






快速判断一个元素是否出现集合里的时候,就要考虑哈希法!(牺牲空间换时间)
哈希表/散列表(hash table):是根据关键码的值而直接进行访问的数据结构,eg数组是通过数组下标访问。
哈希函数:数据元素的存放位置和数据元素的关键字之间建立起某种对应关系。
构造哈希函数有三个要点:
第一,运算过程要尽量简单高效,以提高哈希表的插入和检索效率;
第二,哈希函数应该具有较好的散列性,以降低哈希冲突的概率;
第三,哈希函数应具有较大的压缩性,以节省内存。
哈希碰撞:对于两个不同的关键字,通过我们的哈希函数计算哈希地址时却得到了相同的哈希地址。
拉链法:当未发生冲突时,则直接存放该数据元素;当冲突产生时,把产生冲突的数据元素另外存放在单链表中。
线性探测法:要保证tableSize大于dataSize。
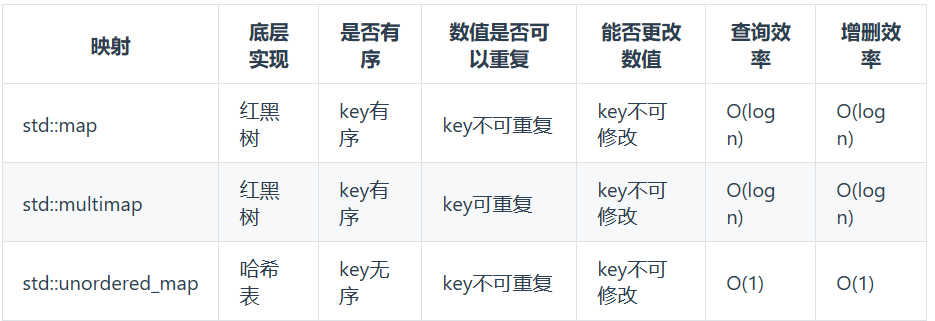
常见的三种哈希结构:数组、set(集合)、map(映射)(底层实现:红黑树/哈希表)
ps:
(17条消息) 【数据结构】史上最好理解的红黑树讲解,让你彻底搞懂红黑树_小七mod的博客-CSDN博客
数组型
242. 有效的字母异位
只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。
//哈希解法
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
if (s.size() != t.size()) return false;
for (int i = 0; i < s.size(); i++) {
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[s[i] - 'a']++;
record[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (record[i] != 0) {
// record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false; //return后相当于break
}
}
// record数组所有元素都为零0,说明字符串s和t是字母异位词
return true;
}
};383. 赎金信
//哈希解法
// 时间复杂度: O(n)
// 空间复杂度:O(1)
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int record[26] = {0};
if (ransomNote.size() > magazine.size()) {
return false;
}
for (int i = 0; i < magazine.size(); i++) {
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[magazine[i] - 'a']++;
}
for (int i = 0; i < ransomNote.size(); i++) {
record[ransomNote[i] - 'a']--;
// 如果小于零说明ransomNote里出现的字符,magazine没有
if(record[ransomNote[i]-'a'] < 0) {
return false;
}
}
// record数组所有元素都大于等于0,说明字符串magazine有足够字符表示ransomNote
return true;
}
};法二:暴力解法
// 时间复杂度: O(n^2)
// 空间复杂度:O(1)
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
for (int i = 0; i < magazine.length(); i++) {
for (int j = 0; j < ransomNote.length(); j++) {
// 在ransomNote中找到和magazine相同的字符
if (magazine[i] == ransomNote[j]) {
ransomNote.erase(ransomNote.begin() + j); // ransomNote删除这个字符
break;
}
}
}
// 如果ransomNote为空,则说明magazine的字符可以组成ransomNote
if (ransomNote.length() == 0) {
return true;
}
return false;
}
};49. 字母异位词分组
438. 找到字符串中所有字母异位词
set型
哈希值较少、分散、跨度大,使用数组就造成空间的极大浪费!!
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。

349. 两个数组的交集
无序!不重复!使用unordered_set!
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重
unordered_set<int> nums_set(nums1.begin(),nums1.end());
for (int num :nums2) { //遍历nums2
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
//set转化为vector返回
return vector<int>(result_set.begin(),result_set.end());
}
};202. 快乐数
class Solution {
public:
int getsum(int n) {
int sum = 0;
while (n) {
sum += (n % 10) * (n % 10); //取余符号,从个位开始算
n /= 10; //除只保留整数
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while (1) {
int sum = getsum(n);
if(sum == 1) {
return true;
}
// 如果这个sum曾经出现过,说明已经陷入了无限循环了,立刻return false
if(set.find(sum) != set.end()) {
return false;
}
else {
set.insert(sum);
}
n = sum;
}
}
};map型
1. 两数之和
数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
我们不仅要知道元素有没有遍历过,还有知道这个元素对应的下标。使用 key value结构来存放,key来存元素,value来存下标
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map<int,int> map;
for (int i = 0;i < nums.size();i++) {
// 遍历当前元素,并在map中寻找是否有匹配的key
auto iter = map.find(target - nums[i]);
if (iter != map.end()) {
return {iter->second, i};
}
// 如果没找到匹配对,就把访问过的元素和下标加入到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};454. 四数相加 II
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int,int> umap; //key:a+b的数值,value:a+b数值出现的次数
// 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : nums1) {
for (int b : nums2) {
umap[a +b]++;
}
}
int count = 0; // 统计a+b+c+d = 0 出现的次数
// 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : nums3) {
for (int d :nums4) {
if (umap.find(0 - (c + d)) != umap.end()) {
count += umap[0 - (c + d)];
}
}
}
return count;
}
};3. 无重复字符的最长子串
滑动窗口+哈希map!!
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map<char, int> window;
int leftIndex = 0, rightIndex = 0;
int result = 0;
while (rightIndex < s.size()) {
char c = s[rightIndex];
rightIndex++;
window[c]++;
while (window[c] > 1) {
char d =s[leftIndex];
leftIndex++;
window[d]--;
}
result = max(result, rightIndex - leftIndex);
}
return result;
}
};4. 双指针法优于哈希法
15. 三数之和
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> result;
sort(nums.begin(), nums.end());
// 找出a + b + c = 0
// a = nums[i], b = nums[left], c = nums[right]
for (int i = 0; i < nums.size(); i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) {
return result;
}
if (i > 0 && nums[i] == nums[i-1]) {
continue;
}
int left = i + 1;
int right = nums.size() - 1;
while (right > left) {
if(nums[i] + nums[left] + nums[right] > 0) right--;
else if(nums[i] + nums[left] + nums[right] < 0) left++;
else {
result.push_back(vector<int>{nums[i], nums[left], nums[right]});
// 去重逻辑应该放在找到一个三元组之后,对b 和 c去重
while (right > left && nums[right] == nums[right - 1]) right--;
while (right > left && nums[left] == nums[left + 1]) left++;
// 找到答案时,双指针同时收缩
right--;
left++;
}
}
}
return result;
}
};














 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









