)。
所选择的超参数在数据集(P19, P12, PAM)、模型(包括基线和RAINDROP)和实验设置中是相同的。值得注意的是,我们发现在set 2-3中,所有基线对PAM都做了虚假的预测(将所有测试样本归为多数标签),而RAINDROP的预测是合理的。为了使比较有意义(即基线可以做出有意义的预测),我们对PAM的基线使用0.001的学习率。GRU-D有49层,而其他模型只有2层。我们将所有模型运行20个epoch,将获得最高AUROC的参数存储在验证集中,并使用它对测试样本进行预测。我们使用Adam算法进行基于梯度的优化(Kingma & Ba, 2014)。
RAINDROP hyperparameters.接下来,我们报告RAINDROP中唯一超参数的设置。在生成观测嵌入时,我们将Ru设为4维向量,因此生成的观测嵌入具有4维。时间表示的维数pt和rv都是16。可训练权矩阵D的形状为4 × 32。wu和wvv的尺寸与传感器数量相同,P19为34,P12为36,PAM为17。我们设置RAINDROP层数L为2,而第一层修剪边缘,第二层没有。我们将边缘修剪的比例设置为50% (K=50),这意味着我们删除了一半具有最低权重的现有边缘。dk设置为20,而W的形状为20 × 20。所有的激活函数,没有特别的说明,都是sigmoid函数。da设置为传感器个数。其中φ的第一层有128个神经元,第二层有C个神经元(即P19和P12为2个;PAM为8)。我们设置λ = 0.02来调整Lr正则化尺度。所有预处理数据集和实现代码均可在线获取。更多细节可通过RAINDROP的代码和数据集存储库获得。
读出函数。这里我们在3.5节讨论读出函数g的选择。我们的初步实验表明,级联优于其他流行的聚合函数,如平均(Errica et al, 2021)和挤压激励读取函数(Kim et al, 2021;Hu等人,2018)。虽然可以考虑这些聚合函数中的任何一个,但我们在这篇手稿中的所有实验中都使用了串联。
A7:性能指标
由于P19和P12数据集是不平衡的,我们使用ROC曲线下面积(AUROC)和Precision-Recall曲线下面积(AUPRC)来衡量性能。由于PAM数据集接近平衡,我们还报告了准确性、精密度、召回率和F1分数。我们报告5个独立运行的平均值和标准偏差值。在验证集上获得最佳AUROC值的模型参数用于测试集。
A.8 关于设置2的设置细节的进一步细节
在设置2中,选择的缺失传感器在不同的模型中是固定的,并通过以下方式进行选择。首先,我们计算每个传感器的重要性得分,并按降序排列。
重要性评分基于信息增益,我们通过将观察结果输入具有20棵决策树的随机森林分类器来计算。特别地,我们将每个样本视为只有一个传感器,然后将单个传感器输入随机森林分类器并记录AUROC。
AUROC越高,说明传感器的信息增益越高。当我们根据其AUROC值对传感器进行排名时,我们选择前n个传感器(AUROC值最高的传感器),并将这些传感器中的所有观测值替换为验证和测试集中所有样本中的零。缺失传感器的数量由用户间接定义,传感器的缺失比范围为0.1 ~ 0.5。
A9:关于缺失图案的附加信息
本文提出了一种通过传感器间依赖来解决多元时间序列不规则性的新方法RAINDROP。对于不规则性,RAINDROP与其他解决方案(如缺失模式和时间衰减)并不冲突。然而,由于缺失模式在建模不完全时间序列中被广泛讨论(Che et al, 2018),我们探索了如何将关系结构和缺失模式的优势结合起来。我们采用掩码矩阵作为缺失模式的代理(2018)。以RAINDROP的架构为例,我们将观测值xti,u与二进制掩码指示器bti,u作为输入。当传感器i在t时刻有观测时,指示器bti,u设为1,否则设为0。所有实验设置和超参数均与RAINDROP (P19;设置1).实验结果表明,利用缺失模式可以使P19的AUROC略微提高1.2%,AUPRC略微提高0.9%。这为以后不规则时间序列的多特征整合表征研究提供了经验依据。
A10:时间注意与LSTM的比较
我们进行了大量的实验来比较时间注意和LSTM的有效性。为此,我们将RAINDROP中传感器嵌入生成(Eq 4-5)中的时间注意力替换为LSTM层,LSTM层对所有观测嵌入进行顺序处理。我们使用零填充将不规则观测转换为固定长度的时间序列,这样数据就可以输入到LSTM架构中。
我们将LSTM的最后输出作为生成的传感器嵌入。LSTM细胞数与观测包埋尺寸相等。除时间注意部分与LSTM部分外,其余模型结构基本相同。我们保留所有实验设置(P19;设置1)和超参数选择相同。实验结果表明,时间自我注意算法比LSTM算法提高了1.8% (AUROC),并节省了49%的训练时间。一个潜在的原因是,自注意机制避免了递归,允许并行计算,还减少了长期依赖导致的性能下降(Ganesh等人,2021;Vaswani等人,2017)。
A11:关于方法基准测试的附加信息
以实验设置1(即经典时间序列分类)为例,我们进行了大量的实验,将Raindrop与ODE-RNN (Chen et al, 2020)、DGM2-O (Wu et al, 2021)、EvoNet (Hu et al, 2021)和MTGNN (Wu et al, 2020c)进行了比较。由于IP-Net (Shukla & Marlin, 2018)和mTAND (Shukla & Marlin, 2021)来自同一作者,我们只比较mTAND是最新的模型。对于基线,我们遵循其公共代码中提供的设置。对于不能处理不规则数据的方法(如EvoNet和MTGNN),我们首先使用均值imputation对缺失数据进行imputation,然后将数据输入模型。对于与所提出的分类模型严格不具有可比性的预测模型(例如MTGNN),我们将任务制定为单步预测,将从所有传感器学习到的表示串联起来,并输入到全连接层(作为分类器工作)进行预测,并使用交叉熵来量化损失。
A12:p19的结果(设置2-3)
在这里,我们报告了设置2(表4)和设置3(表5)中P19的实验结果
Table4:固定缺失传感器样本的分类(P19;设置2)
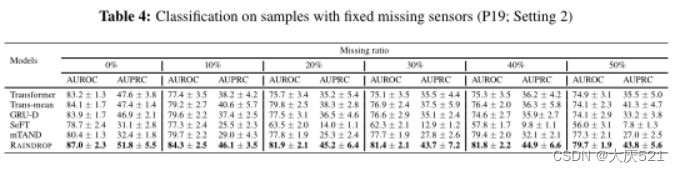
表5:随机缺失传感器样本的分类(P19;设置3)

表6:RAINDROP剔除依赖图后的结果比较(P19;设置4).除“RAINDROP w/o graph”一行外,结果与表8相同,其中我们不考虑传感器之间的依赖关系,在依赖关系图中将所有传感器设置为独立的。
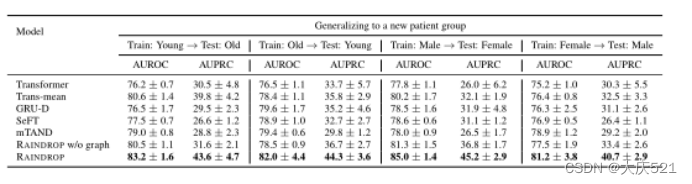
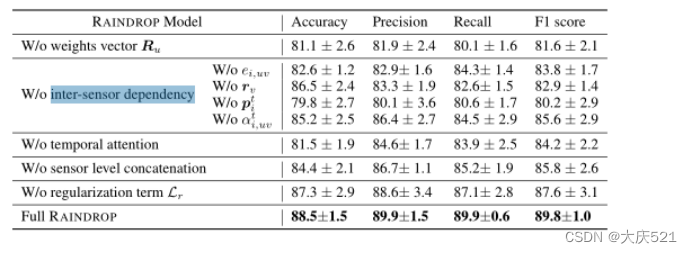
表7:PAM数据集消融研究结果(设置1)
A13:对分组时间序列分类的评价
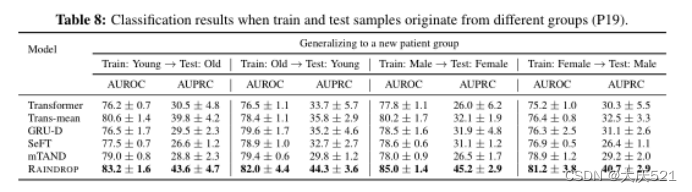
了解RAINDROP在训练模型时是否能自适应调整其结构,并很好地推广到其他未观察到的样本组。在这个设置中,我们根据特定的静态属性将数据分为两组。第一个分割属性是年龄,我们将人们分为年轻人(< 65岁)和老年人(≥65岁)两组。我们还根据性别属性将患者分为男性和女性。给定split属性,我们使用一组作为训练集,并将另一组随机分为相同大小的验证集和测试集。
以P19为例,给出训练样本和测试样本来自不同组时的分类结果。如表8所示,RAINDROP在所有四个给定的跨组场景中都获得了最佳结果。例如,在对男性患者进行训练和对女性患者进行测试时,RAINDROP声称与第二好的模型相比有很大的差距(AUROC的4.8%和AUPRC的13.1%的绝对改善)。
虽然RAINDROP的设计没有明确地解决域适应问题,但结果表明,当从一组样本转移到另一组样本时,RAINDROP的表现比基线更好。
我们表现良好的一个原因是,学习到的传感器间权重和依赖关系图是特定于样本的,它们的学习是基于样本的观察结果。因此,本文提出的RAINDROP在一定程度上能够根据测试样本的测量值自适应地学习传感器间的依赖关系。RAINDROP不是泛化到新的组,而是泛化到新的样本,这导致了一个很好的性能,即使我们的模型不是为域自适应设计的。我们从经验上验证其原因。我们删除了传感器之间的依赖关系(在依赖关系图中设置所有隔离的传感器;将RAINDROP中所有αti、uv和eti、uv均设为0),对模型进行分组时间序列分类。实验结果表明,排除RAINDROP中的依赖关系图和消息传递后,性能下降了很多(表6)。如果没有传感器间的依赖关系,我们的模型与其他基线相当,并且性能并没有大幅超过它们。
- 负样本
- 正样本
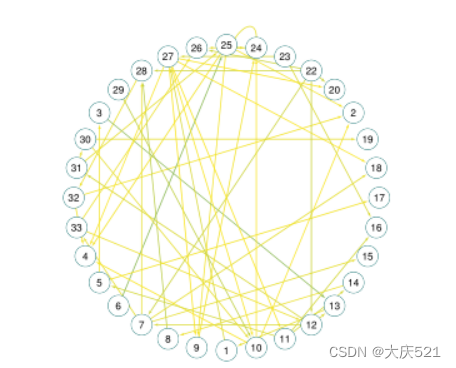
图4:阴性和阳性样本的学习结构(P19;设置1). 0 ~ 33的节点表示P19中使用的34个传感器(传感器名称见附录A.15)。为了使可视化结构更容易理解,我们使用深绿色表示权重值较高,黄色表示权重值较低。


我们可以在两个学习的传感器依赖图中观察到可区分的模式,这表明RAINDROP能够自适应地学习对分类任务敏感的图结构。例如,我们发现淋巴结1(脉搏血氧饱和度)、5(舒张压)和12(来自动脉血液的二氧化碳分压)在阴性样本中的权重较低。
表8:训练样本和测试样本来自不同组时的分类结果(P19)。
A14:关于消融研究的进一步细节
我们进行消融研究,以设置1时PAM为例,见表7。在W/O传感器级拼接”的设置中,我们取所有传感器嵌入的平均值(而不是将它们拼接在一起)以获得样本嵌入。实验结果表明,完整雨滴模型的性能最好,说明每个部件或设计的结构都对模型有用。例如,我们发现排除传感器间注意权值αti,uv将导致准确度下降3.9%,而排除边缘权值ei,uv(即依赖图)将使准确度下降7.1%。
A15:雨滴学习的传感器间依赖关系图的可视化
我们将在早期败血症预测中P19上学习到的传感器间依赖关系(即Eq. 3中平均操作之前的ei,uv)可视化。可视化是用Cytoscape实现的(Shannon et al, 2003)。所示数据为P19测试集,包括3881个样本(3708个阴性,173个阳性)。当RAINDROP学习每个样本的特定图形时,我们取所有正样本的平均值,并将其可视化在图4b中;并在图4b中可视化所有负样本的平均值。当我们取平均值时,权重小于0.1的边(意味着它们很少出现在图中)会被忽略。平均边权值范围从0.1到1。我们将所有样本图初始化为有1156 = 34 × 34条边的完整图,然后在训练阶段修剪掉其中的50%,剩下578条边。图中的34个节点表示P19中测量的34个传感器,如所示
图5:正样本和负样本之间依赖关系图的差异结构。这些边是有方向的。我们选择两个模式之间差异(绝对值)最大的前50条边。边缘由发散处着色。颜色越深表示连接对分类任务更重要。节点0未连接任何传感器,故不包括在图中。我们可以推断患者是否会发生败血症,心率是稳定的。此外,我们可以看到从节点3(收缩压)到节点13(动脉血氧饱和度)的边缘和从节点6(呼吸速率)到节点25(钾)的连接是区分样本类别的信息。
列出传感器名称:0:
我们还可视化了来自可能患有败血症的患者的习得依赖图和来自不太可能患有败血症的患者的图之间的差异传感器间的连接。基于阳性和阴性样本的聚集图结构,我们计算两组患者之间的差异,并将结果报告在图5中。具体而言,我们根据负样本和正样本中边权的绝对差对边进行排序。在50个最独特的边缘的可视化之上,我们可以得到一系列具体的见解。例如,节点6(呼吸速率)和节点25(钾)之间的依赖关系对脓毒症的早期预测很重要。请注意,这些数据驱动的观察可能有偏见,仍需要医疗保健专业人员的确认和未来的分析。图4和图5中的边都是有向的。由于图形尺寸较小,边缘箭头可能难以识别。我们将向我们的公共存储库提供高分辨率的数据。
此外,我们统计测量了同一类样本之间的相似性和不同类样本之间的不相似性。具体来说,对于每个样本,我们计算:1)它的依赖关系图与同一类所有样本的依赖关系图之间的平均欧几里得距离;2)与不同类别的所有样本的平均距离。P19数据集有38,803个样本,其中1623个阳性样本和37,180个阴性样本。为了进行公平的比较,我们从阴性队列中随机选择1623个样本,然后将它们与等量的阳性样本混合,以测量类内和类间的平均欧几里得距离。我们选择5次独立的队列进行替换。我们发现阳性样本间的依赖关系图之间的距离((8.6±1.7)× 10−5)小于样本间的距离((12.9±3.1)× 10−5)。结果表明,学习到的依赖关系图在同一类内是相似的,而在类间是不同的,这说明RAINDROP可以学习到标签敏感的依赖关系图。















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









