






VIT
VIT也就是vision transformer的缩写。是第一种将transformer运用到计算机视觉的网络架构。其将注意力机制也第一次运用到了图片识别上面。其结构图如下(采用的是paddle公开视频的截图)
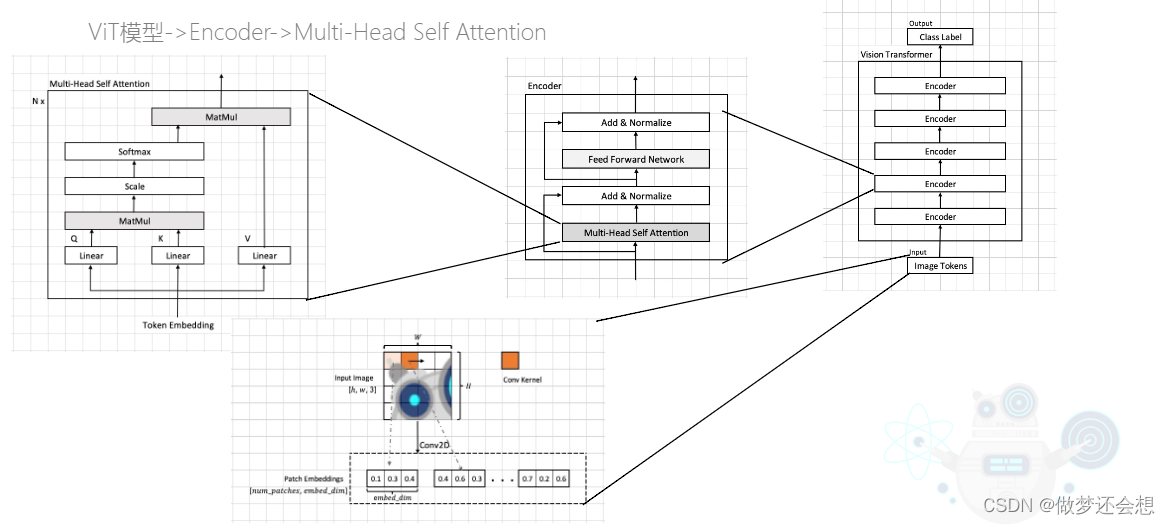
看起来比较复杂,但实际上总体流程还是比较简单的。只需要看最右边的总的结构图,它的输入被称作image token。其实也就是最左边的输入token embedding。如果非要说什么区别的话,image token是整个网络的输入,但是token embedding是每一个encoder的输入,在第一个encoder的时候二者完全一样。后面也只是在重复相同的步骤,也就是在叠加encoder。
而一个encoder的结构就是上面中间的图的结构,单独放大看看:
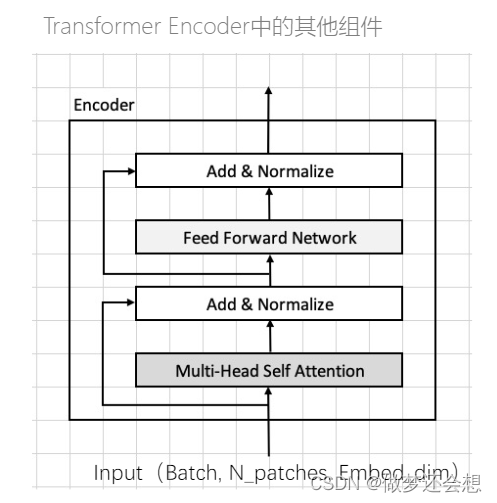
这里采用了两个残差的结构,FFN结构其实就是多层的全连接层(名字都告诉你了,前馈神经网络)。最重要的是下面的MSA结构,翻译成中文就是:多头自注意力机制。来看看这个image token是什么:
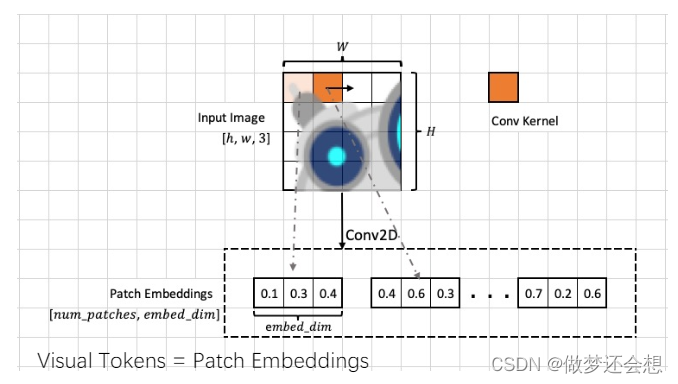
最上面的图片并不是一个像素的意思,可以理解为一个小窗口,一共有16个小窗口,最右边有一个橙色的小格子,表示卷积核的大小,那么步骤就很清晰了,我们会利用一个大小与小窗口一样的卷积核,步长就是小窗口的尺寸,对一张图进行卷积处理。卷积核的个数就是我们下面写的embed_dim(我们假设其为4)的数值。我们以上面为例,最后我们会得到一个4x4x4的特征层,然后我们使用flatten拍平以后就是一个16x4的特征层。16中的每一个就是我们准备放入encoder中的image token。
首先从输入进去看看一开始会做什么(想要更详细的教学,可以直接点下面这个链接)paddle官方视频
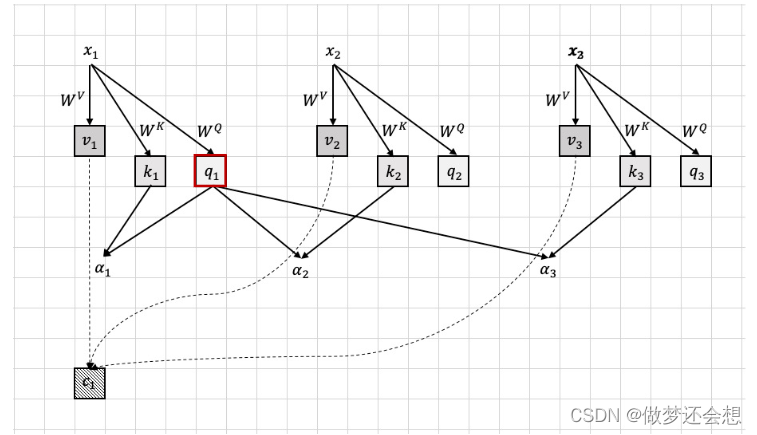
x1,x2,x3就是我们输入的image token(只举例了3个,也可以叫token embedding或者叫visual token)。那么它的原理用我们生活中的常识可以这么来解释。我们先说一下卷积神经网络是如何进行物种分类的,它实际是直接对特征进行识别,也就是卷积神经网络最基本的作用:提取图像的特征。举个例子就是,卷积神经网络判断一只狗的时候,是从它的眼睛长啥样,鼻子长啥样,这些具体的特征去判断,而这些特征之间有什么联系它不会在意,比如眼睛长啥样并不会影响它对鼻子长啥样的判断。而注意力机制,我用上面的图结合一个比喻来解释。就像我们去旅游的时候,x1,x2,x3相当于我们一共三个人组团到峨眉山去玩。(为什么是峨眉山,因为我前几天刚去了,我只能说,体验极差,但是和朋友聚一下倒是胜过旅游的目的)
Wv可以翻译成我们在旅途中的经历,因为大家的经历都一样的,所以Wv都是一样的,我们各自产生了对与峨眉山旅游一些看法,大家对峨眉山之游有了不同的体验价值v(我是v1)。并且到了那里以后有一个很罗嗦的导游Wk,它一路就向我们推荐这,推荐那的,一会儿说这个地方好,一会儿说那个地方好(在金顶有一尊玉佛像三十多万…)所以我经过它的推销以后就得到了这趟旅行需要去的几个关键地方k1(三个人都经过的一样的推荐,所以大家的Wk都是一样的,但是每个人决定的关键点地区不一样,所以大家的k都不一样)。但是我们从来不会信这群导游的鬼话,所以我们决定去美团,小红书查找资料来确定哪些景点好玩,查找的资料就是Wq,我最后从资料里面得到了对它推荐的关键点的疑问q1(其他人从攻略里面得到的每个人的建议也都不一样,毕竟感受不一样嘛)。重点来了!!我将导游给我的几个关键景点k1和我从网上得到的疑问q1结合起来,就是我对所有景点的重视程度a1(称其为注意力).然后将这个注意力结合到我对整个旅途中的期待价值v1中。最后我们在回家的高铁上谈论这一趟旅途怎么样,我说这趟旅行不太行,山上又冷,还下雨。然后x2把他这趟旅行的体验v2告诉了我,然后我就问他你觉得导游给的建议怎么样?x2说他从导游那里得到的关键信息是什么(k2),然后我说我从攻略里面(q1)早就发现这个k2里面有哪些是假的了。然后我通过k2和q1得到了x2对我说的体验v2的重视程度a2(比如导游说金顶可以看日出,然后我四点爬起来结果那天下雨看了个鬼,最后你说日出虽然没看到,但是情调不错,我觉得没看到就是没看到,不用找借口安慰自己,所以最后你对我说的你的体验v2,我肯定重视程度就没那么大),然后和v2结合起来得到了对他的体验的看法。(x3同理)。这样的话,我最后就得到了我对这趟旅游的个人看法v1•a1,我对x2对于旅游的看法v2•a2,我对x3对于旅途的看法v3•a3,我将三个结合起来,就是我对整个旅途的综合看法c1(比如我觉得x2在某些地方说得有点道理,确实有的地方还行,有的地方你简直就像在放屁).c2,c3的原理是一样的,如图。
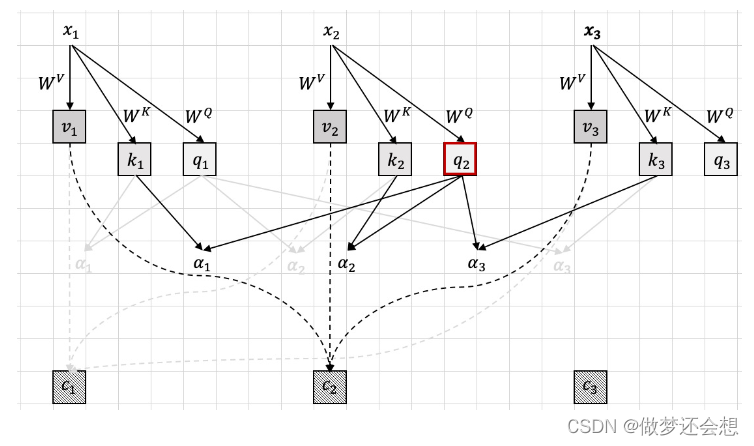
这就是注意力机制的原理。当然,最重要的就是那个权重a1,a2,a3.它实际就是我对于每个人,包括我自己,对整个旅游体验的权重(我觉得你对于这个旅途的看法挺好,和我差不多,权重就大一点,我觉得你就是个拖,我反对,那就小一点)。最后得到了每个人对于旅途的综合体验c1,c2,c3。
我们来总结一下,我们的目的是从x1得到c1,所以大致过程是这样的:
- 用Wv得到v1,v2,v3
- 将v1,v3,v3按照不同的权重结合起来,其中权重由Wk,Wq共同决定
过程就这两步,主要逻辑要搞清楚
说完原理,我们来看看是如何计算的呢?
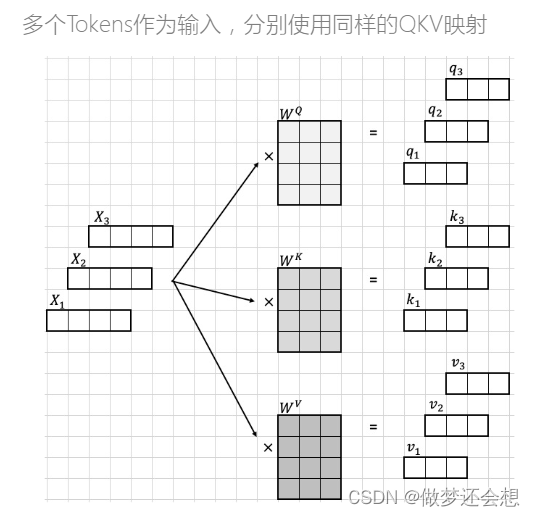
我一个x1是1x4,Wq,Wk,Wv的shape都是一样的(是可以不一样的,但是你的shape得支撑你后面的运算可以进行下去),最后得到1x3的q,k,v
其实q,k,v分别就是我们上面例子中提到的疑问(query),关键点(key),价值(value)的缩写。以c1的形成为例:
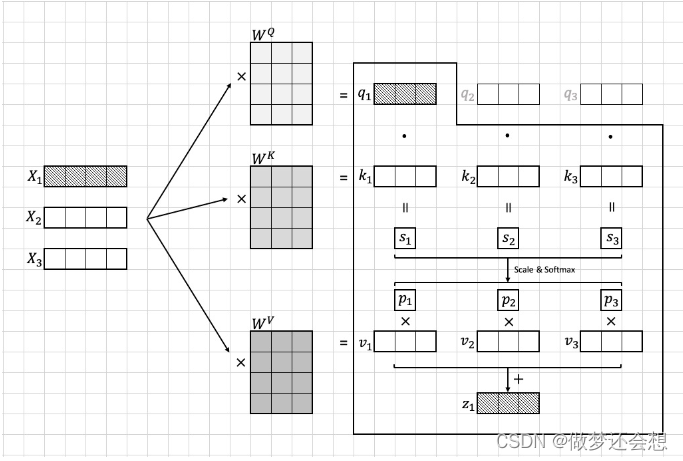
q1与k1,k2,k3组成的矩阵进行矩阵相乘。这里需要注意的是,k1,k2,k3虽然画的时候是横着的,但是计算的时候是乘的k矩阵的转置,也就是说k1,k2,k3是竖着的,q1•k1得到的是一个数,其他同理,所以下面的s矩阵是1x3的shape的。后面还经过了scale和softmax处理。这个处理我们后面说,反正不会改变形状,都是权重,所以这个p1,p2,p3就相当于我们刚才说的a1,a2,a3。然后p1就相当于一个数在乘v1(其他同理),最后得到的shape还是v1,v2,v3的shape:1x3(当然在矩阵计算的时候是肯定是p1,p2,p3组成的矩阵和v1,v2,v3组成的矩阵做乘法,这里画图是分开画的)。最后将p1 x v1,p2 x v2,p3 x v3的结果对应位置相加,就得到了一个1x3的c1(图上是z1)。这个c1就是我们例子里面的对旅途的最终综合感受。但是这里并没有结束,因为我们为了保证x1与其对应的输出c1的shape是一样的,我们需要再在最后增加一个全连接层进行维度的统一,也就是对于上面的例子,还有一个Wout的shape为3x4.到这里整个注意力机制里面计算步骤就结束了。
这里有一个扩展思考的题目,也是我自己揣摩出来的,想通的话对整个网络的理解会进一大步:z1的shape是固定不变的吗?
解决这个问题,我们先看看z1是如何得到的。它是由各个v经过各自权重的相乘,然后对应位置相加得到的,是x1的综合感受。那么z1的shape就是由v1来决定的,而v1的shape则是由Wv决定的,所以只要Wv的列数改变,最后的z1的shape就会发生改变,所以我们得出结论,z1的shape并不是固定,我们可以根据改变Wv的列数来自由定义z1的长度。当然,在标准的源码里面,多头注意力机制的Wv,Wk,Wq的shape都是一样的。
下面我们看看scale和softmax是什么:

其实softmax肯定都是知道的,归一化嘛。但是在归一化之前要除以一个根号下dk。这个dk是上面q1或者k1里面的元素的个数,在上面的例子里面就是3。大家都是经过的归一化,最后的值都在01之间,有什么区别吗?它实际是解决了一个方差的问题。在右上角的例子里面我们可以看到,同一组值,前者没除,后者除了,虽然二者的值都在01之间,但是上面分别对每一组结果中的三个值求它们仨的方差var,前者高达30000,后者只有0,03,基本为0.也就是说后者数据的波动几乎没有,这使得我们的数据更加平滑,一定程度上会防止梯度爆炸。在注意力机制里面还有一种解释,那就是为经过除法的数据太过于极端,也就是注意力对与我们不感兴趣的对象的权重过于极端,我们还是希望多多少少关注一点的。而重视的对象也不要太重视,是不是有点像防止过拟合的手段,没错,原理差不多,所以利用这个除法就可以将过于重视和过于不重视的情况都往中间拉一点(也就是都往均值上拉一点,方差不就变小了嘛)。
好了,到目前位置,我们就说完了单头注意力机制的原理,以及计算流程。接下来看看什么加多头注意力机制呢?(吃个饭,吃个饭,最后说一句,峨眉山旅游是真的坑)
一句话总结多头,就是同时有很多组Wq,Wk,Wv(而不是我们上面说的一组)同时算它们自己的综合感受。如图:
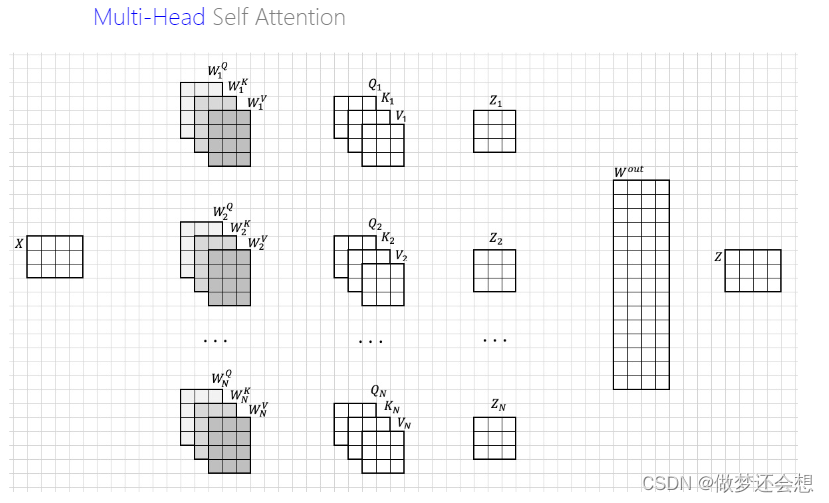
我们先看最上面的一组。我们通过一组的Wq,Wk,Wv,就跟我们刚才说的步骤是一样。最后得到一个3x3的z矩阵,每一行就是就是x1,x2,x3的综合感受,然后一共有N组。然后将这些结果横着拼起来,那么shape就是[3,(Nx3)],然后经过一个[(Nx3),4]的Wout,既可以将各个头的综合感受进行融合,还可以改变输出的shape使得其与输入一样,均为[3,4]。
那么多头注意力机制比单头好在哪里呢?答:最主要的作用是防止过拟合
说白了,它就是根据不同组的Wq,Wk,Wv来计算不同方向的注意力综合,使其不至于在一个方向上过度学习。那么多头注意力机制既然增加了组数,那么计算量是否是增加呢?答:在源码里面不会。举一个例子,如果是单头注意力,那么Wq,Wk,Wv都是[4,20]的,如果设置成多头,假设有4个头,那么就会平分单头时的Wq,Wk,Wv的宽,每一个头的Wq,Wk,Wv的shape就是[4,5].所以尽管你的头变多了,但是你Wq,Wk,Wv的尺寸变小了,所以并不会增加计算量,至少在源码里面是这样。当然你可以自己设置这三个矩阵的维度,来改变计算量都是可以的。
最后当我们输出的时候,shape和输入的shape是一样的。所以可以encoder之间可以无限叠加。
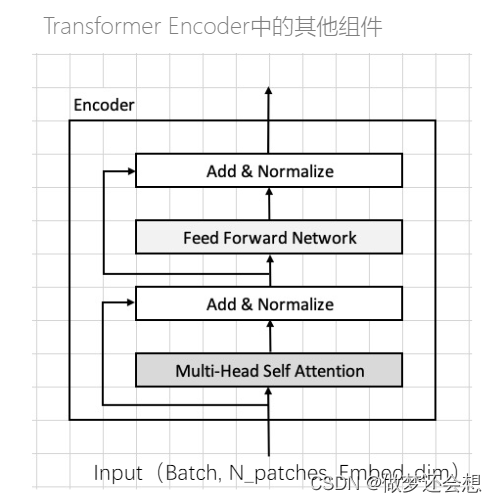
以上是我们MSA的内容。然后我们会经过一个残差网络,不改变大小,之后进入前馈神经网络,一般是第一个全连接层把维度放大多少倍,然后第二个全连接层又缩小回来,所以大小还是不变,之后又经过一个残差网络,最后输出。这就是一个encoder的流程。然后:
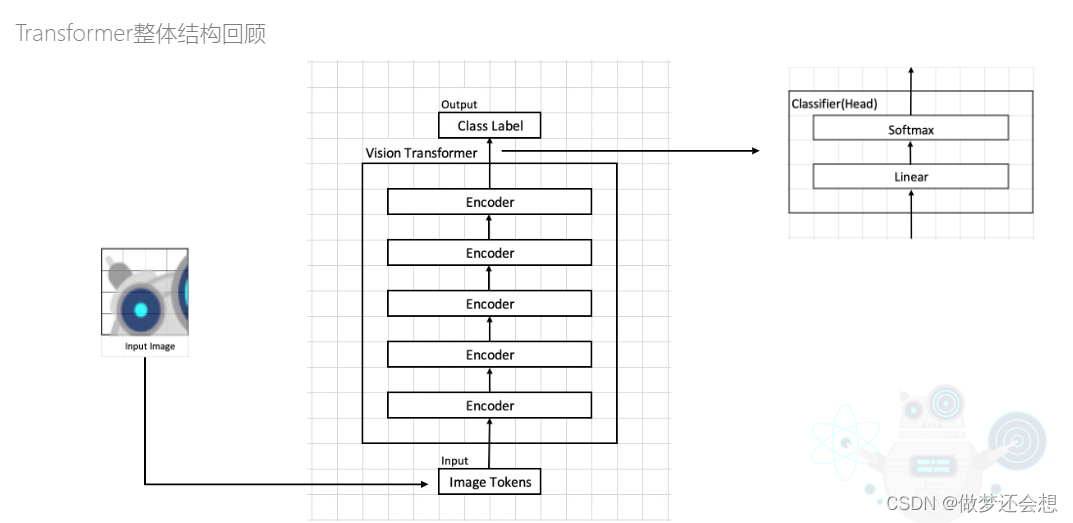
然后经过五个encoder的叠加,在最后的输出上面接上分类层就可以进行物体分类的。但是在源码上面还做了一些改变和改进,如图
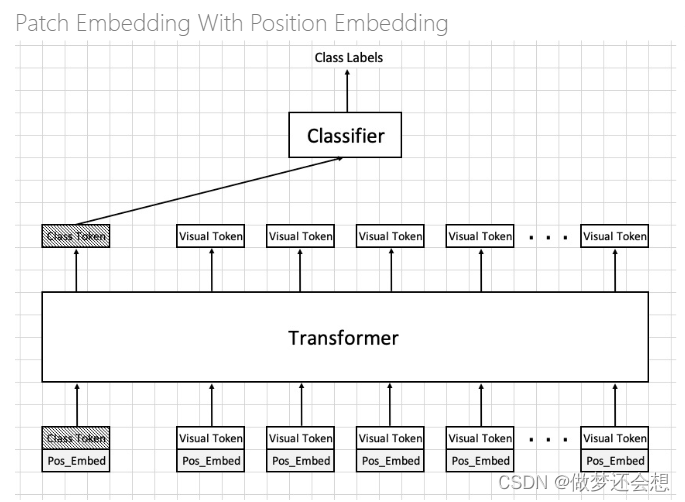
有两点不同,第一,增加了一个Class Token,其shape与一个Visual Token是一样的。第二,每一个token下面加了一个Pos_Embed,翻译过来就是位置编码。它的目的是为了给输入进去的各个token提供各自的位置信息,毕竟我们的visual token实际上就是图片的每一块的特征。我们需要告诉网络,诸如鼻子就应该在眼睛的下边,嘴一定在鼻子的下边这种信息。那么改变的两部分对识别的结果有什么影响吗。在论文里面可以发现:
- 需不需要一个专门的class token进行分类无关紧要,区别不大
- 加不加位置编码区别很大,增加了位置编码后的网络准度提升了百分之5
由于位置编码,从最初的transformer到VIT再到swin transformer,再到DETR都不一样,所以我们遇到一个网络就去讲一个它的位置编码。
要弄懂每一个网络的位置编码的原理,比如弄明白两个问题:
- 位置编码是干什么用的(刚才已经解释过了,不同的网络的位置编码样式可能不一样,但是作用都是一样的)
- 位置编码加在哪里?(大部分的网络加在同一个位置,如transformer,VIT和DETR,少部分加在比较特殊的地方,如swin transformer)
VIT的位置编码应该是所有位置编码里面最简单最省事儿的。VIT的位置编码被称作:一维绝对可训练位置编码(1d & absolute & trainable)。
加在哪?答:加在输入的每一个visual token的每一个元素上面。例如经过backbone网络得到的特征图的shape为[2,256,24,24],那么我们的位置编码就是[256,24,24],准确得来说是[256,24x24],因为需要将visual token经过flatten,并且由于不同的图片使用的位置编码是一样的,所以只需要repeat一下就可以了。那么它们是多少呢?我不知道,因为是可以训练的,你可以给它们一个初始值,就当作网络的parameter参与训练,训练成多少算多少。那能不能直接给它们一个固定的值呢?是可以的,在传统的transformer,swin transformer还有DETR当中都是加入的固定值。那么训练还是固定值有影响吗?答:论文指出,二者几乎没有区别,所以为了减少计算量,大部分的transforemer系列的网络都是采用的固定值。我写了一个简易的VIT的位置编码的代码供各位参考:
import torch
import torch.nn as nn
import torch.nn.init as init
def trainabel_embeding(positon_index,embed_dim):
position_embeding=nn.Embedding(torch.numel(positon_index),embed_dim)
'''
nn.Embedding(a,b)就是生成一个a行b列的随机数数组,它一般是用来做编码的,最早用在NLP
当中,a表示一个词库里面的单词总量,b表示你需要多少个维度来表示一个单词,最终的[a,b]的
tensor就体现出了一个单词被b个元素所编码的结果。当出现nn.Embedding的时候,就代表里面的权重
是可以训练的,也就是说这个位置编码是可训练的。所以我们调取其中编码的具体值的时候要用
position_embedding.weight
torch.numel(a)表示获取a这个tensor中中元素的总个数
'''
nn.init.constant(position_embeding.weight,0)
#将位置编码初始化为0
return position_embeding
position_index=torch.arange(16,dtype=torch.float)
#我们假设特征点一共只有10个,也就是一共有16个visual token,也就是说我们的特征图是4x4的,经过了压平
position_embedding=trainabel_embeding(position_index,20)
#再假设我们的特征层的深度为20,它有一个专业的术语叫做embed dim
print(position_embedding.weight)
最后得到的结果为:
Parameter containing:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]],
requires_grad=True)
torch.Size([16, 20])
到目前为止,VIT的所有原理与计算还有一些环节的代码解释就已经阐述完毕了,欢迎各位指正。
Swin Transformer
swin transformer的出现是为了解决传统的VIT对局部注意力关注度不够的问题,说人话就是,从VIT对整体的注意力的计算升级成了对图片分块后再进行小块的注意力计算。它的整体结构图如下:
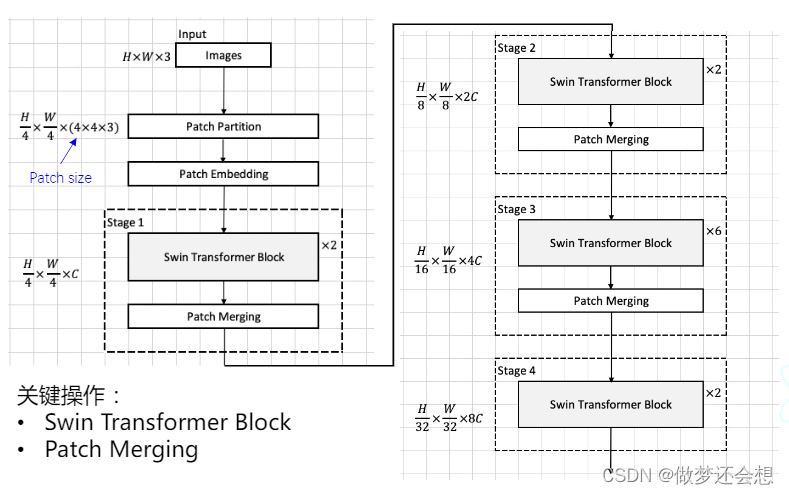
图片依然会先进行特征提取,也就是上图中的patch partition和 patch embedding部分。左边的shape之所以有一个除以4,是因为原图的尺寸为H和W,经过backbone提取特征以后尺寸变为原来的四分之一,后面4x4x3是经过patch的大小,它和Patch Partition是共同作用的,我之前说这俩部分其实就是卷积的过程,严格地来说并不是。它的Patch Partition和Patch Embedding是两个步骤,第一步,先将一幅图片进行分块,也就是Patch Partition。第二步,将分块后的图片进行编码,也就是经过一个全连接层进行映射。我们用一段简单的代码演示一下就懂了:
def image2emb_naive(image,patch_size,weight):
'''
:param image: [3,h,w]
:param patch_size:一个patch的尺寸,设置为4,表示一个patch里面有田字形的四个像素,之后会转化为特征
:param weight: 这是将patch里面的像素个数全部flatten以后进行映射的全连接层中的关系矩阵,其shape[patch_size*patch_size*3,embed_dim]
:return:
'''
#这里可以直接使用nn.functional.unfold接口来一键进行分割
patch=F.unfold(image,kernel_size=patch_size,stride=patch_size)
#它的作用实际上就是利用窗口滑动的形式进行切割,最后返回的patch的shape为[b,48,num_patch]
#从shape可以看出来,它实际已经做了一个flatten的操作,一个batch的depth就是4*4*3=48
patch=patch.transpose(2,1)#patch的transpose似乎只允许输入两个维度的值,[b,num_patch,48]
patch_embedding=patch @ weight#@表示矩阵乘法,*表示对应位置相乘
return patch_embedding
image=torch.randn(4,3,224,224)
patch_size=4
channel=3
embed_dim=96
num_patch=3136
weight=torch.randn(patch_size*patch_size*channel,embed_dim)
patch_embedding=image2emb_naive(image,patch_size,weight)
print(patch_embedding.shape)
输出为[3,3136,96]
从上面简易的代码可以总结出来它的流程步骤:
- 对一组图片进行窗口的切割,由[4,3,224,224]按照4x4的小窗口,步长也为4,分成了56x56个小窗口。同时每一个小窗口一共有4x4x3=48个像素(这就是那个4x4x3的由来),将一个窗口的4x4x3个像素打平成一维,然后整体输出,也就是我们函数中patch的shape为[4,48,3136]
- 然后转置为[4,3136,48],这两步可以叫做Patch Partition
- 然后进行映射,其实就是矩阵乘法,原理和全连接层是一样的,[4,3136,48]的tensor@一个[48,96]的tensor,结果就是[4,3136,96],这一步叫做Patch Embedding
从流程中可以清晰看到,它的两步操作,其实完全可以用卷积来代替,使用给一个4x4尺寸的卷积,然后卷积数量设置为96,也就是embed dim,最后的结果是一样的,所以,我们卷积的代码也可以写出来了:
def image2emd_conv(image,kernel,stride):
conv_output = F.conv2d(image, weight=kernel, stride=stride) # shape[b,embed_dim,embed_h,embed_w]
# 在卷积完成以后,我们希望把每一个patch的排成一行,之后,也就是把上面的2,3维的矩阵形状改为一行的
b, embed_dim, embed_h, embed_w = conv_output.shape
patch_embedding = conv_output.reshape((b, embed_dim, embed_h * embed_w))
# 为了满足后面进入transformer的形式,我们需要把shape定义为(b,num_patch,embed_dim)的形式
patch_embedding = patch_embedding.transpose(2, 1) # [b,num_patch,embed_dim]
return patch_embedding
kernel=weight.transpose(1,0).reshape(-1,channel,patch_size,patch_size)
patch_embedding_conv=image2emd_conv(image,kernel,patch_size)
print(patch_embedding_conv.shape)#[4,3136,96]
然后我们进入到stage1中
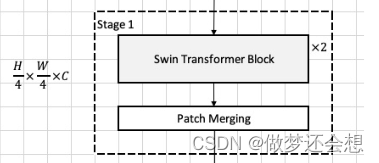
左边规定了一个shape[H/4,W/4,C],它的shape实际是Swin Transformer Block的输出也好,输入也好,的shape,也就是说Swin Transformer Block不会改变输入的shape。改变shape的是下面的Patch Merging操作。还有一点需要注意的是,Swin Transformer Block x2并不代表是两个相同的结构,这两个Block的最底层原理类似,但是区别非常大,如图:
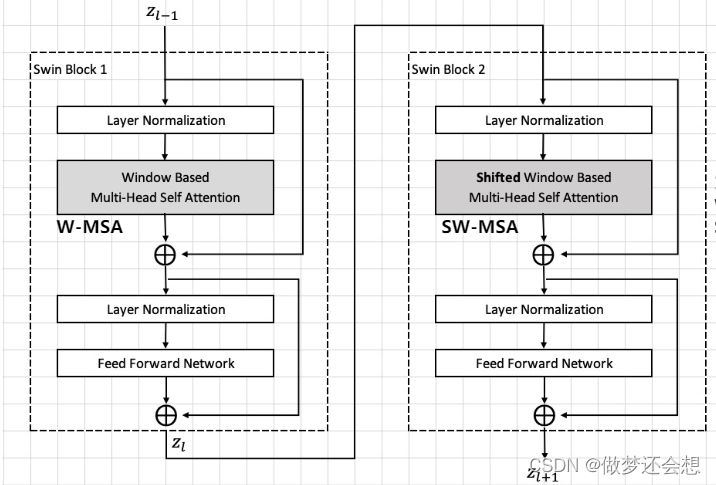
它的结构和我们在VIT中遇到的encoder的结构非常相似,变化只有暗色调的MSA加了个window和 shifted window。其原理结构图如下:
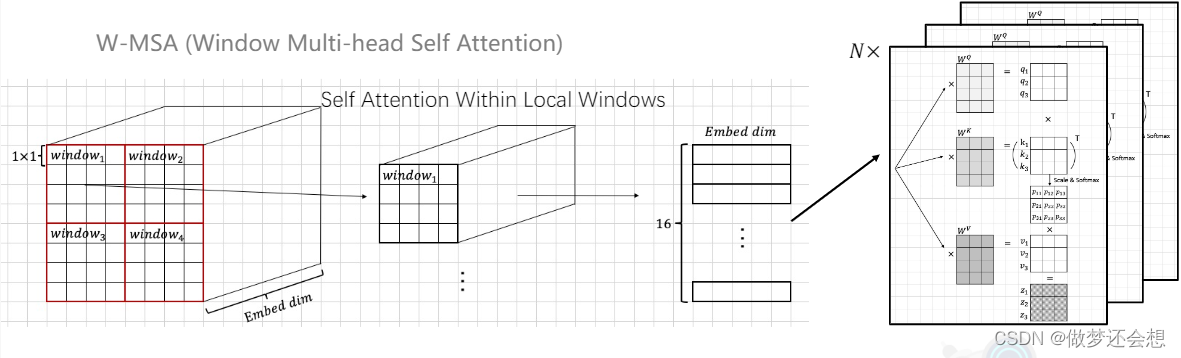
它总的步骤可以分为两大步,第一步对feature map进行窗口分割。第二步就是对每一个窗口进行自注意力机制的计算。
我用一个简单的函数来进一步看看这个窗口是如何进行分割的,说实话,有点不好理解:
window_size=7
def window_partition(patch_embedding,window_size):
#输入进入的patch embedding的shape为[5,96,56,56],先把维度放在最后,但是torch的转置只能两个维度之间进行,所以需要复杂一点
patch_embedding=patch_embedding.reshape(batch,embed_dim,h_embedding*w_embedding)#[5,96,3136]
patch_embedding=patch_embedding.transpose(2,1).reshape(batch,h_embedding,w_embedding,embed_dim)#[5,56,56,96]
#然后直接利用reshape,将宽高均分为8x7份,但此时并不是我们想要的结构,因为这里的8x7份并不是田字形的,而是一字型的,所以还需要转置
window_embedding=patch_embedding.reshape(batch,h_embedding//window_size,window_size,w_embedding//window_size,window_size,embed_dim)
window_embedding=window_embedding.transpose(2,3)
'''
这里可以直接使用unfold函数,就像一开始的生成patch的步骤一样,这样可以直接圈一个田字形的window,而省略掉reshape后再transpose
'''
return window_embedding#[5,8,8,7,7,96]
看着比较复杂,但是有效代码就那么几行,参数名字比较长而已。
输入的参数patch embedding其实就是我们经过卷积后得到的feature map,window size设置的是
其处理步骤如下:(这里我改了一下上一个示例里面的batch,一开始为4,现在是5,是为了防止后面相同维度的混乱)
- 输入进来的feature map的shape为[5,96,56,56],经过转置和reshape改变成为[5,56,56,96]
- 然后对第1,2维度进行reshape成[5,8,7,8,7,96],这里为什么不直接转[5,8,8,7,7,96],理由如下:
'''
首先reshape的原理是把原有数据全部按顺序打成一排,然后按照reshape的大小再按顺序装填,所以如果只看56x56这两个维度
那么可以这么来表示它们存放的格式:
[[1 ,2 ,3 ,4, .....55 56],
[57,58,59,60,.....111,112],
.... ],
[3080,...............3136]]
我们是目的是把1234567与下面的57,58,59...还有更下面的,更更下面...的7个数放在一起。也就是我们想要用一个7x7的窗口
,按照窗口的位置大小进行数字的集合,而不是顺序。所以我们直接reshape成[8,8,7,7]那么第一个窗口实际上的数字是1到49.
所以我们先把每一行先进行切分,从56,变成了8个7,也就是[8,7]。将1234567放一块,891011121314放一块,依此类推。
那么下一行也是同样的操作,[57,58,59,60,61,62,63]放一块,以此类推
'''
- 对2,3维度进行转置,成[5,8,8,7,7,96],就可以完成我们的目的,将1234567,57,58,59…等等放一块了,其实理由很简单,我们只变了78到87,想简单一点就是7行8列变成了8行7列,里面的元素是如何变化的呢?由于是转置,所以第二行第一列变到了第一行第二列,那这个原来的第二行第一列是谁呢?不就是[57,58,59,60,61,62,63]么,转到第一行第二列以后,不就和[1,2,3,4,5,6,7]放在同一个[ ]里面了么
如果还是听不懂可以根绝我的解释画一个图来理解(我apple pencil今天没带…)。退一万步讲,如果还是听不懂,可以像我在代码里面的注释一样,直接使用unfold函数,它本来就是窗口的处理,自己就把1234567和56,57…放一块处理了。笨办法和聪明办法都说了。
处理完窗口以后,我们会进入到窗口的自注意力网络的搭建当中。为了节约时间,而且我也觉得直接贴代码不是很负责,swin tranformer的源码拿出来讲解就偏离主题了,所以我尽量用文字叙述步骤,我会贴上每一步结束的输出的shape,这样理解起来就事半功倍了。有的部分的代码我跳不过去了,就会用一个我自己写的简易版的代码来代替讲解。如果理解了上文我们说的VIT的原理,这里应该是基本没有难度的
- 首先它用了一个类来完成窗口注意力机制的计算,我们取名叫WindowAttention,简称WA(哇).
- 它规定了如下几个超参数,①dim也就是embed dim为96,也就是我们特征层的深度,窗口并不改变它。②一共采用四个头num_head=4③每个头所用的Wq,Wk,Wv的宽dim_head就是96/4=24⑤将方差贴近于0的scale=dim_head^(-0.5)
- 接下来是它的计算步骤,这个类创建完对象以后的输入的shape为[320,49,96],这个320就是8x8x5的结果,由于每一个window是独立计算的,所以干脆就把batch里面每张图的window都进行平级的处理,就把320当作新的batch就行了。
- 用Linear层创建Wq,Wk,Wv矩阵,然后输入经过三个矩阵得到q,k,v,它们的shape均为[320,4,49,24],320是batch,4是头数,49和24是H和W。
- 利用矩阵乘法来计算注意力权重attn。q和k的shape均为[320,4,49,24],所以只需要q矩阵乘k的转置(这个转置我们在VIT的时候说过还记得吗),也就是[320,4,49,24]@[320,4,24,49],所以attn的shape为[320,4,49,49],这个shape其实很好理解,一个窗口是7x7,一共有49个特征点,也就是49个patch,一个patch有对所有patch的49的注意力权重,所以一共有49x49个注意力权重,一共有4个头坐着一样的事,又一共有320个batch做着一样的事,所以形状如上。
- 对这个注意力权重进行scale处理和softmax处理,形状未变
- 之后将attn与v进行矩阵乘法[320,4,49,49]@[320,4,49,24]得到综合注意力z,其shape为[320,4,49,24]这个shape的解释就是每一个窗口的49个patch的综合注意力都是由一个24个元素的tensor来表示的。
- 转置并reshape成[320,49,96],之后经过一个全连接层进行几个头的融合以及使得维度与输入一样,最后输出的shape为[320,49,96]。这里维度明明没有变,那么这个全连接层是否还有必要呢?答:很有必要,不光起到几个头特征融合的作用,保持shape不变是最重要的,这里没有改变只是因为一开始的embed dim96除以头数4,刚好除得尽。如果头数设置得比较怪,如果是5,那么每个头的dim就必须重新设置,或者四舍,或者五入,比如可以取25,这样算到最后的时候的shape就是[320,49,100],这个时候就需要一个全连接层进行维度的变化使得输入前后保持一致。
- 在进行完上图中的W-MSA以后,我们需要进行一个残差的融合,但是目前的shape不符合规范,所以需要进行处理,我们的终极目标是使其shape变为[5,3136,96]我这里只写shape的变化过程
- [320,49,96]reshape成[320,7,7,96]
- 再reshape成[5,8,8,7,7,96]
- 再转置为[5,8,7,8,7,96]
- 最后reshape成[5,3136,96],可以看到它完全就是我们之前窗口切割的笨办法的逆过程,如果之前使用的unfold函数,那么现在倒推回去还是要捋一遍笨办法的思路。
- 最后的最后,就是进行残差啊,全连接层啊之类的简单运算。整个swin block1就全部完成了。
所以我们要知道的是,输入进去是一个[5,3136,96],输出以后还是[5,3136,96]
swin block2的出现主要是为了解决相邻的窗口之间在swin block1中完全没有联系的问题。因为窗口毕竟是统一的,很有可能窗口将同一个部分分到了多个窗口,而这些窗口之间在block1当中是完全独立的。具体操作流程图如下:
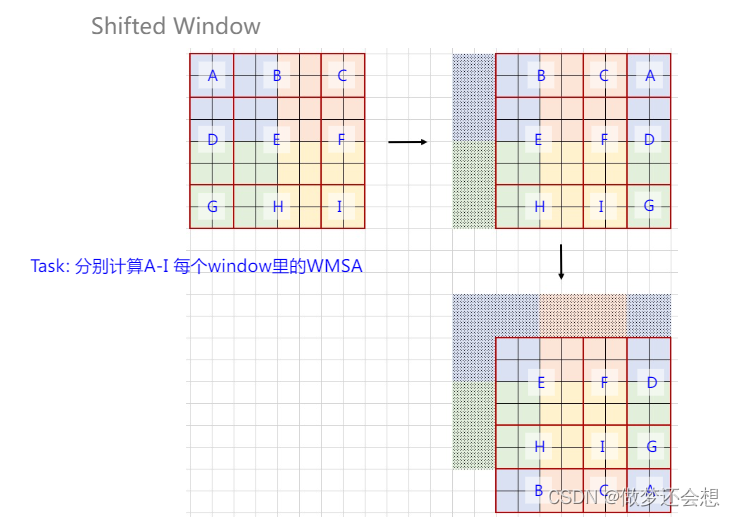
第一张图可以先假设它就是整个feature map,也就是8x8的尺寸。不同的颜色代表不同的窗口,现在这个窗口是4x4的,一共4个窗口。然后按照窗口大小的一半(也就是2)进行区域的重分,相如图这样划成了A到I一共9个区域。
第二张图利用循环填充的方法将原图右移窗口一半的大小,移出去的ADG部分填充到右边就形成了图2
第三张图利用相同的原理下移窗口一一半的大小,然后把移出去的BCA重新填充回下方,就有了我们最终的区域重构。
为什么要移动窗口尺寸的一半?
首先我们这个特征图举例得比较小,如果按照我们刚才得到的56x56的特征图尺寸,利用7x7的window来进行各自的自注意力计算的话。将56x56向左,向下平移3个(7/2向下取整)单位,然后再在循环填充过的56x56上使用7x7的window,这样大部分的window都是像上图示意图中的E区域一样,不光包含了原来的4个window的部分,还不需要mask(下面会讲)
它原理说白了很简单,我们既然缺少窗口之间的联系,那我就把图片向左上方移一定的距离,右下方循环补齐。这样的话,我再用相同大小的window来按照之前的方式划分区域,这一个window里面包含的内容不就是之前多个window里面的部分内容拼起来的嘛。就想上图最后一张图的布局一样,第一个window是E,包含了4个原window的内容,第二个window是FD,也包含了4个原window的内容,HB,IGCA,都包含了4个原window内容。
但是呢?如果我们就按照移动后的布局进行window的自注意计算,回顾一下注意力机制的基本原理,我实际上是在求window里面每一个特征点对所有特征点的一种综合体验。我们还是举旅游的例子,如果有第四个人,他压根儿就没去峨眉山,那么它的关键点和疑问对于我们三人有参考价值吗?完全没有。
放在我们上图来说就是,最后一张图以第二个window中的特征点为例,FD两个区域放在一起,要求里面所有特征点之间的综合体验,但是,F区域中的特征点和D中的特征点在原图中根本就没有相邻,它们之间的联系本来就基本趋于0,甚至就是0,我们当然就没必要求F与D之间特征点彼此的注意力attn。所以进一步引入了SW-MSA MASK的概念,简称mask。作用就是在计算attn完毕以后,在mask对应的位置上使得没有关系的特征点上的attn趋于0或负无穷(因为会softmax)
我们先来看看一个窗口内的attn是如何做到屏蔽的,依然以FD这个窗口为例:
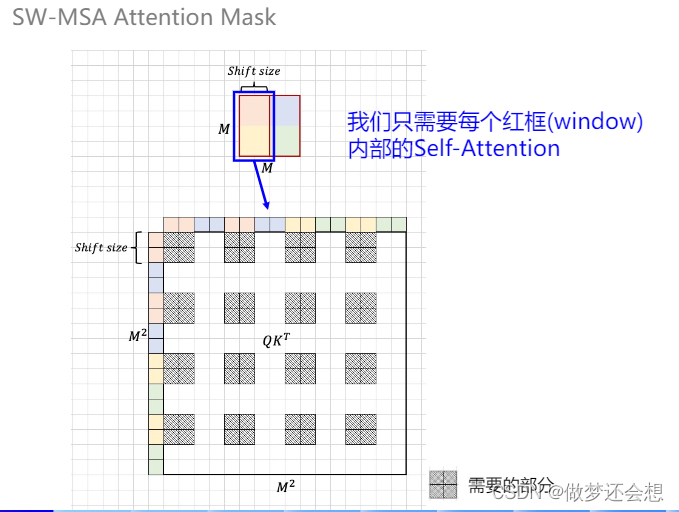
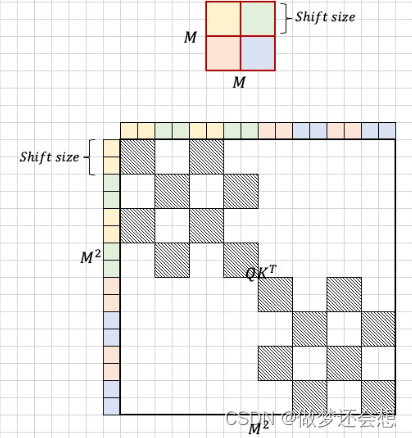
这个框的shape是4x4,一共有16个特征点,那么计算出来的attn在最后两位维度上就是[16,16]
是不是就像上面这个M^2这个图,第一行表示的第一个特征点对所有16个特征点的注意力权重,但是第一个特征点属于红色区域,它只和红色,黄色区域的attn是有效的,所以在有效的attn的地方已经用虚线表示了。所以针对这个[16,16]的attn,我对应的mask的shape也应该是[16,16],然后在虚线部分为0,白色部分为一非常小的数,可以是负数,然后二者相加,这样softmax以后这个很小的数就为0了,而相关地方的attn不会发生改变。最终达到屏蔽的效果。上图中的shitf size就是向右移动和向下移动的的尺寸,也就是我们上面所说的window size的一半蓝色和绿色的attn屏蔽图类似:
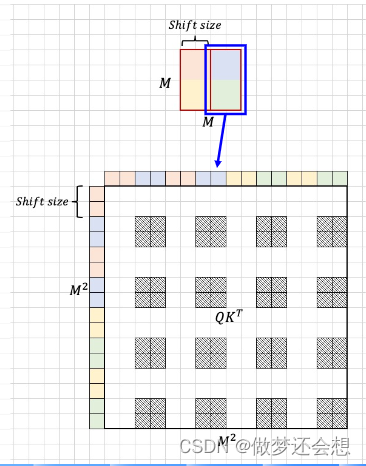
最终两个图加在一块,就成了这个window的终极屏蔽图
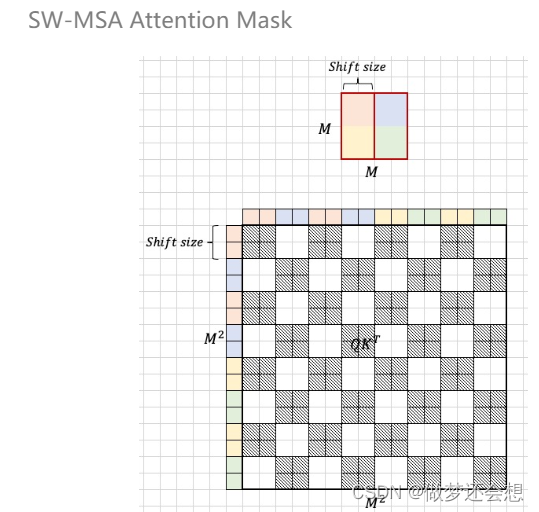
所以这个mask的[16,16]里面,只要阴影处为0,白色处为负很大,那么加在原来的attn上面就能达到attn屏蔽的效果。
同理,我们可以得出HB区域的attn屏蔽示意图:
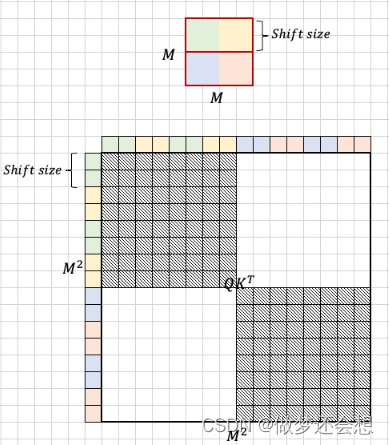
IGCA的屏蔽示意图:
所以我们对于WS-MSA的attn的计算公式为:
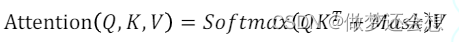
之后就可以按照正常的流程去求综合感受,最后还有一步就是把shift过后的feature map再shift返回原来的样子,因为不能改变图片的特征。
之后是一个比较重要的环节,我当时一直在想这个板块放在哪里说明更好,最后决定在MS-MSA阐述完毕以后再说明,这个东西就是位置编码。之前我们提过一嘴,除了swin transformer以外,其他的transformer结构的位置编码都是加在输入上面**(这个输入其实说得不太准确,因为之前讲的VIT只在整个transformer结构的第一个encoder的输入处加上位置编码,但是在DETR里面,位置编码加在的“输入”可太多了)**。swin tranformer的位置编码是加在attn上面的,并且每一个block1,block2的注意力计算模块(MSA,WS-MAS)上面都会加。它的专业名词叫做relative position bias,也就是相对位置偏移。我们用一个3x3的window size来举例(再大的话示意图就太大了)。
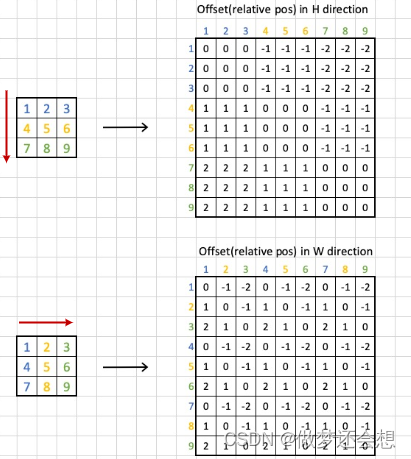
先看上半部分,我们以纵坐标为例,第一行表示1处特征点相对于所有9个特征点的相对纵坐标(比如1的纵坐标是1,你要说是0也行,然后9的纵坐标为3,所以相对纵坐标为-2,你要用3-1也行,但是后面的标准你得都统一,只不过咱们取的参考系不一样)。依此类推,就有了右上的图片。相对横坐标同理,也就有了右下的图片。二者结合一下就有了总体的相对坐标的示意图:
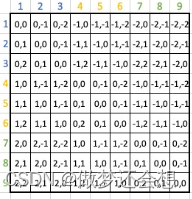
(这个水印好像去不掉…不过这些都是我在上面发的连接里面的课件的截图,大家如果要用可以自己去看看)
一共有81个相对坐标,但是只有25种,也就是说有一些相对坐标是重复的。25的计算公式是:(2*window_size-1)^2,也就是5的平方。然后我们对不同的相对位置进行编号:
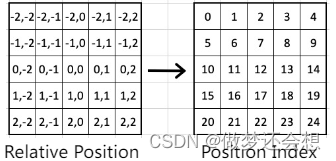
需要注意的是,左边的相对位置的顺序无关紧要,我们相当于用不同的0到24的数字来表示25个不同的相对位置。所以这个相对位置具体是多少并不是我们关心的重点,我们只关心相对位置的差别以及是否是一样的。将这个编号替换到9x9的相对位置图中:
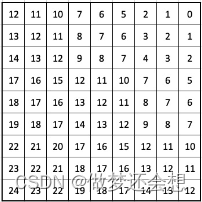
但是这个0到25并不是位置编码,我们会生成一个5x5,或者就是shape为[25,]的可学习的参数。然后根据这个编码索引从里面去取值,再加到attn上面。所以attn的位置编码实际是一种二维相对可学习的位置编码。这里有一个大的示意图:
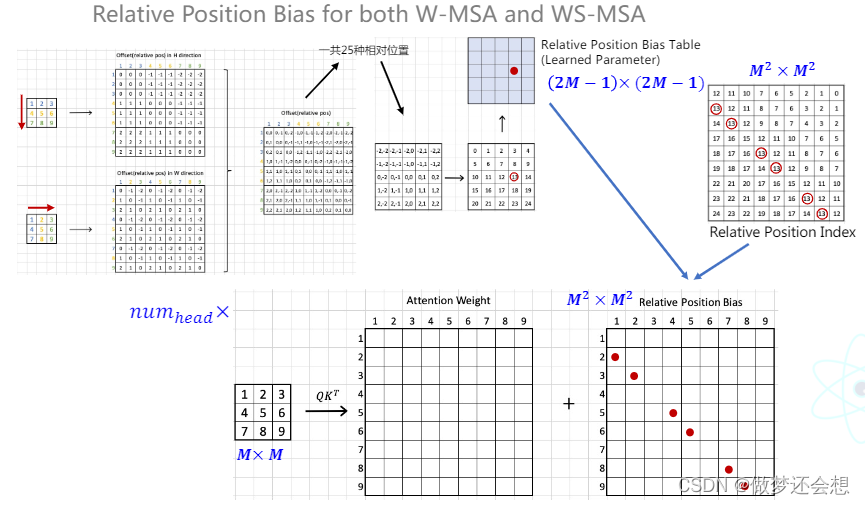
当我们生成一个上图中间的那个5x5的索引矩阵以后,进一步就有了一个9x9的相对位置索引矩阵和一个5x5的可学习的bias参数。这个9x9的相对位置索引矩阵和我们得到的9x9的attn矩阵其实是一一对应的。我们假设现在需要在相对位置为13的attn处加上bias,我们就先去蓝色矩阵里面找到位置为13的那个bias,然后全部加到attn矩阵中9x9相对矩阵中为13的相同位置上就可以了。
然后是最后一个环节,也就是我们在最开始流程图里面说的改变形状的patch merging。merging的本意就是合并的意思,所以我们的原理就是通过合并来减少输入的shape。来看看patch merging的流程图:
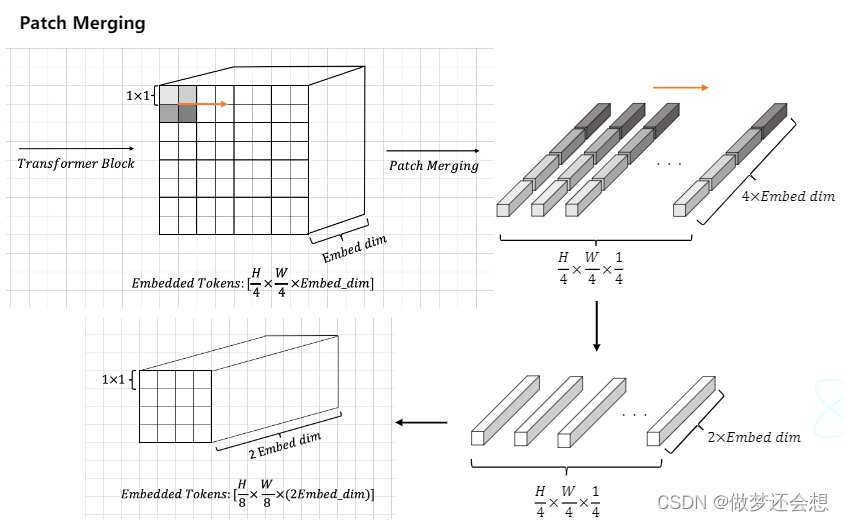
第一个长方体表示的是总体流程图中stage1中的两个block后的输出。我们假设其shape为[56,56,96],我们按照田字格的形状抽出来4个patch,然后拍成一排,一次规则,将所有的patch排成一排。一共就有56x56/4=784排,每一排的dim为96x4=384.也就是第二张图。然后利用全连接层将降维降到一半,也就是192,也就是第三张图。最后把784排重新组合以原来宽高的一半重新叠成长方体,也就是最后的shape为[28,28,192],就完成了尺寸减半,深度加倍的工作。是不是很简单。
重新来看一下总体流程图
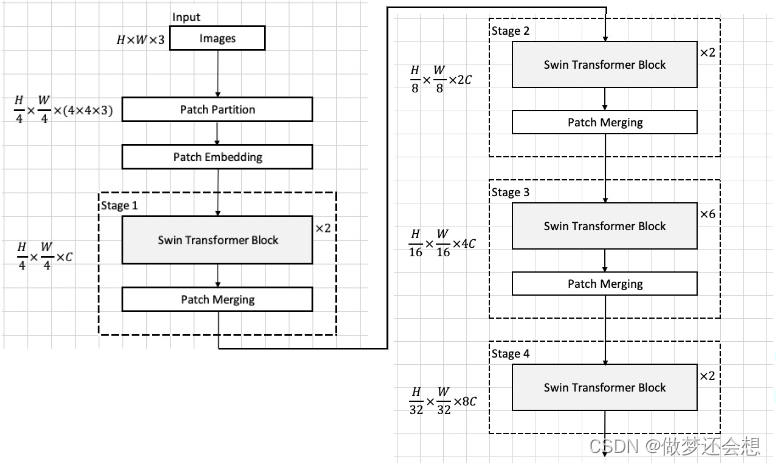
总体的流程我们再来梳理一遍:
- 一张[3,224,224]的图片通过图片分割和映射,也可以说是卷积操作以后得到特征图[96,56,56]
- 然后经过一个block1结构(别忘了里面还有残差结构哦,我们说了那么多的MSA只不过是它路程中的一部分),shape没变,再经过一个block2,shape还是没变,然后经过一个patch merging,shape变为[192,28,28],以此输入到下一个stage
- 流程与上面一致,最后输出的shape为[384,14,14]
- 这里乘了6个block,实际顺序就是block1,block2,block1,block2,block1,block2,所以最后输出为[768,7,7]
- 最后一个stage没有patch merging,所以输出固定为[768,7,7]
原理我们就全部说完了,下面我会将整个流程再做一次比较详细的推导,依然会告诉你每一步的shape是什么,依然会有简易代码进行辅助。
- 我们假设整个网络的输入依然为[5,3,224,224],之后会用一个主类来规定网络里面的各种超参,并且将各个部分组合起来。里面的超参数包括但不限于:①image size=224 ②patch size=4 ③embed dim=96 ④window size=7 ⑤四个stage分别采用几个头[4,8,16,32] ⑥每个stage包含的stage的个数[2,2,6,2]
- 然后经过patch embedding部分之后输出它的特征图,shape为[5,3136,96]。这个深度在哪个位置不影响理解,不同的框架深度位置不一致很正常。
- 然后利用循环进入不同的stage中,我们只需要说明第一个stage中的流程就可以了。
- 这里不论是否需要shift,使用的都是同一个类swin block(缩写好像不太好听,就一直用全称吧)。可以使用初始化中的shift size是否为0来判断是否需要循环填充。然后第一步是对输入进来的[5,56,56,96]先进行一次归一化,这叫pre norm,在流程图里面我们是在计算完了以后再norm,这里在计算前就norm,两种方法都可以,看你各自的训练效果如何。由于我们在stage1种的block1不需要进行循环填充,所以在把shape转为[5,56,56,96]以后直接进去到我们的窗口自注意力计算中
- 首先对特征层的[56,56]就行分割,步骤已经说明过了。输出shape为[320,7,7,96]。如果第零个维度出现了256,就把他当作320看待,因为我这儿的笔记batch还是用的4,但是它和头数相同了,有的时候容易误解,我怕到时候我打字打快了没改过来
- 然后shape改为[320,49,96]放入到窗口自注意力网络(class WindowAttention)中,在自注意力机制里面我依然设置的window size为7,num head=4,dim=96.
- 在WA类中做完各种初始化以后(例如Wq,Wk,Wv,还有最后融合的全连接层之类),要进行位置偏移参数的创建,直接贴代码
self.relative_position_bias_table = paddle.create_parameter(
shape=[(2*window_size-1)*(2*window_size-1), num_heads],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02))
coord_h = paddle.arange(self.window_size)
coord_w = paddle.arange(self.window_size)
coords = paddle.stack(paddle.meshgrid([coord_h, coord_w])) #[2, ws, ws]
coords = coords.flatten(1) #[2, ws*ws]
relative_coords = coords.unsqueeze(2) - coords.unsqueeze(1)
relative_coords = relative_coords.transpose([1, 2, 0])
relative_coords[:, :, 0] += self.window_size - 1
relative_coords[:, :, 1] += self.window_size - 1
relative_coords[:, :, 0] *= 2*self.window_size - 1
relative_coords_index = relative_coords.sum(2)
创建的bias_table的shape为[169,4],也就是说一个window里面每个头用不同的bias进行相加。这个table我们就已经做好了,之后只需要按照索引来从里面取值,然后加到attn里面就可以了。我们先要做出一张与attn的shape相同的49x49的相对位置索引图出来(就是我们刚才举例中的9x9)
第7行代码运行完毕以后其shape为[2,7,7],第8行是[2,49]。然后利用广播机制,第九行就是[2,49,49],然后转置为[49,49,2],这样这个2,就是相对位置中的相对横纵坐标。
然后我们如何比较相对坐标的异同呢?我们采用相对横纵坐标相加,但是这样会出现一个问题,那就是和一样,但是相对横纵却不一样。所以我们需要做两部处理:
第一步:把所有相对横纵坐标非负化,因为我们最小的相对横纵坐标是-6(0-6),所以全部加6就行了,这就是倒数3,4行的作用。
第二步:非负化以后依然存在和相同,xy却不同的情况。它这里利用的是使用一个函数,准确来说应该是线性函数来放大我们各自相对坐标的和。我们想一下,我们一共有多少种相对位置,169种,用索引来表示就是0到168。那我们能不能就让相对横纵坐标的和就放大到0到168之间?我们做个假设,最大的相对位置坐标是[12,12],先保证y不动,x乘13再加y,刚好就是168?这是巧合吗?肯定不是。因为这个13就是2*window size -1.我们做一个公式:
sum=13x+y,x,y取值均为[0,12],这个公式不就是我们要找的线性函数嘛,由于y<13,所以xy不同的时候,sum必不同,sum相同的时候,xy必相同,且刚好映射到[0,168]中的所有数,这就是倒数第二行代码的原理。所以我们最后得到的relative coords index的shape为[49,49].
- 回到步骤当中,我们将图片的特征输入[320,49,96]分别经过Wq,Wk,Wv之后得到q,k,v 均为[320,4,49,24]
- 相矩阵乘得到attn[320,4,49,49]
- 然后我们得到了index矩阵[49,49]但是这里面的数全都是索引(0到168),我们需要从一开始创建的[169,4]的参数中把数取出来,放到49x49的index矩阵中,代码如下:
def get_relative_position_bias_from_index(self):
table = self.relative_position_bias_table # [2m-1 * 2m-1, num_heads]
index = self.relative_coords_index.reshape([-1]) # [M^2, M^2] - > [M^2*M^2]
relative_position_bias = paddle.index_select(x=table, index=index) # [M*M, M*M, num_heads]
return relative_position_bias
这个index_select可以自己去搜搜它的api,可以在多个bacth上取相同位置的索引,所以最后的relative_position_bias的shape为[49x49,4]
- 将relative_position_bias的shape转为[1,4,49,49],然后和attn相加就可以了。从这里以及上面的步骤我们可以看到,不同的图片使用的是相同的bias。不同的头使用的是不同的bias。
- 后面接softmax以后与v相矩阵乘得到[320,4,49,24],之后四个头融合再接残差,然后输出我们就完成了block1的所有步骤,最后输出也是[320,49,96]
- 接下来接我们的block2,使用的是同一个类,不过增加了几个步骤。同样一开始是初始化,当然也包括mask相关的初始化,这个不重要,主要看mask是如何实现的。
- 同理,一步步下去到进行完pre norm以后,开始对[5,56,56,96]进行shift操作,其实很简单,直接调用接口:
if self.shift_size > 0:
shifted_x = paddle.roll(x, shifts=(-self.shift_size, -self.shift_size), axis=(1, 2))
这个api的参数我就不介绍了,最后shape不变[5,56,56,96]
- 然后继续进行窗口的切割,都是一样的[320,7,7,96],然后准备计算窗口自注意力。同样先创建bias参数,然后进行映射得到relative position bias[49x49,4]
- 开始计算attn,输入的shape为[320,49,96],然后经过Wq,Wk,Wv得到了q,k,v[320,4,49,24],然后在计算attn的时候你总得现有mask吧,所以在这儿之前先计算出来mask
def generate_mask(window_size=4, shift_size=2, input_resolution=(8, 8)):
H, W = input_resolution
img_mask = paddle.zeros([1, H, W, 1])
h_slices = [slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None)]
w_slices = [slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None)]
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
windows_mask = windows_partition(img_mask, window_size=window_size)
windows_mask = windows_mask.reshape([-1, window_size*window_size])
#[num_windows, ws*ws]
attn_mask = windows_mask.unsqueeze(1) - windows_mask.unsqueeze(2)
#[n, 1, ws*ws] - [n, ws*ws, 1] = [n, ws*ws, ws*ws]
attn_mask = paddle.where(attn_mask!=0,
paddle.ones_like(attn_mask) * 255,
paddle.zeros_like(attn_mask))
return attn_mask
它的原理有一点复杂。经过那个循环以后,我们就只拿56和56这两个维度来举例。它相当于已经在56x56的图上,标出了9个区域,就是我们shift的时候对特征图标注的9个区域
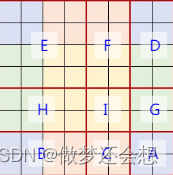
只用看红线划分的区域,不用看字母顺序,然后利用循环。把九个区域分别用0和8来取值。然后送到和对特征图进行窗口切割一样的函数里面,最后图还是用的这个图,但是意义已经完全不一样了,可以想象把下图中的E,FD,HB,IGCA部分单独拿出来了。
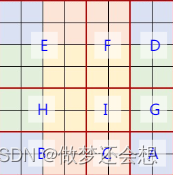
它的shape为[64,7,7,1],重点来了,由于我们做的是对特征图同样手法的窗口切割,那么这里面的7x7窗口,就肯定有一些窗口里面保存的数字不一样,比如FD这个窗口,F的位置是1,D的位置是2.所以我们得到mask的步骤如下
第一:转shape为[64,49]
第二:利用广播机制用[64,1,49]-[64,49,1]得到[64,49,49],是不是有点像attn的shape。然后我们可以看到,在一个window中的所有49个元素,用每一个元素和其他元素相减,只有一样的时候,结果才为0,不一样的时候我不用管不一样到底是多少,我知道你不一样就够了。这就是[64,49,49]做的事情。不一样的地方,我只需要用很小的数来代替,一样的地方本来相减就是0我就不动,这就是最后一行代码做的事情(这个255为什么是正数呢?我到时候直接减不就好了嘛)
- 后面就没什么难度了,由于我们的位置偏置在attn的时候就已经做了,所以最后只需要将mask的shape增维到[1,64,1,49,49],然后attn减它就可以了。最后就得到了我们想要的attn,之后步骤照旧,已经没有难点了。
- 所以我们可以看到,位置偏移在不同的图里面加的是一样的,在不同的头里面加的是不一样的,而mask,和你有几个头都没关系,不同的图的mask也是一样的(仅在此例中),只和窗口位置有关。
- 最后记得把shift以后的复原
- patch merging没什么技术含量需要说明的,就是cat,然后映射,大不了取田字格时候用一下[0::2]和[1::2]
- 之后只需要先循环block,尤其是stage3的6个block,然后再循环stage,swin transformer整个流程就结束了。
这篇博客的主要内容就基本告一段落,如果有什么疑惑或者我哪里说错的地方,欢迎指正。















 8746
8746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









