







1 监控指标
reference:Hologres管控台的监控指标的含义_实时数仓 Hologres(Hologres)-阿里云帮助中心
| 指标 | 注释 | 优化 |
| CPU使用率(%) | CPU使用率指实例的CPU综合使用率。 Hologres的计算资源采用预留模式,即使没有执行查询操作,后台也会存在运行的进程,此时CPU使用率不为零属于正常现象。 | 如果CPU使用率长期接近100%,表明实例的负载非常高,此时,CPU资源可能会影响系统的运行。您可以通过分析具体的业务场景,判断资源占用情况:
|
| 内存使用率(%) | 内存使用率指实例的内存综合使用率。 Hologres的内存资源采用预留模式,即使没有执行查询操作,也会有部分Meta或Index元数据加载到内存中,该类元数据用于提升计算速度。此时,在不存在查询的情况下,内存使用率可能会达到30%~40%左右,属于正常现象。 | 如果内存使用率持续升高,甚至接近100%,通常会影响系统的运行,可能会影响实例的稳定性或性能。关于该问题产生的原因、主要影响和解决方法具体如下:
|
| 实例存储用量(字节) | 实例存储用量指实例存储的数据占用逻辑磁盘的大小,是所有DB存储用量的总和。 | 如果您是使用包年包月付费模式购买实例,则存储资源的额度使用完后,超出部分会自动转为按量计费。查看表和DB的存储大小。 |
| 连接数(个) | 连接数指实例中总的SQL连接数,包括active及idle状态的JDBC或PSQL连接。 | |
| QPS(个/秒) | QPS指平均每秒执行SELECT、INSERT、UPDATE或DELETE 4种SQL语句的次数。该指标每20秒上报一次,如果20秒内仅执行了一条SQL语句,则SQL语句的QPS将在该20秒的数据点显示1/20=0.05。 | |
| Query延迟(毫秒) | Query延迟指执行SELECT、INSERT、UPDATE或DELETE 4种SQL语句的平均延迟(即响应时间)。 | 可以通过查看慢Query日志分析Query延迟,更多内容请参见慢Query日志查看与分析(Beta)。 |
2 优化指南
2.1 选择orientation行存还是列存
在Hologres中表默认为列存(column store)形式。
列存对于OLAP场景较为友好,适合各种复杂查询、数据关联、扫描、过滤、统计。
列存会默认创建更多的索引,包括对字符串类型创建bitmap索引,这些索引可以显著加速查询过滤和统计,因此列比较多的表,会占用更多的存储空间,您可以通过关闭这些默认创建的索引,释放空间。
行存对于key-value场景比较友好,适合基于primary key的点查和扫描scan。
行存默认仅对主键创建索引,仅支持主键的快速查询,因此使用的存储空间更少,但使用场景也受到限制。行列共存是同时具备了上述的能力,即支持高效点查也支持OLAP分析,但也带来了更多的存储开销,以及内部数据状态同步的开销。在行列共存中,必须有主键,其他类型的索引和列存的行为对齐。
2.2 创建表时选择合适的分布列(Distribution Key)
分布列(Distribution Key)用于将数据划分到多个Shard,划分均衡可以避免数据倾斜。多个相关的表设计为相同的Distribution Key,可以起到Local Join的加速效果。
创建表时,您可以通过如下原则选择合适的分布列:
选择JOIN查询时的连接条件列作为分布列。例如设置Distribution Key,表tmp和tmp1做Join,通过执行explain SQL语句看到执行计划中有Redistribution Motion,说明数据有重分布,没有Local Join,导致查询效率比较低。您需要重新建表并同时设置Join Key为Distribution Key,避免多表连接时数据重分布带来的额外开销。
2.3 Clustering_key设置
Clustering_key为聚簇索引,文件内聚簇索引,数据在文件内按该索引排序。对于部分范围查询,Hologres可以直接通过聚簇索引的数据有序属性进行过滤。
适用场景:
将范围查询或Filter查询列作为聚簇索引列。索引过滤具备左匹配原则,建议设置不超过2列。
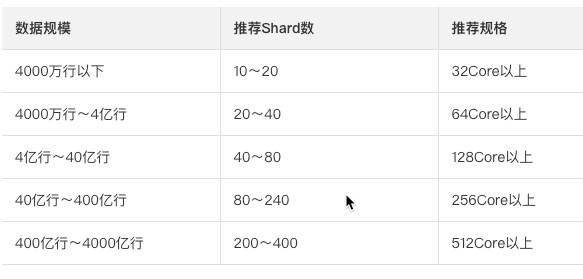
2.4 Shard_count规划
设置Table Group与Shard Count :
在Hologres中如何选定TableGroup和ShardCount_实时数仓 Hologres(Hologres)-阿里云帮助中心
Shard数多的Table Group,其数据写入和查询分析处理可以得到更大的并行度。一定范围内,增大Shard数可以加快数据写入和查询分析的速度。但Shard数也并非越多越好,更多的Shard数需要更多的节点间通信资源、计算资源以及内存资源,在资源不满足的时候,或者Query很小时可能会导致适得其反的效果。
2.5 查看执行计划 explain
有两种查看方式:
1、在holoweb中的SQL编辑器,在查询前使用explain关键字,查询执行计划。
2、在holoweb中的SQL编辑器,直接使用【执行计划】,再执行查询。
PostgreSQL: Documentation: 11: 14.1. Using EXPLAIN
3 set_table_property
set_table_property 语法来指定表的额外属性。类似其他数据库中的索引,能够起到查询加速的效果。
需要注意 set_table_property 的调 用需要 create table 在同一事务中执行,且 set_table_property 对于同一个 key 不能重复调用,下面将会来仔细介绍在 Hologres 中属性的设置以及其适用场景和使用限制。
3.1 行存列存
行存储:适合高QPS的基于主键的点查询
列存储:其他场景,尤其是多维聚合查询
-- 行存,高QPS点查
CALL set_table_property('public.test', 'orientation', 'row');
-- 列存,聚合查询
CALL set_table_property('public.test', 'orientation', 'column');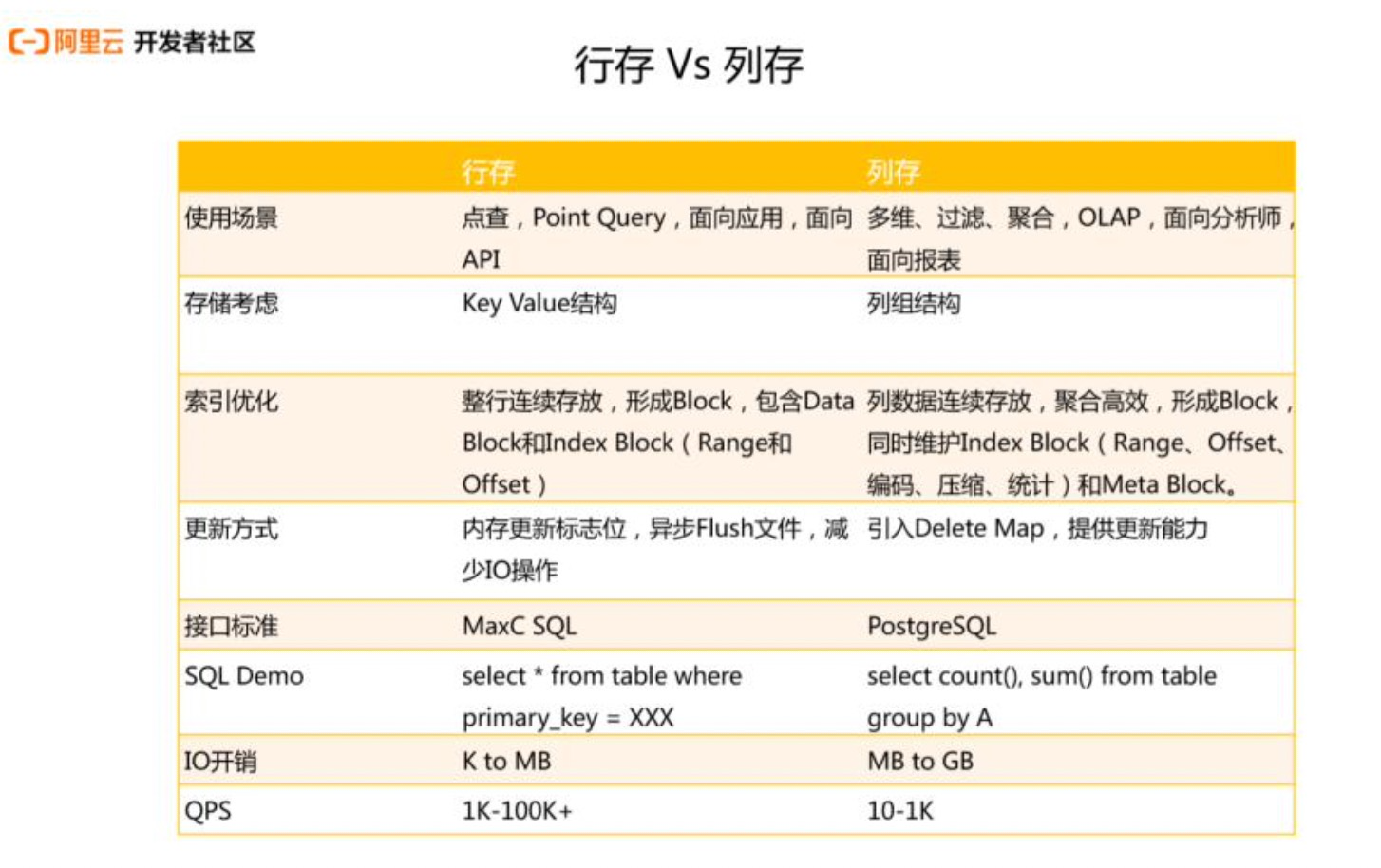
3.2 聚簇索引 Clustering Key
聚簇键类似于传统数据库中的聚簇索引。如果用户设置了 clustering key,指定一些 列作为聚簇索引,Hologres 会在指定的列上将建立聚簇索引,并且在聚簇索引上对数据进 行排序。建立聚簇索引能够加速用户在索引列上的 range 和 filter 查询。
- clustering key 创建的时候数据类型不能为 float/double
- 每个表最多只能有一个 clustering key。
-- 聚簇索引
CALL set_table_property('public.test', 'clustering_key', 'a');
-- 适合where中的range或者filter3.3 分段键 Segment key
聚簇索引主要是对数据进行排序,而分段键 Segment key 主要是用来帮助 Hologres 进行一些文件的快速筛选和跳过。用户可以通过设置 Segment key 指定一些 列(例如,时间列)作为分段键,当查询条件包含分段列时,查询可以通过 segment key 快速找到相应数据对应的存储位置。
- segment key 要求按照数据输入自增,一般只有时间类型的字段(timestamptz)适合 设置为 segment key,其他场景基本不需要设置;
- 只有列存表支持分段键设置。
PS:分段键本身的作用和聚簇索引相似,不同的是聚簇索引会进行排序以达到存储换时间的目的。对于分段键而言,其要求数据输入自增,因此是根据输入完成了排序,也能够到达存储换时间的目的。
-- 分段
CALL set_table_property('public.test', 'segment_key', 'a');3.4 比特编码列
比特编码列 bitmap columns 也是对 Hologres 性能来说非常重要的一个属性,通过 bitmap_columns 指定比特编码列,Hologres 会在这些列上构建比特编码,相当于把数据与对应的行号做一个映射。
- bitmap 可以对 segment 内部的数据进行快速过滤,因此建议把 filter 条件的数据建成 比特编码。
- 目前 Hologres 会默认所有 text 列都会被隐藏式地设置到 bitmap_columns 中。
- 但是只有列存表支持比特编码列。
PS:text列转化的原因是,text列通常是做过滤条件使用的。
疑问:like语法如何优化
-- 比特编码列
CALL set_table_property('public.test', 'bitmap_columns', 'a');3.5 字典编码列
字典编码主要是对一些字符串类型的列生成字典编码。用户通过设置 dictionary_ encoding_columns 指定字典编码列,Hologres 将为指定列的值构建字典映射。字典编 码可以将字符串的比较转成数字的比较,加速 group by 查询,因此建议用户将 group by 的字段都建成 dictionary_encoding_columns,但是不建议将基数高的列建为 dictionary_encoding_columns,会导致查询性能变差。Hologres 默认所有 text 列都 会被隐式地设置到 dictionary_encoding_columns 中,另外需要注意只有列存表支持字 典编码列。
-- 比特编码列
CALL set_table_property('public.test', 'dictionary_encoding_columns', 'a');3.6 分布键 distribution key
Hologres 是一个分布式的计算引擎,如果没有设置分布键,数据库表默认为随机分布形式,数据将被随机分配到各个 shard 上;如果用户指定了分布列,数据将按照指定列, 将数据 shuffle 到各个shard,同样的数值肯定会在同样的shard 中。
当用户以分布列做过滤条件时,Hologres 可以直接筛选出数据相关的 shard 进行扫描;当用户以分布列做 join 条件时,Hologres 不需要再次将数据 shuffle 到其他计算节点, 直接在本节点 join 本节点数据即可,可以大大提高执行效率;同时如果用户 group by 的 key 是分布列也可以减少一次数据 shuffle,对整个查询的性能带来非常大的提升。
- 对于有 pk 的表,其分布键默认就是 pk,如果不想 pk 字段作为分布键,可以指定 pk 字段的子集,但是不能随意指定。
- 可以通过 shard_count 来指定表的 shard 数,如果不指定的话每个数据库都有一个 默认的 shard 数, 一旦指定了一个表的 shard 数,其他的表如果想要和这个表做 local join,就必须指定 colcate with 这个表。下图所示是一个通过分布键设置来加速 两个表做 join 的场景。

3.7 analyze
analyze能够帮助hologres生成优化器所需信息,加快查询。对于行存数据表来说没必要必要刷新该函数。
3.8 开始日志
holo本身是一个流批一体数据库,这意味着起本身支持日志和批两种形式。按照以下DDL语句开启日志。当数据源作为输入数据流时需要开启,作为维表不需要开启。
call set_table_property('test_message_src', 'binlog.level', 'replica');--设置表属性开启Binlog功能
call set_table_property('test_message_src', 'binlog.ttl', '86400');--binlog.ttl,Binlog的TTL,单位为秒
















 5856
5856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









