







YOLO检测器的发展历程
文章目录
YOLOv1
YOLO v1:You Only Look Once: Unified, Real-Time Object Detection
YOLOv1的核心思想是将目标检测问题视为一个回归问题,通过单个卷积神经网络(CNN)实现端到端的训练,从而实现快速且准确的目标检测。
主要特点
-
端到端训练:YOLOv1将目标检测任务简化为一个回归问题,通过一个CNN模型同时预测多个边界框和类别概率,省去了传统目标检测方法中的多个步骤,如候选区域生成、分类器评估、边界框优化等。
-
快速检测速度:YOLOv1的设计使其在保持较高检测精度的同时,能够实现接近实时的检测速度。在Titan X GPU上,YOLOv1的基本网络能够达到45帧每秒的检测速度,而其快速版本甚至能够达到155帧每秒。
-
全局视野:与传统的基于滑动窗口和候选区域的方法不同,YOLOv1在训练和测试时能够看到整个图像,这使得它能够隐式编码类别间的上下文信息和外观特征。
-
抽象特征学习:YOLOv1通过训练学习图像的抽象特征,使其在不同领域的图像上都有很好的检测效果,即使在艺术品上测试也能表现出色。
YOLOv2
YOLO v2:YOLO9000: Better, Faster, Stronger
这个改进版的目标是在保持 YOLOv1的高速检测能力的同时,显著提高检测的准确性。YOLOv2在多个方面进行了优化和增强,使其成为了一个更加强大和灵活的目标检测系统。
主要特点
-
更好的性能:YOLOv2在多个标准检测任务上取得了最先进的结果,如PASCAL VOC和COCO数据集。在67 FPS的情况下,YOLOv2在VOC 2007上达到了76.8 mAP,在40 FPS时达到了78.6 mAP,超过了当时最先进的方法,如Faster R-CNN和SSD。
-
多尺度训练:YOLOv2引入了多尺度训练方法,使得同一个模型可以在不同大小的图像上运行,提供了速度和精度之间的平衡。
-
批量归一化(Batch Normalization):YOLOv2采用了批量归一化技术,有助于加快训练速度并减少对初始化权重的敏感度。
-
高分辨率分类器:YOLOv2使用了一个高分辨率的分类器来提高检测精度。
-
锚框(Anchor Boxes):YOLOv2引入了锚框的概念,通过聚类分析得到更符合数据集特性的锚框,提高了检测的准确性。
-
细粒度特征:YOLOv2通过添加直通层(passthrough layer)来结合低层次和高层次的特征,有助于提高对小物体的检测能力。
-
联合训练目标检测和分类:YOLOv2提出了一种联合训练目标检测和分类的方法,使得模型能够利用大量已有的分类数据来提高检测性能。
YOLOv3
YOLO v3: An Incremental Improvement
主要特点
-
Darknet-53作为骨干网络:YOLOv3采用了作者自行设计并训练的Darknet-53作为其特征提取的主干网络。Darknet-53在分类精度上与ResNet-152和ResNet-101相当,同时具有更快的计算速度和更少的网络层数。
-
多尺度预测:YOLOv3在不同的尺度上进行三次检测,分别在32倍、16倍和8倍降采样的特征图上进行,类似于SSD(Single Shot MultiBox Detector)的多尺度检测。这种设计使得YOLOv3能够更好地检测不同大小的目标。
-
上采样和特征融合:为了提高对小目标的检测精度,YOLOv3采用了上采样(upsample)和特征融合技术,类似于FPN(Feature Pyramid Networks)。这使得模型能够在多个尺度的特征图上进行检测,提高了对小目标的检测能力。
-
改进的边界框预测:YOLOv3对边界框的预测进行了改进,采用了聚类分析来确定最佳的锚框(anchor boxes),并在每个网格单元中预测3个边界框。每个边界框包含位置、大小、置信度和类别概率。
-
损失函数的改进:YOLOv3在损失函数上进行了优化,不再对类别使用softmax,而是采用逻辑回归来评估锚框的目标性(objectness)。此外,损失函数中还包括了对坐标、大小和类别的损失。
YOLOv4
YOLOv4: Optimal Speed and Accuracy of Object Detection
AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet ) (github.com)
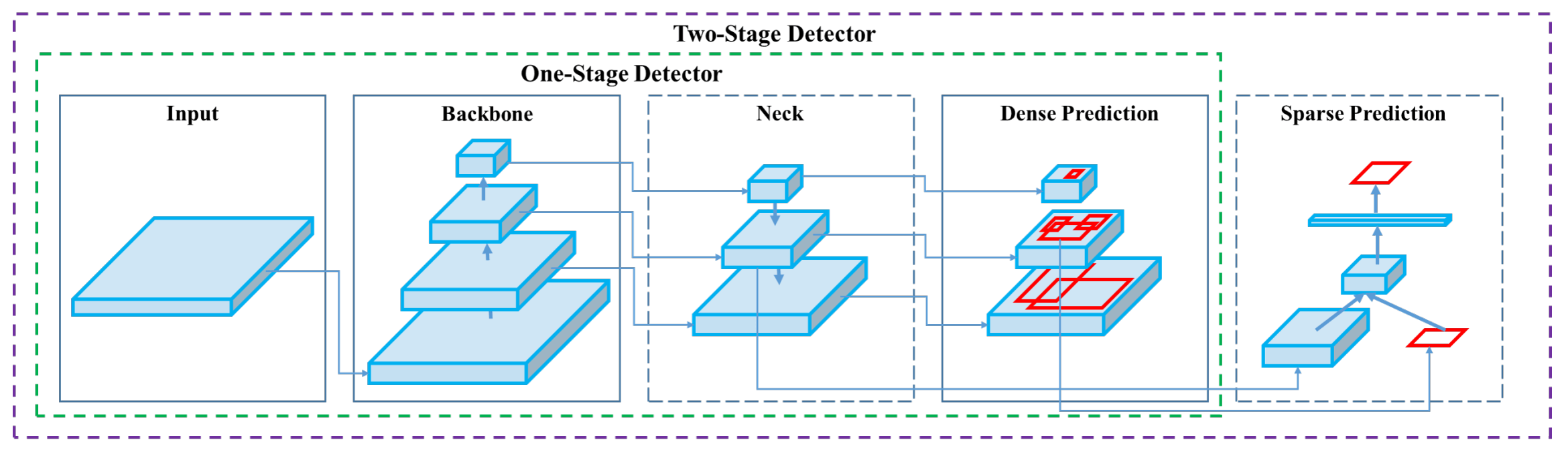
主要特点
-
高效的模型设计:YOLOv4的设计重点在于提高生产系统中目标检测器的操作速度和并行计算的优化,而不仅仅是降低理论计算指标(如BFLOPs)。这使得YOLOv4能够在常规GPU上实现实时、高质量和令人信服的目标检测结果。
-
Bag-of-Freebies和Bag-of-Specials:YOLOv4验证了在目标检测器训练过程中使用的最新Bag-of-Freebies和Bag-of-Specials方法的影响。这些方法包括但不限于网络结构的改进、训练策略的调整以及数据增强技术等。
-
模型结构的创新:YOLOv4在架构、特征提取器(backbone)CSPDarknet53、特征融合(neck)PANet 和预测头(head)YOLOv3等方面进行了创新。它采用了一些最先进的方法,如 CBN、PAN、SAM 等,并对其进行了改进,使其更适合单 GPU 训练。
-
性能提升:与YOLOv3相比,YOLOv4在平均精度(AP)和每秒帧数(FPS)方面分别提高了10%和12%。此外,YOLOv4的运行速度是EfficientDet的两倍以上,且性能相当。
-
广泛的应用:YOLOv4的设计使其易于训练和使用,适用于各种平台,包括GPU和CPU。它适用于需要实时、高质量目标检测的各种应用场景。
YOLOv5
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
YOLOv5是目标检测领域的一个重要进展,由Ultralytics LLC公司的创始人兼CEO Glenn Jocher发布。尽管YOLOv5在YOLO系列的发展中引起了一些争议,但它仍然被广泛认为是YOLO家族中的一个有价值的补充。YOLOv5的发布标志着YOLO系列在目标检测技术上的持续创新和进步。
主要特点
-
轻量级和高效性:YOLOv5被设计为适合在资源受限的环境中运行,如移动设备和嵌入式系统。它具有较小的模型大小和快速的推理速度,使得它在实际应用中非常受欢迎。
-
多种版本:YOLOv5提供了不同大小的模型版本,包括YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,以适应不同的性能需求和部署环境。
-
PyTorch实现:与之前的YOLO版本使用Darknet框架不同,YOLOv5是使用PyTorch框架实现的,这使得它更容易被社区接受和使用,同时也方便了模型的部署和集成。
-
自适应锚框计算:YOLOv5在训练时能够根据数据集自适应地计算锚框,这有助于提高模型对不同数据集的适应性和检测性能。
-
改进的网络结构:YOLOv5在网络结构上进行了多项改进,包括采用CSP结构和FPN+PAN的 Neck结构,以及CIOU Loss等,这些改进有助于提高模型的准确性和鲁棒性。
YOLOv6
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
改进版本:YOLOv6 v3.0: A Full-Scale Reloading
YOLOv6是由美团视觉智能部研发的目标检测框架,专为工业应用而设计。它在保持高精度的同时,特别关注推理效率,旨在满足实际工业环境中对速度和准确性的不同要求。YOLOv6的设计理念是在不同规模的模型中实现最佳的速度和精度权衡,以适应多样化的应用场景。
该模型在架构和训练方案上引入了几项显著的改进,包括双向串联(BiC)模块、锚点辅助训练(AAT)策略以及改进的骨干和颈部设计,从而在 COCO 数据集上实现了最先进的精度。

主要特点
-
高精度和高速度:YOLOv6-nano在COCO数据集上的精度可达35.0% AP,推理速度可达1242 FPS(每秒帧数);YOLOv6-s的精度可达43.1% AP,推理速度可达520 FPS。
-
多平台支持:YOLOv6支持在多种硬件平台上部署,包括GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等,简化了工程部署时的适配工作。
-
网络设计:YOLOv6采用了RepVGG提出的结构重参数化方法,以及高效的可重参数化骨干网络(EfficientRep),以适应不同规模的模型。
-
标签分配和损失函数:YOLOv6采用了任务对齐学习(TAL)作为标签分配策略,并选择了VariFocal损失(VFL)作为分类损失,以及SIoU/GIoU损失作为回归损失。
-
量化和部署:YOLOv6使用了重新参数化优化器(RepOptimizer)进行训练,以获得对PTQ(Post-Training Quantization)友好的权重,并通过通道蒸馏(CW蒸馏)进行量化感知训练(QAT),以提高量化性能。
YOLOv7
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
传统的实时物体检测器侧重于结构优化,而 YOLOv7 则不同,它侧重于训练过程的优化。其中包括一些模块和优化方法,目的是在不增加推理成本的情况下提高物体检测的准确性,这一概念被称为 “可训练的无用包”。
YOLOv7 引入了几项关键功能:
-
模型重新参数化:YOLOv7 提出了一种有计划的重新参数化模型,这是一种适用于不同网络层的策略,具有梯度传播路径的概念。
-
动态标签分配:多输出层模型的训练提出了一个新问题:"如何为不同分支的输出分配动态目标?为了解决这个问题,YOLOv7 引入了一种新的标签分配方法,即从粗到细的引导标签分配法。
-
扩展和复合缩放YOLOv7 为实时对象检测器提出了 "扩展 "和 "复合缩放 "方法,可有效利用参数和计算。
-
效率:YOLOv7 提出的方法能有效减少最先进的实时物体检测器约 40% 的参数和 50% 的计算量,推理速度更快,检测精度更高。
YOLOv8
ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)
主要功能
- 先进的骨干和颈部架构: YOLOv8 采用了最先进的骨干和颈部架构,从而提高了特征提取和物体检测性能。
- 无锚分裂Ultralytics 头: YOLOv8 采用无锚分裂Ultralytics 头,与基于锚的方法相比,它有助于提高检测过程的准确性和效率。
- 优化精度与速度之间的权衡: YOLOv8 专注于保持精度与速度之间的最佳平衡,适用于各种应用领域的实时目标检测任务。
- 各种预训练模型: YOLOv8 提供一系列预训练模型,以满足各种任务和性能要求,从而更容易为您的特定用例找到合适的模型。
YOLOv9
YOLOv9: A Revolutionary Update for Real-Time Goal Detection
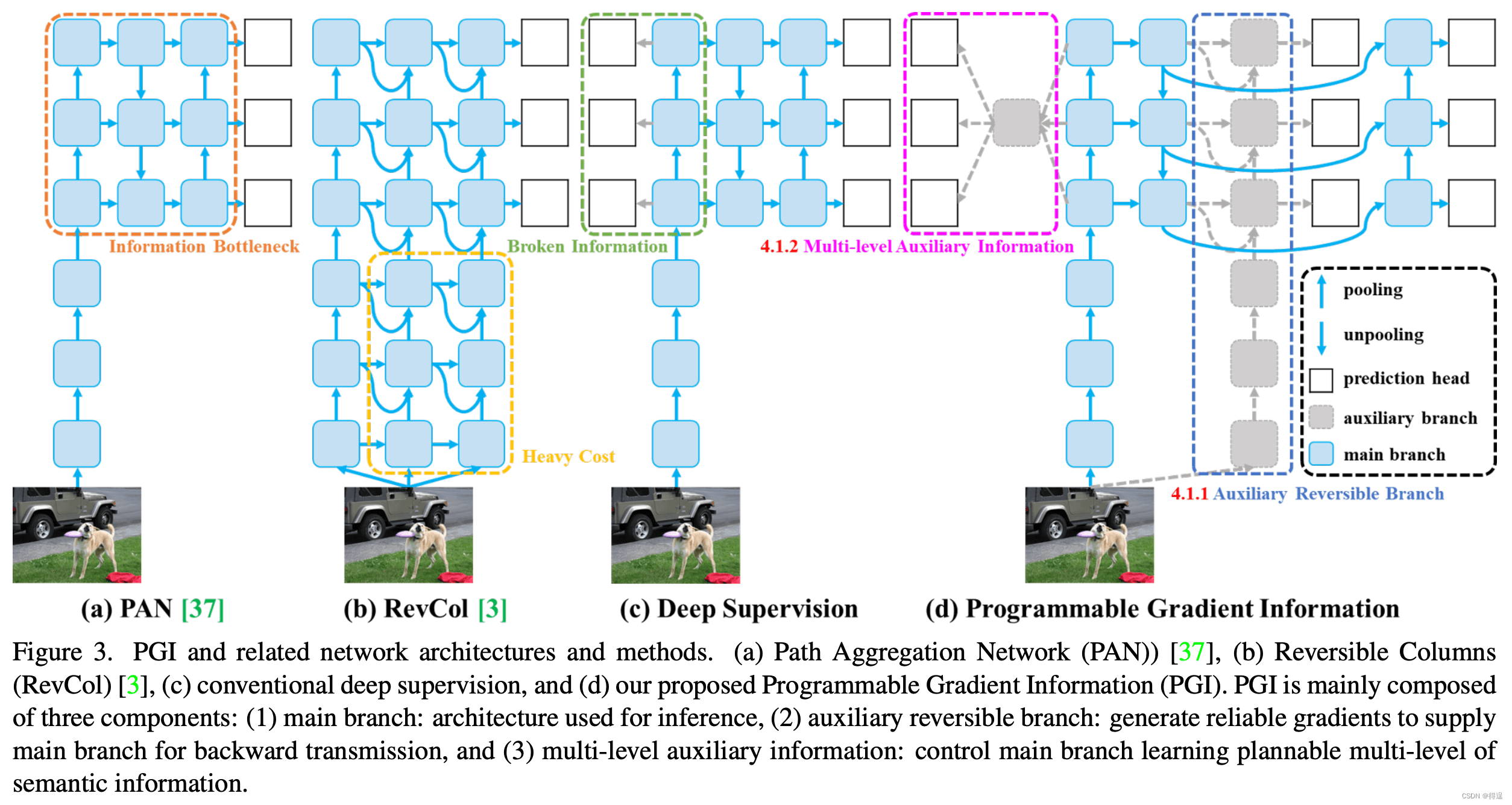
在追求最佳实时物体检测的过程中,YOLOv9 以其创新的方法克服了深度神经网络固有的信息丢失难题,脱颖而出。通过整合 PGI 和多功能 GELAN 架构,YOLOv9 不仅增强了模型的学习能力,还确保了在整个检测过程中保留关键信息,从而实现了卓越的准确性和性能。
关键特性
-
可编程梯度信息(PGI):YOLOv9引入了PGI的概念,旨在解决深度神经网络中的信息瓶颈问题。PGI通过为目标任务提供完整的输入信息来计算目标函数,从而获得可靠的梯度信息以更新网络权重。这一技术显著提高了目标检测的准确率,并为实时高精度目标检测提供了可能。
-
泛化高效层聚合网络(GELAN):YOLOv9采用了全新的网络架构GELAN,该架构通过梯度路径规划优化了网络结构,使用传统的卷积操作符实现了超越当前最先进方法的参数利用效率。GELAN的设计提高了模型的性能,同时保持了模型的高效性,使YOLOv9在保持轻量级的同时,达到了前所未有的准确度和速度。
-
性能提升:与前代版本相比,YOLOv9在参数数量、计算量和准确度方面都有显著提升。例如,与YOLOv8相比,YOLOv9在参数和计算量上分别减少了49%和43%,同时在MS COCO数据集上的平均精度(AP)提升了0.6%。
YOLO其他系列
YOLOX
YOLOX: Exceeding YOLO Series in 2021
Megvii-BaseDetection/YOLOX: YOLOX is a high-performance anchor-free YOLO, exceeding yolov3~v5 with MegEngine, ONNX, TensorRT, ncnn, and OpenVINO supported. Documentation: https://yolox.readthedocs.io/ (github.com)
YOLO-world
YOLO-World: Real-Time Open-Vocabulary Object Detection
AILab-CVC/YOLO-World: [CVPR 2024] Real-Time Open-Vocabulary Object Detection (github.com)
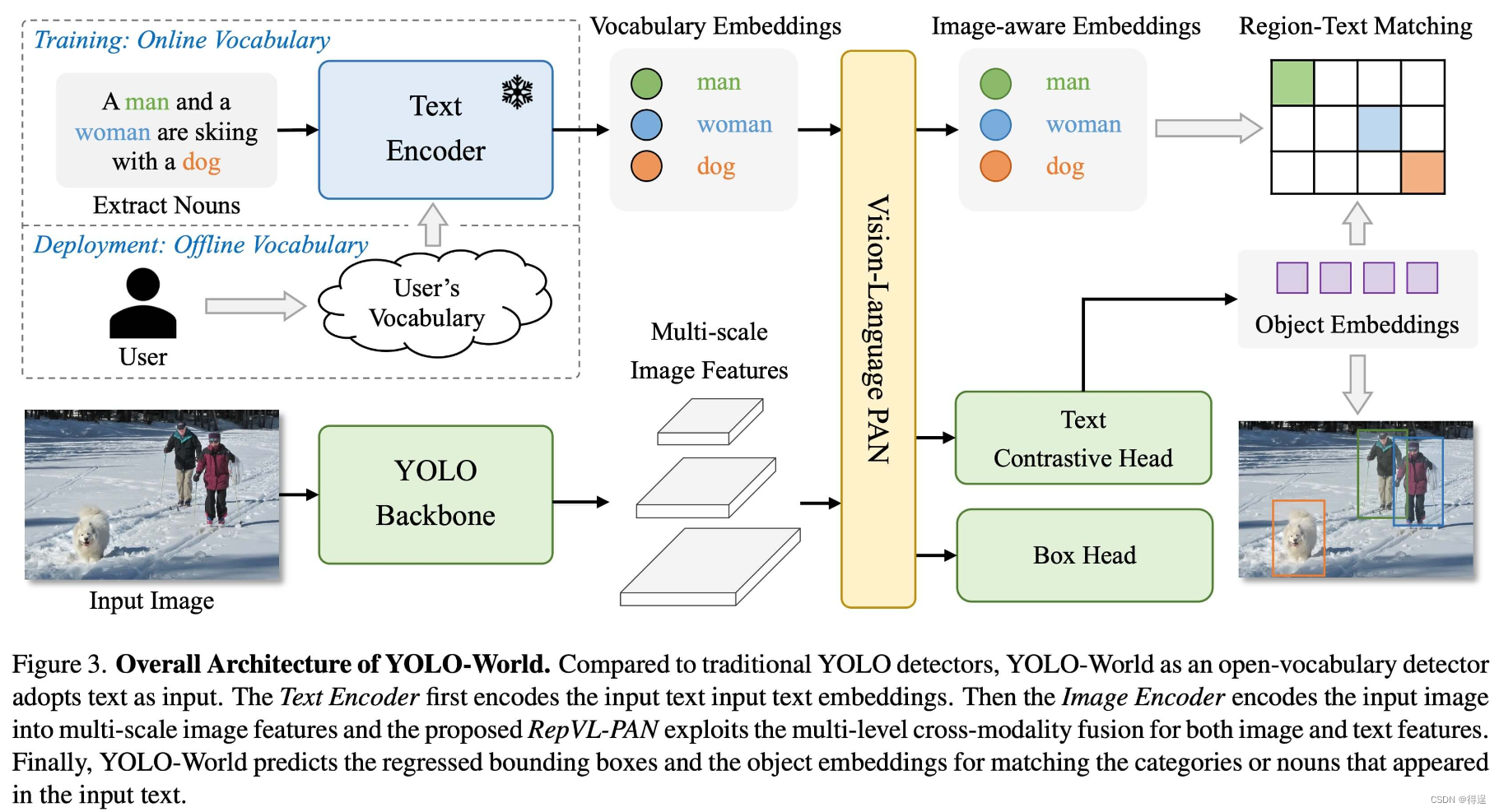
YOLO-传统的开放式词汇检测模型通常依赖于需要大量计算资源的繁琐的 Transformer 模型。这些模型对预定义对象类别的依赖也限制了它们在动态场景中的实用性。YOLO-World 利用开放式词汇检测功能重振了 YOLOv8 框架,采用了视觉语言建模和在大量数据集上进行预训练的方法,能够以无与伦比的效率在零拍摄场景中出色地识别大量物体。
主要功能
-
实时解决方案:利用 CNN 的计算速度,YOLO-World 可提供快速的开放词汇检测解决方案,满足各行业对即时结果的需求。
-
效率和性能: YOLO-World 可在不牺牲性能的前提下降低计算和资源需求,提供了一种可替代SAM 等模型的强大功能,但计算成本仅为它们的一小部分,从而支持实时应用。
-
利用离线词汇进行推理: YOLO-World 引入了 "先提示后检测 "的策略,利用离线词汇进一步提高效率。这种方法可以使用预先计算的自定义提示,包括标题或类别,并将其编码和存储为离线词汇嵌入,从而简化检测过程。
-
由 YOLOv8 支持:基于 Ultralytics YOLOv8,YOLO-World 利用实时对象检测方面的最新进展,以无与伦比的准确性和速度促进开放词汇检测。
-
卓越的基准测试: YOLO在标准基准测试中,World 的速度和效率超过了现有的开放词汇检测器,包括 MDETR 和 GLIP 系列,展示了YOLOv8 在单个 NVIDIA V100 GPU 上的卓越性能。
-
应用广泛: YOLO-World 的创新方法为众多视觉任务带来了新的可能性,与现有方法相比,速度提高了几个数量级。
YOLOF
YOLOF:You Only Look One-level Feature
megvii-model/YOLOF (github.com)
YOLOF 是一种新的目标检测模型,它不采用复杂的特征金字塔,仅使用一级特征进行检测,旨在简化设计并提高速度。
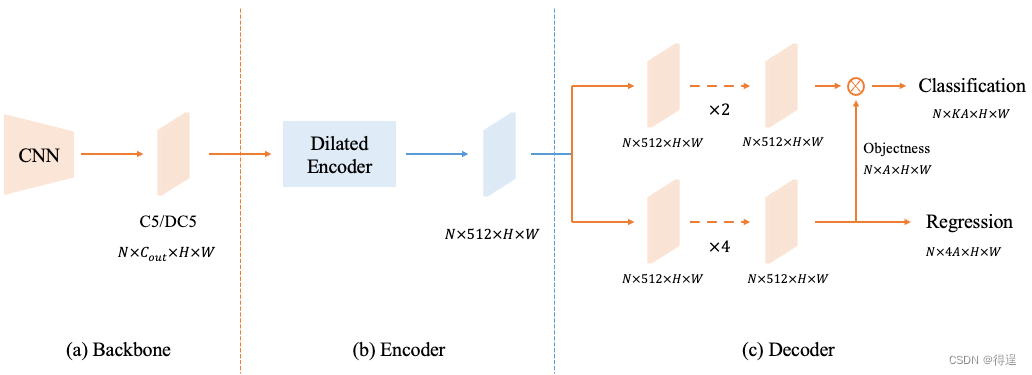
YOLOR
You Only Learn One Representation: Unified Network for Multiple Tasks
WongKinYiu/yolor: implementation of paper - You Only Learn One Representation: Unified Network for Multiple Tasks (https://arxiv.org/abs/2105.04206) (github.com)
YOLOR提出的统一网络生成统一的表示,以同时为多种任务提供服务,这表明它可能具有多任务处理的能力。
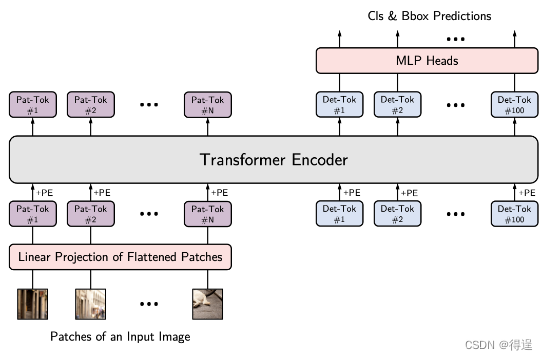
YOLOS
YOLOS:You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
hustvl/YOLOS: [NeurIPS 2021] You Only Look at One Sequence (github.com)
YOLOS是将Transformer应用于目标检测的一个尝试,它只查看每一层的一个序列,是对视觉Transformer的新思考。

















 4429
4429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









