







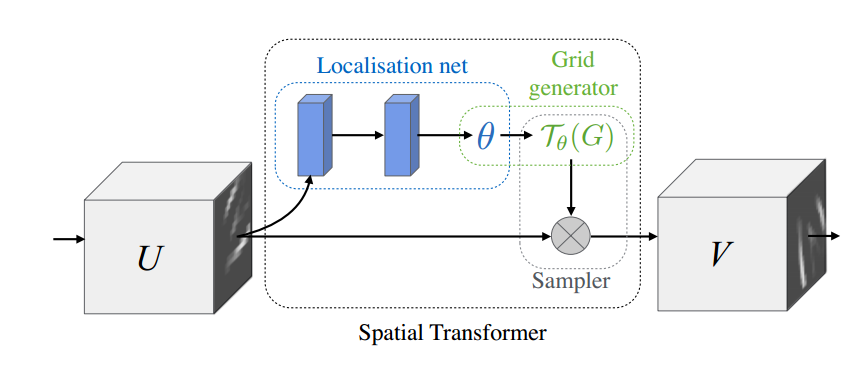
 本文详细介绍了空间变换网络(Spatial Transformer Networks, STN),它是一种可插入到CNN中的模块,无需额外训练就能学习平移、缩放、旋转等变换的不变性。STN在图像分类、共定位和空间注意力等应用中有重要作用。文中还概述了STN的工作流程,包括通过LocatNet获取仿射变换参数theta,然后通过双线性插值生成目标输出的步骤。"
9300609,711610,飞思卡尔DZ60单片机SCI查询接收技术解析,"['嵌入式硬件', '微处理器架构', '通信接口', '单片机开发']
本文详细介绍了空间变换网络(Spatial Transformer Networks, STN),它是一种可插入到CNN中的模块,无需额外训练就能学习平移、缩放、旋转等变换的不变性。STN在图像分类、共定位和空间注意力等应用中有重要作用。文中还概述了STN的工作流程,包括通过LocatNet获取仿射变换参数theta,然后通过双线性插值生成目标输出的步骤。"
9300609,711610,飞思卡尔DZ60单片机SCI查询接收技术解析,"['嵌入式硬件', '微处理器架构', '通信接口', '单片机开发']
Reference
what is STN ?
- module inserted to CNN without any extra training feature maps
- learn invariance to translation, scale, rotation, and more generic warping
Application
- image classification
- co-localisation
- spatial attention
Pipeline
- Forward
- 通过locatnet,提取输入图像的theta(将用于仿射变换);
- 根据输入图像的width和height以及仿射变换(或者TPS)的参数theta,可以生成目标位置在输入图像(U)中对应的位置(与输入图像位置一直的目标索引);
(由torch.bmm, Batch matrix matrix product of matrices生成)。 - 根据目标在输入图像中的对应位置(索引矩阵)利用双线性插值得到目标输出。
- backward
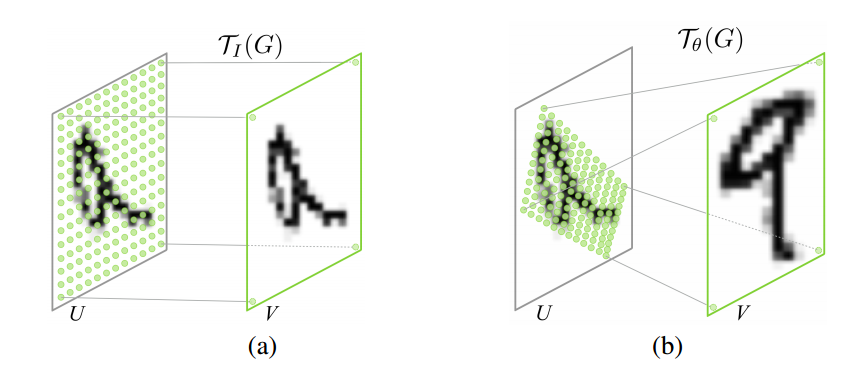
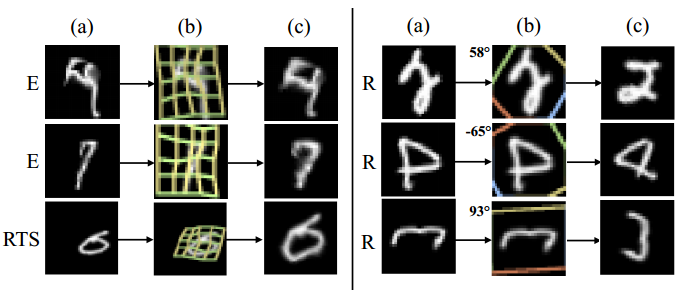
Examples















 6224
6224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









