







In this paper, we propose a trellis encoder-decoder network for crowd counting, which focuses on generating high-quality density estimation maps.
**
Contribution:
**
First, we develop a new trellis architecture that incorporates multiple decoding paths to hierarchically aggregate features at different encoding stages, which improves the representative capability of convolutional features for large variations in objects.
Second, We establish a multi-path decoder that pervasively aggregates the spatially-endowed features within a decoding feature hierarchy and progressively fuses multiscale features with dense skip connections interleaved in the hierarchy
Third, we propose a new combinatorial loss to enforce similarities in local coherence and spatial correlation between maps. By distributedly imposing this combinatorial loss on intermediate outputs, TEDnet can improve the back-propagation process and alleviate the gradient vanishing problem.
**
Architecture:
**
CNNs were originally designed for classification tasks. The resolution of feature maps is gradually degraded due to down-sampling operations, and thus, the localization precision is lowered. It is desirable to maintain a favorable balance between spatial resolution preservation and semantic feature extraction. TEDnet takes full images, rather than image patches, as the input and outputs full-resolution density maps.
As is shown in the following picture, there are four parts of the model: multiscale encoder, the multi-path decoder, and distributed supervision with combinatorial loss.

Multi-Scale Encoder:
to extract reliable features relevant to crowded human objects. The multi-scale encoding block is capable of overcoming occlusions and scale variations present in crowd counting scenes. Only use 2X2 MP(Max Pooling) and dilation to enlarge the receptive fields.

Multi-Path Decoder:
to hierarchically aggregate the spatially-preserved features and restore the spatial resolution in the density map. There are many ways to fuse them, but all are not the best.
They suffer from prolonged single-path feature transformation hierarchy with heavy parameterization, as well as insufficient feature aggregations and fusions.
Our proposed method is divided into the following two steps:
-
Decoding Block: two inputs, the right input feature is passed from the same decoding path and it possesses deeper semantic information whose channels doubles those of the left input feature.

Result of the decoded feature map is at the end of the rightmost decoding path, contains the richest spatial and semantic information. Thus, the final output density map is generated from these feature maps by restoring the spatial dimension through the up-sampling block. -
Up-sampling Block: the feature maps on the right in the hierarchy have more semantic information than the ones on the left. Those on the left, however, contain richer spatial details.
A simple single-path hourglass encoder-decoder, spatial information, although sparsely linked skip connections can alleviate inadequate feature fusion to a certain extent.
Distributed Supervision:
TEDnet computes multiple losses between intermediate density estimation maps and ground truth maps. In Figure 1, there are three destiny maps, We will compute the loss per picture.
Combinatorial Loss:
To compensate the limited MSE loss, we define a spatial abstraction loss (SAL) and a spatial correlation loss (SCL), resulting in a combinatorial loss.
SAL progressively computes the MSE losses on multiple abstraction levels between the predicted map and the ground truth.
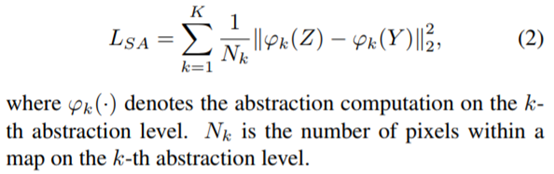
Beyond the patch-wise supervision enforced by SAL, SCL further complements the pixel-wise MSE loss with map-wise computation.

















 2289
2289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









