







EfficientNet V2是发表在2021CVPR论文《EfficientNet V2:Smaller Models and Faster Training》
这个时候的vision Transformer还没有几个人去改进,所以这边稍微逊色了一点。

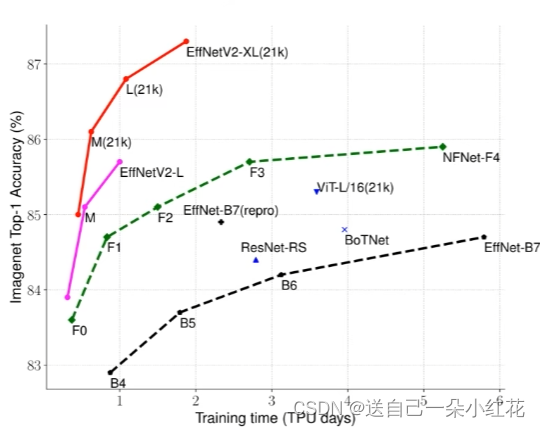
这张表格给出了EfficientNet与传统(融合)的卷积网络,vision transformer的对比
作者在v1中更关注准确率,参数数量以及FLOPs,但是理论计算量小代表不了推理速度,所以在v2中作者更关注模型的训练速度。
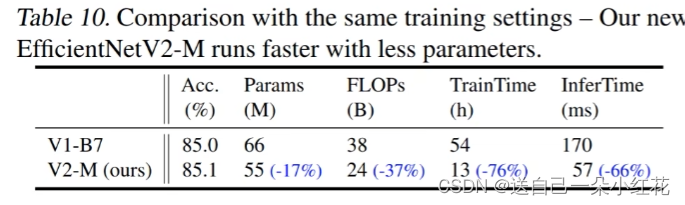
通过原文中给出的对比我们发现,确实有很大的优势。
作者在v1中发现了几个存在的问题:
1,训练图像的尺寸很大的时候,训练速度非常的慢,不成正比
2,在网络浅层中使用Depthwise Convlutions速度会很慢
3,同等的放大每个stage是次优的
--------------------------------------------------------------------------------------------------------------------------------
1 第一个问题就直接降低训练图像的尺寸,不仅能够加快训练速度,还能增大Batch,在no.1讲过,batch越大,训练效果越好。

2 在我们实际的使用上,我们发现,虽然DW卷积理论上的计算量小,但是实际的速度没有想象的快。我觉得可能是因为并行化太多了,反而占用了太多memory。所以提出Fused--MBConv结构。


上图表明不能全部使用Fused-MBConv,使用多了也没用。可以通过表看出,Fused-MBConv是替换了浅层网络的MBConv模块。
3同等放大每个stage是次优的。。在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
v2网络架构:

不同点:
前几层使用Fused-MBConv模块。
使用较小的ratio,比如4,6。
偏向使用3x3的模块,v1有5x5的。
移除了v1中最后一个步距为1的stage8。
Fused-MBConv模块:

要注意:stride=1,输入与输出矩阵channel相同;当我们用捷径分支的时候才有Dropout;Dropout层不是我们使用的随机失活元素,这里的是随机失活stage的主分支。
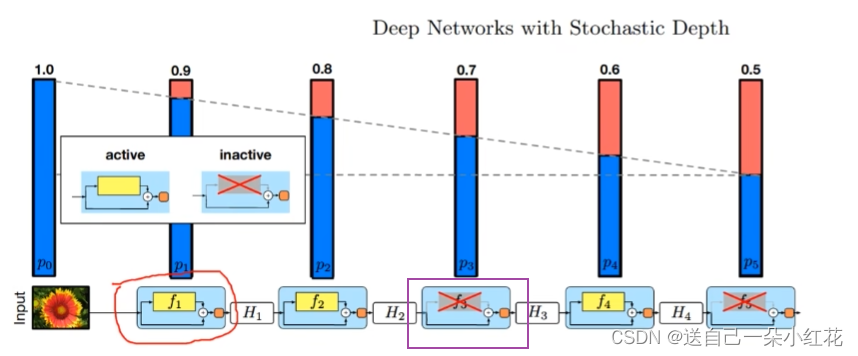
注意:这里的dropout层仅指Fused-MBConv模块以及MBConv模块中的dropout层,不包括最后全连接层前的dropout层。
progressive Learning 渐进式学习策略。


证明渐进学习策略是有效的,作者讲渐进学习策略应用到resnet和v1中,得到的结果是positive。














 833
833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









