







文章目录
yolox_model
yolox_model主要包括以下几个文件:
yolox.py、yolo_pafpn.py以及yolo_head.py
train时将图像以及label传入模型:
self.model(inps, targets)
传入模型之后进入 yolox.py,并且依次经过 YOLOXPAFPN 以及 YOLOXHead
YOLOPAFPN
fpn_outs = self.backbone(x)
进入 yolo_pafpn,py
这里可以参考我的另一篇文章ByteTrack多目标跟踪——YOLOX详解
举例:输入为 torch.Size ([1, 3, 896, 1600])
模型输出为:
{‘dark 3’: (1,320,112,200),
‘dark 4’: (1,640,56,100),
‘dark 5’: (1,1280,28,50)}
通过 PAFPN 进行融合后得到:
{‘0’: (1,320,112,200),
‘1’: (1,640,56,100),
‘2’: (1,1280,28,50)}
YOLOXHead
if self.training:
assert targets is not None
loss, iou_loss, conf_loss, cls_loss, l1_loss, num_fg, settings = self.head(
fpn_outs, targets, x
)
outputs = {
"total_loss": loss,
"iou_loss": iou_loss,
"l1_loss": l1_loss,
"conf_loss": conf_loss,
"cls_loss": cls_loss,
"num_fg": num_fg,
"settings": settings
}
else:
outputs = self.head(fpn_outs)
进入 yolo_head 中
model
总共有四个分支:
- Cls_output:目标框的类别,预测分数。因为只有行人一个类别,所以大小为 1。
- Obj_output:判断目标框是前景还是背景,大小也为 1。
- Reg_output:对目标框的坐标信息 (x,y,w,h)进行预测,大小为 4。
具体网络结构参见附录部分
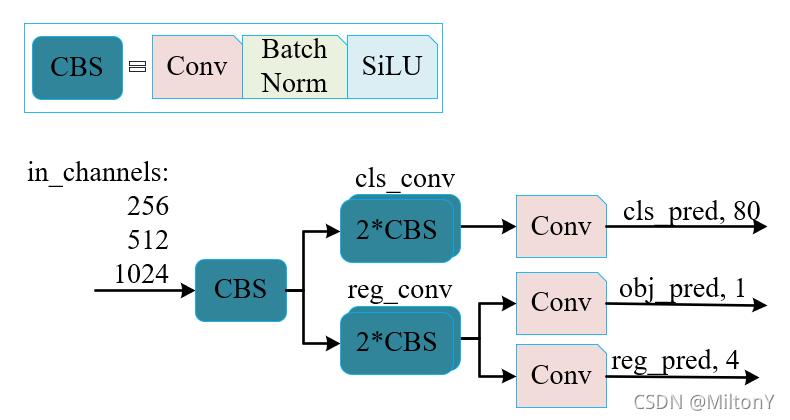
将三个分支输出结果合并
output = torch.cat([reg_output, obj_output, cls_output], 1)
进入 self.get_output_and_grid 函数中
output, grid = self.get_output_and_grid(output, k, stride_this_level, xin[0].type())
主要是创建特征图网络坐标点,并把神经网络前向推理的 bbox 投影输入图像的尺寸上
损失计算
输入:
- Imgs:一个 batch 的图像
- X_shifts、y_shifts: 特征图每个网格 grid 的 xy 坐标
- Expanded_strides: 不同尺寸的特征输出与输入图像之间缩小的倍数
- Labels: ground_truth 的类别号与 bbox (一个 batch 图像中的人工标注框与类别)
- Torch.Cat (outputs, 1): 对三个尺度的输出进行合并
if self.training:
return self.get_losses(
imgs,
x_shifts,
y_shifts,
expanded_strides,
labels,
torch.cat(outputs, 1),
origin_preds,
dtype=xin[0].dtype,
darkfpn=darkfpn,
)
获取 gt 数量
nlabel = (label_cut.sum(dim=2) > 0).sum(dim=1)
在计算损失时,yolox 需要做标签分配,这是 yolox 的重要思想。其中涉及的函数为 self.get_assignments
输入:
- Batch_idx: 批图像的索引
- Num_gt: 一幅图像存在的目标数目;
- Total_num_anchors: 总的 anchor 数目,yolox 提取的最后特征,每个方格表示一个 anchor
- Gt_bboxes_per_image: 一幅图像人工标注的框 box 坐标;
- Gt_classes: 一幅图像的标注框类别编号
- Bboxes_preds_per_image: 一幅图像预测的 bbox
- Expanded_strides: 三个尺度的每个特征方格相对于输入图的缩放像素[8,…],[16,…],[32,…]
- X_shifts, y_shifts: 每个特征方格位置偏移量组成的向量 (一个 batch)
- Cls_preds: 类别预测概率, 一个 batch 数据。[batch_num, anchors_all, num_cls]
- Bbox_preds:目标框的预测
- Obj_preds: 目标置信度概率
- Labels: yolo 人工标注框,一个 batch 数据。
- Imgs: 一个 batch 的图像数据
- Gt_ids:gt 中 ID
输出:
- Gt_matched_classes: 标签分配后,每列候选框预测目标的编号
- Fg_mask: 初步筛选中,in_boxes 与 in_center 的并集[29400]
- Pred_ious_this_matching: 由标签分配的 mask, 筛选真实框与预测框构成的 IoU 矩阵对应的 IoU 值
- Matched_gt_inds: matrix_matching 矩阵,存在候选框的位置 idx
- Num_fg_img: 标签分配完成后,总共存在的候选框个数 (matrix_matching 每列保证一个候选框)
(
gt_matched_classes, # [matched_anchor], class of matched anchors
fg_mask, # [n_anchors], .sum()=matched_anchor, to mask out unmatched anchors
pred_ious_this_matching, # [matched_anchor], IoU of matched anchors
matched_gt_inds, # [matched_anchor], index of gts for each matched anchor
num_fg_img, # [1], matched_anchor
) = self.get_assignments( # noqa
batch_idx,
num_gt,
total_num_anchors,
gt_bboxes_per_image,
gt_classes,
bboxes_preds_per_image,
expanded_strides,
x_shifts,
y_shifts,
cls_preds,
bbox_preds,
obj_preds,
labels,
imgs,
gt_ids,
)
初步筛选
筛选方式参考我的另一篇文章ByteTrack多目标跟踪——YOLOX详解
通过 get_in_boxes_info() 得到:
Fg_mask: in_boxes 与 in_center 的并集,
Is_in_boxes_and_center 为交集
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(
gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt
)
单幅图像,根据正样本锚框的初步筛选
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask] # [3717,4]
cls_preds_ = cls_preds[batch_idx][fg_mask] #[3717,1]
obj_preds_ = obj_preds[batch_idx][fg_mask] #[3717,1]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]
# 正样本锚框筛选的个数
即此时正样本框数量为 num_in_boxes_anchor个。
SimOTA 求解
先计算 bbox 的边界框损失与类别损失
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False) # [gt_num, matched_anchor]
gt_cls_per_image = (
F.one_hot(gt_classes.to(torch.int64), self.num_classes)
.float()
.unsqueeze(1)
.repeat(1, num_in_boxes_anchor, 1)
)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
with torch.cuda.amp.autocast(enabled=False):
cls_preds_ = ( # [gt_num, matched_anchor, 1]
cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* obj_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
pair_wise_cls_loss = F.binary_cross_entropy( # [gt_num, matched_anchor]
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
).sum(-1)
然后计算 Cost 成本
# lambda=3.0, 设置anchor box的中心,不在以中心点构建框与目标框中的cost=100000
cost = (pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000.0 * (~is_in_boxes_and_center))
最后进行 SimOTA 求解
### SimOTA, 求近似最优解 ###
# 输入:
# cost: 通过回归损失和类别损失计算得到的cost
# pair_wise_ious: size为[num_gt,num_in_boxes_anchor]的IoU计算,即所有真实框与预测框的IoU
# gt_classes: 一幅图像ground truth标注框的类别编号向量
# num_gt: 一幅图像的标注框个数
# fg_mask: 根据中心点与目标框初步筛选并集掩码
# 输出:
# num_fg: 标签分配完成后,总共存在的候选框个数(matrix_matching每列保证一个候选框)
# gt_matched_classes: 标签分配后,每列候选框预测目标的编号
# gt_matched_ids
# pred_ious_this_matching: 由标签分配的mask, 筛选真实框与预测框构成的IoU矩阵对应的IoU值
# matched_gt_inds: matrix_matching矩阵,存在候选框的位置idx
(num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds)
= self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
附:网络结构
Cls head
Cls_convs
ModuleList(
(0): Sequential(
(0): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(1): Sequential(
(0): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(2): Sequential(
(0): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
Cls_preds
ModuleList(
(0): Conv2d(320, 1, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(320, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(320, 1, kernel_size=(1, 1), stride=(1, 1))
)
Reg head
Reg_convs
ModuleList(
(0): Sequential(
(0): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(1): Sequential(
(0): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
(2): Sequential(
(0): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
(1): BaseConv(
(conv): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU(inplace=True)
)
)
)
Reg_preds
ModuleList(
(0): Conv2d(320, 4, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(320, 4, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(320, 4, kernel_size=(1, 1), stride=(1, 1))
)
Obj head
Obj_preds
ModuleList(
(0): Conv2d(320, 1, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(320, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(320, 1, kernel_size=(1, 1), stride=(1, 1))
)















 1983
1983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









