







- 啃人群计数论文,第二篇!
2019年了,本着写一篇综述的心情(决心?),看一下2015年的论文,这时期还没有采用深度学习的方法,所以性能不好不说,设计也很复杂。脑壳痛
论文思路:把一张图片分成很多块(文中称之为patch),然后学习" patch的特征 "与 "patch之中物体相对位置 "的映射,然后再通过 高斯核密度估计 来生成patch的密度图,然后计数。
该文有3个创新点:
- 基于patch的方法,即将场景分块进行研究
- 随机森林的应用
- 提出半自动的训练方法
先简述一下现存分析方法:
- 基于检测
- 基于聚类
- 基于回归
在面对高密度人群时,前两种方法都傻了眼,所以,回归赛高。
整个骨干流程图如下:

说人话就是:先进行图片分块,然后提取每块的特征,然后通过随机森林和聚类的方法得到预测的标签,接着估计每块的密度,然后计算全局。
本博客讲述流程:随机森林----聚类模型预测----密度估计----更具鲁棒性的模型----半自动训练
**
一、随机森林
**
目的:分类,应用多棵由粗到精通的树,在每一个叶子节点训练一个分类函数,将patch中的特征进行分类,使得最后每一个叶子节点里的特征都比较 “纯”。
一个定义 : lable L 作为为一组位移向量,这些向量从patch 的中心出发,指向该patch内所有目标的位置P_j . 如下公式所示:
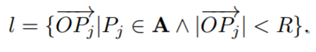
树形图如下:

采用随机森林带来一个很明显的优点,如论文中所说,It requires small memory space to build
and reserve the forest, as it contains only vector labels at its leaf nodes。即省内存,这样以便于有可能部署在一些嵌入式设备上。
来看看它具体是怎么分类的:
先把所有的样本集合set {(vi , li)} 都置于根节点,然后开始向下分类,分类根据是下面的阈值函数:
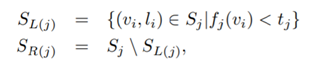
在每个节点 j ,随机的选取f_j (v) , f_j (v) and t_j 是特征向量V的测试函数,我们的目标是寻找一个函数f_j (v),使得样本被正确分类,这便是我们要求的 prediction function。
回归对象是向量的标签,这不同于求取位移向量和他们的空间分布—只有一个分裂标准(对于随机森林来说)不够。所以我们在不同的节点应用不同的分裂标准(上部分层和下部分层不一样)。
对于树的上部分层,prediction function是基于他们的空间分布信息,如下 :
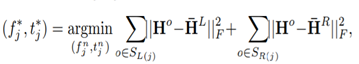
H表示直方图(柱状图),是由这个点周围的目标位置信息计算而来的。
H0是表示节点处空间位置信息的直方图(Ground_truth),Hl 和 Hr 是代表该节点分割后左右子集的直方图,|| . ||是L2范数,这个函数的目标就是拟合图中的空间分布信息。
对于树的下部分层,prediction function的分类标准是基于类不确定度(信息熵的差值):
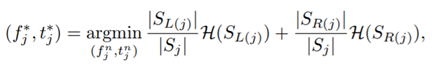
H(s) 是S中标签大小分布的信息熵,该函数的目标是使得每个叶子节点都更纯。即最后每个叶子节点中的标签几乎相同。
**
二、聚类模型预测
**
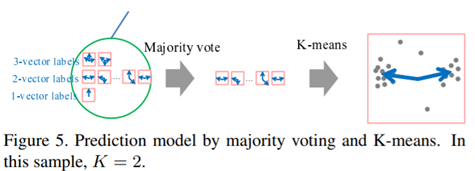
此刻,每个叶子节点里的标签都比较纯了,对其中的不同标签类型(视为不同簇)进行计数,只取其中最大的簇,其余视为噪声。将最大的簇应用K聚类,得到K个位移向量,这K个向量就代表了这个patch 的特征。所以,显而易见,占用memory很少。
此时,每棵树的叶子节点里都是对应的位移向量,那么,如何由这些向量生成密度图尼?咱们开始进行密度估计吧。
**
三、密度估计
**
上述生成的这些位移向量,都有一个投票权,即一个叶子节点里有K张票(每个节点的这个K不一样),他们投出来的,是每个patch的密度图。
每一票都是通过高斯核进行一个过滤,即最后将所有位移向量转换为密度图。(详细操作与高斯核的卷积有关)
但是,不能直接用刚才产生的密度图作为最后的结果,因为这个误差有点大。这个误差是因为错误的预测产生的,用NMS(非极大值抑制)也解决不了,所以,本文引用了一种方法:
neighbour smoothing :通过预估邻近像素点的值来增加该点预测的准确度,因为图片大都是平滑过渡的。
这样,便有效减少了预测失误的问题。
然后,是每个patch 里的密度图的生成过程:
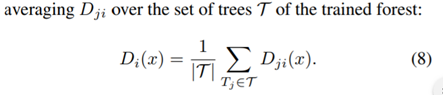
求和之后就是总的密度图了:

由上诉两个式子可以知道,采用的都是平均算法,这也一定程度上抑制了误差。
**
更具鲁棒性的模型
**
以前都是生成2种模型,分别检测高低密度,现在,我们想要基于图片整体,生成一个密度覆盖范围更广的检测器。
**该检测器有3个提升:
- increasing accuracy with a crowdedness prior —高准确度
- speeding up estimation by an effective forest reduction method —更快计数
- decreasing annotation work by semi-automatic training —省钱省力**
提升准确度:
一个概念:先验拥挤度prior—用于更加准确的预测下一个patch的密度。
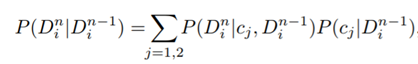
让这个式子说人话就是:当前 patch 的预测人数 与 前一个patch的人数应该是有关联的(因为现实中,相邻patch之间的人数确实变化不太),这个关联就是:当前patch 的人数应该是前一个patch在密集场景情况下和非密集场景情况下的加权和。
c1 and c2 denote the crowded and non-crowded condition.
C1 and C2可以分开训练。
做到了在不增加计算成本的情况下,提高了模型准确度。
关于随机森林的提升:
这个模型的速度,取决于用到的决策树的数量,以及采样步长(划分前的信息熵–划分后的信息熵。表示向纯度方向迈出的“步长”),数量多,步长小,速度就慢,但是准确度应该会有提升,所以,矛盾了。
解决方案: permutation of decision trees(排列组合决策树)
即减少决策树的类别数量,通过决策树的来回置换来减少森林面积。将原始森林划分为几个子森林(通常是4个),并在移动到下一个补丁时循环移动这些子森林。外表看起来森林面积不变。
每个patch的公式如下:
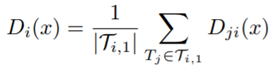
其中,T i,1是置换的第一个子森林。
半自动训练
即使到了2019,数据集也不见得那么富裕,所以2015更是活的艰苦。
该论文提出了一个方法来增大数据集,原话是这样的:synthesize training images from a large set of segmented human regions and the target scene background----合成、分割图片
这样的好处是节省了大量的人力财力,同时还创造了一些新的场景。
分割对象:PETS2009-S2 dataset which including 795 images with bounding-box annotations,
分割方式: the GrabCut method
终于写完了,,,手都打软了。。。
如果你也对人群计数感兴趣的话,不妨关注走一波?(虽然我菜,但是我积极啊),后期会继续更新相关论文。















 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









