




 本文介绍了空间转换器网络,这是一种可微分的模块,允许在卷积神经网络中进行空间变换。空间转换器由定位网络、参数化采样网格和可微图像采样组成,通过定位网络预测变换参数,采样网格生成器创建采样点,采样器则执行特征图的变换。这种变换提高了模型对平移、缩放、旋转等变换的不变性,无需额外监督训练。文章详细阐述了变换参数的生成、采样网格的创建以及可微图像采样的过程,展示了其在提升模型能力方面的潜力。
本文介绍了空间转换器网络,这是一种可微分的模块,允许在卷积神经网络中进行空间变换。空间转换器由定位网络、参数化采样网格和可微图像采样组成,通过定位网络预测变换参数,采样网格生成器创建采样点,采样器则执行特征图的变换。这种变换提高了模型对平移、缩放、旋转等变换的不变性,无需额外监督训练。文章详细阐述了变换参数的生成、采样网格的创建以及可微图像采样的过程,展示了其在提升模型能力方面的潜力。
文章目录
引入
题目:Spatial transformer networks
演示:https://goo.gl/qdEhUu
代码:
摘要:卷积神经网络定义了一类有力模型,但依然受到输入数据空间不变 (spatially invariant)的限制。本文引入一个新的可学习模块,即空间转换器 (spatial transformer),其明确允许在网络内对数据进行空间操作。该可微分模块可以应用到现有的卷积架构中,使得网络能够主动空间变换特征图,而无需额外的监督训练,或优化更改。本文验证了空间转换器的使用,可以使得模型习得平移、缩放、旋转和更通用变换的不变性 (invariance),且相较于其他变换器有优势。
Bib:
@article{Jaderberg:2015:20172025,
author = {Max Jaderberg and Karen Simonyan and Andrew Zisserman and Koray Kavukcuoglu},
title = {Spatial transformer networks},
journal = {Advances in Neural Information Processing Systems},
volume = {28},
year = {2015},
pages = {2017--2025}
}
1 空间转换器 (spatial transformer)
空间转换器是一个可微分模块,可用于单次前向传递期间,对特征图的空间变换,其中变换以特定输入为条件,并产生单个特征图输出。对于多通道输入,每个通道应用相同的变换。本节仅考虑单个变换和每个变换器的单个输出,多个变换的推广则在实验进行。
空间转换器可分为三个部分,如图2:
1)定位网络 (localisation network):获取输入特征图,并通过多个隐藏层输出应该应用于特征图的空间变化参数;
2)网格生成器 (grid generator):使用预测的空间变换参数创建采样网格,其是一组点的集合;
3)采样器 (sampler):以特征图和采样网格作为输出,生成从网格点输入的采样输出图。

1.1 定位网络 (localisation network)
输入:特征图
U
∈
R
H
×
W
×
C
U\in\mathbb{R}^{H\times W\times C}
U∈RH×W×C,其中
H
H
H、
W
W
W、
C
C
C分别对应高、宽、通道。
输出:变换
T
θ
\mathcal{T}_\theta
Tθ的参数
θ
\theta
θ,其可用于特征图,即
θ
=
f
loc
(
U
)
\theta=f_\text{loc}(U)
θ=floc(U),其大小根据变换的类型而变化。
f
loc
(
⋅
)
f_\text{loc}(\cdot)
floc(⋅)是一个可以采用任何形式的定位网络,例如一个全连接网络或者卷积网络,但应该包含一个最终的回归层 (regression layer),以生成变换参数
θ
\theta
θ。
1.2 参数化采样网格 (parameterised sampling grid)
为了对输入特征图进行变换,每个像素都使用以输入特征图为中心的采样核的计算。在这里,像素作为通用特征图的元素而不一定是图像。通常,输出像素被定义为位于像素
G
i
=
(
x
i
t
,
y
i
t
)
G_i = (x_i^t,y_i^t)
Gi=(xit,yit)上的规则网格
G
=
{
G
i
}
G=\{G_i\}
G={Gi}。所有的网格构成输出特征图
V
∈
R
H
′
×
W
′
×
C
V\in\mathbb{R}^{H'\times W'\times C}
V∈RH′×W′×C。注意当前步骤的输入输出形状一致。
为了清楚描述,暂时假设
T
θ
\mathcal{T}_\theta
Tθ是一个2D仿射变换
A
θ
A_\theta
Aθ。此时的逐点变换 (pointwise transformation)为
(
x
i
s
y
i
s
)
=
T
θ
(
G
i
)
=
A
θ
(
x
i
s
y
i
s
1
)
=
[
θ
11
θ
12
θ
13
θ
21
θ
22
θ
23
]
(
x
i
s
y
i
s
1
)
(1)
\tag{1} \left(\begin{matrix} x_i^s\\ y_i^s \end{matrix}\right)=\mathcal{T}_\theta(G_i)=A_\theta \left(\begin{matrix} x_i^s\\ y_i^s\\ 1 \end{matrix}\right)= \left[\begin{matrix} \theta_{11} & \theta_{12} & \theta_{13}\\ \theta_{21} & \theta_{22} & \theta_{23}\\ \end{matrix}\right] \left(\begin{matrix} x_i^s\\ y_i^s\\ 1 \end{matrix}\right)
(xisyis)=Tθ(Gi)=Aθ⎝⎛xisyis1⎠⎞=[θ11θ21θ12θ22θ13θ23]⎝⎛xisyis1⎠⎞(1)其中
(
x
i
t
,
y
i
t
)
(x_i^t, y_i^t)
(xit,yit)规则网格在输出特征图上的目标坐标,
(
x
i
s
,
y
i
s
)
(x_i^s, y_i^s)
(xis,yis)定义了采样点的、在输入特征图上的源坐标。我们使用高和宽来标准化坐标,使得
−
1
≤
x
i
t
,
y
i
t
≤
1
-1\leq x_i^t,y_i^t \leq 1
−1≤xit,yit≤1以及
−
1
≤
x
i
s
,
y
i
s
≤
1
-1\leq x_i^s, y_i^s \leq 1
−1≤xis,yis≤1。源/目标变换和采样相当于图像中使用的标准纹理映射和坐标。
公式1中定义的变换允许对输入特征图应用裁剪、平移、旋转、缩放和倾斜,并且只需要定位网络生成
A
θ
A_\theta
Aθ的六个参数。进一步,其允许裁剪的原因是,如果变换是收缩 (contraction),那么映射的规则网格将位于面积小于
s
s
s范围的平行四边形中。图3展示了该变化与恒等变换的区别。
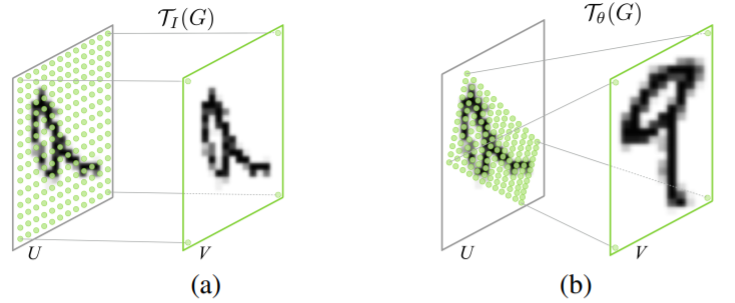
事实上,
T
θ
\mathcal{T}_\theta
Tθ可以有更多的约束,例如
A
θ
=
[
s
0
t
x
0
s
t
y
]
(2)
\tag{2} A_\theta = \left[\begin{matrix} s & 0 & t_x\\ 0 & s & t_y\\ \end{matrix}\right]
Aθ=[s00stxty](2)其允许裁剪、平移和各向同性缩放。该变换也可以更具普适性,例如基于八个参数的屏幕投影、分段放射和thin plate spline。事实上,该变换可以有任何的参数形式,只要它在参数方面是可微的。
1.3 可微图像采样 (differentiable image sampling)
为了对输入特征图进行空间变换,采样器必须保有点集
T
θ
(
G
)
\mathcal{T}_\theta(G)
Tθ(G)、输入特征图
U
U
U、采样输出特征图
V
V
V。
T
θ
(
G
)
\mathcal{T}_\theta(G)
Tθ(G)上的每一个点
(
x
i
s
,
y
i
s
)
(x_i^s, y_i^s)
(xis,yis)定义了一个应用了采样核的输入上的空间坐标,这里采样核用于获取给定像素在输入
V
V
V上的特定值,可以记作:
V
i
c
=
∑
n
H
∑
m
W
U
n
m
c
k
(
x
i
s
−
m
;
Φ
x
)
k
(
y
i
s
−
n
;
Φ
y
)
∀
i
∈
[
1
…
H
′
W
′
]
∀
c
∈
[
1
…
C
]
(3)
\tag{3} V_{i}^{c}=\sum_{n}^{H} \sum_{m}^{W} U_{n m}^{c} k\left(x_{i}^{s}-m ; \Phi_{x}\right) k\left(y_{i}^{s}-n ; \Phi_{y}\right) \forall i \in\left[1 \ldots H^{\prime} W^{\prime}\right] \forall c \in[1 \ldots C]
Vic=n∑Hm∑WUnmck(xis−m;Φx)k(yis−n;Φy)∀i∈[1…H′W′]∀c∈[1…C](3)其中
Φ
x
\Phi_x
Φx和
Φ
y
\Phi_y
Φy是定义了图像差值的采样核
k
(
)
k()
k()的参数,
U
n
m
c
U_{nm}^c
Unmc是输入
c
c
c通道上的坐标
(
n
,
m
)
(n,m)
(n,m),
V
i
c
V_i^c
Vic是输出
c
c
c通道上坐标
(
x
i
t
,
y
i
t
)
(x_i^t,y_i^t)
(xit,yit)的像素
i
i
i。注意输入的每个通道进行了相同的采样,因此每个通道都进行了相同的变换,这保证了多个通道之间的空间一致性。
理论上,在可以相对于
x
i
s
x_i^s
xis和
y
i
s
y_i^s
yis定义梯度,任意的采样核都可以被使用。例如使用整数采样核时,我们有:
V
i
c
=
∑
n
H
∑
m
W
U
n
m
c
δ
(
⌊
x
i
s
+
0.5
⌋
−
m
)
δ
(
⌊
y
i
s
+
0.5
⌋
−
n
)
(4)
\tag{4} V_{i}^{c}=\sum_{n}^{H} \sum_{m}^{W} U_{n m}^{c} \delta\left(\left\lfloor x_{i}^{s}+0.5\right\rfloor-m\right) \delta\left(\left\lfloor y_{i}^{s}+0.5\right\rfloor-n\right)
Vic=n∑Hm∑WUnmcδ(⌊xis+0.5⌋−m)δ(⌊yis+0.5⌋−n)(4)其中
δ
(
)
\delta()
δ()是Kronecker增量函数。这个采样核等价于将
(
x
i
s
,
y
i
s
)
(x_i^s, y_i^s)
(xis,yis)的近邻点复制给
(
x
i
t
,
y
i
t
)
(x_i^t,y_i^t)
(xit,yit)。采用双线性采样核时:
V
i
c
=
∑
n
H
∑
m
W
U
n
m
c
max
(
0
,
1
−
∣
x
i
s
−
m
∣
)
max
(
0
,
1
−
∣
y
i
s
−
n
∣
)
(5)
\tag{5} V_{i}^{c}=\sum_{n}^{H} \sum_{m}^{W} U_{n m}^{c} \max \left(0,1-\left|x_{i}^{s}-m\right|\right) \max \left(0,1-\left|y_{i}^{s}-n\right|\right)
Vic=n∑Hm∑WUnmcmax(0,1−∣xis−m∣)max(0,1−∣yis−n∣)(5)其关于
U
U
U和
G
G
G的偏导定义为:
∂
V
i
c
∂
U
n
m
c
=
∑
n
H
∑
m
W
max
(
0
,
1
−
∣
x
i
s
−
m
∣
)
max
(
0
,
1
−
∣
y
i
s
−
n
∣
)
∂
V
i
c
∂
x
i
s
=
∑
n
H
∑
m
W
U
n
m
c
max
(
0
,
1
−
∣
y
i
s
−
n
∣
)
{
0
if
∣
m
−
x
i
s
∣
≥
1
1
if
m
≥
x
i
s
−
1
if
m
<
x
i
s
(7)
\tag{7} \begin{gathered} \frac{\partial V_{i}^{c}}{\partial U_{n m}^{c}}=\sum_{n}^{H} \sum_{m}^{W} \max \left(0,1-\left|x_{i}^{s}-m\right|\right) \max \left(0,1-\left|y_{i}^{s}-n\right|\right) \\ \frac{\partial V_{i}^{c}}{\partial x_{i}^{s}}=\sum_{n}^{H} \sum_{m}^{W} U_{n m}^{c} \max \left(0,1-\left|y_{i}^{s}-n\right|\right) \begin{cases}0 & \text { if }\left|m-x_{i}^{s}\right| \geq 1 \\ 1 & \text { if } m \geq x_{i}^{s} \\ -1 & \text { if } m<x_{i}^{s}\end{cases} \end{gathered}
∂Unmc∂Vic=n∑Hm∑Wmax(0,1−∣xis−m∣)max(0,1−∣yis−n∣)∂xis∂Vic=n∑Hm∑WUnmcmax(0,1−∣yis−n∣)⎩⎪⎨⎪⎧01−1 if ∣m−xis∣≥1 if m≥xis if m<xis(7)其中
∂
V
i
c
∂
x
i
s
\frac{\partial{V_i^c}}{\partial{x_i^s}}
∂xis∂Vic是类似的。这使得反向传播是可行的。

















 5952
5952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









