







文章目录
项目地址: ByteTrack
详细代码解读可以参考: ByteTrack多目标跟踪——yolox_model代码详解
ByteTrack使用的检测器是YOLOX,是一个目前非常流行并且效果非常好的检测器,ByteTrack的跟踪效果也完全离不开YOLOX的检测性能。
1 before train
训练之前的准备,主要是初始化模型以及数据集。
1.1 dataset
在ByteTrack中图像输入大小为:(896,1600)
1.2 model
初始化
YOLOXPAFPN
YOLOXHead
2 train
2.1 Backbone
采用Darknet-53
self.backbone = CSPDarknet(depth, width, depthwise=depthwise, act=act)
backbone的输入input为一个batch的图片 (B,C,H,W)
out_features = self.backbone(input)
out_features的输出为3个特征层(分别为’dark3’,‘dark4’,‘dark5’)组成的字典,举个例子,各特征层的shape如下:
{‘dark3’:(B,320,112,200),
‘dark4’:(B,640,56,100),
‘dark5’:(B,1280,28,50)}
均为(B,C,H,W),只是尺寸和特征维度不同。
2.2 PAFPN
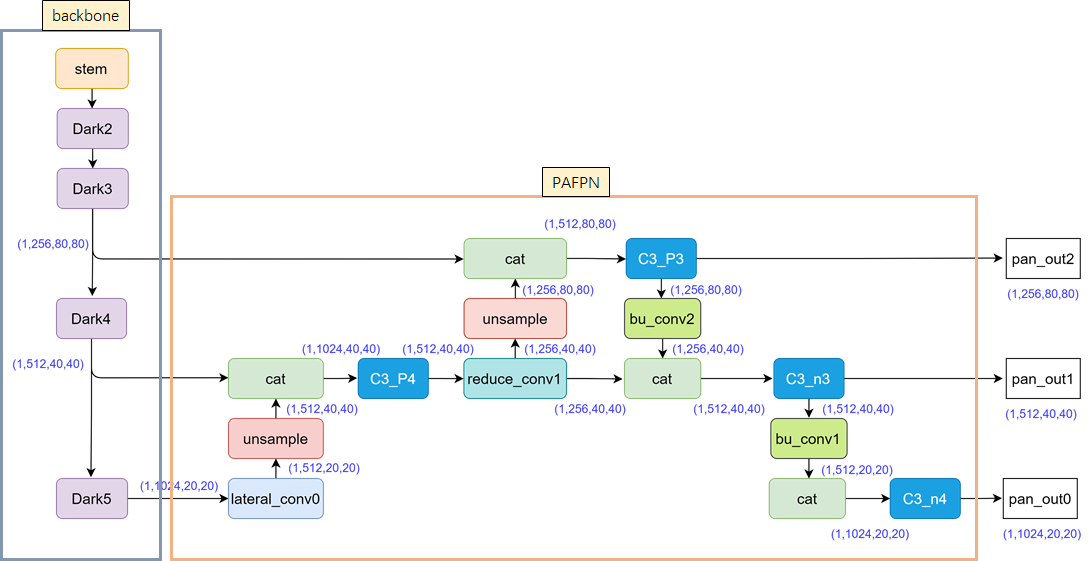
在Neck结构中,Yolox采用PAFPN的结构进行融合。如下图所示,将高层的特征信息,先通过上采样的方式进行传递融合,再通过下采样融合方式得到预测的特征图,最终输出3个特征层组成的元组结果,各特征层的shape如下:
{‘dark3’:(B,320,112,200),
‘dark4’:(B,640,56,100),
‘dark5’:(B,1280,28,50)}
均为(B,C,H,W),只是尺寸和特征维度不同。
2.3 Head
2.3.1 Decoupled Head
在Yolox中,作者增加了三个Decoupled Head,俗称“解耦头”。
总共有三个分支:
- cls_output:主要对目标框的类别,预测分数。因为只有行人一个类别,所以大小为1,这里为(B,1,112,200)。
- obj_output:主要判断目标框是前景还是背景,这里为(B,1,112,200)。
- reg_output:主要对目标框的坐标信息(x,y,w,h)进行预测,这里为(B,4,112,200)。
![![[yolox网络图.png]]](https://img-blog.csdnimg.cn/direct/e1b03df626d544c6a14dd02d4c1172f6.png)
2.3.2 anchor-free
首先,相对anchor-based参数量大大减小。

举个例子,最后8400个预测框中,其中有400个框,所对应锚框的大小,为32*32。中间的分支,最后有1600个预测框,所对应锚框的大小,为16*16。最下面的分支,最后有6400个预测框,所对应锚框的大小,为8*8。
当有了29400个预测框的信息,每张图片也有标注的目标框的信息。
这时的锚框,就相当于桥梁。
这时需要做的,就是将29400个锚框,和图片上所有的目标框进行关联,挑选出正样本锚框。
而相应的,正样本锚框所对应的位置,就可以将正样本预测框,挑选出来。
这里采用的关联方式,就是标签分配。
2.3.3 标签分配
① 初步筛选
yolo_head.py的get_in_boxes_info函数中,如果 anchor bbox 中心落在 groundtruth bbox或 fixed bbox,则被选中为候选正样本。
- 根据中心点判断

anchor box的中心点落在人工标注框(Ground Truth Boxes)的矩形范围中的所有anchor;
- 通过groundtruth的[x_center,y_center,w,h],计算出每张图片的每个groundtruth的左上角、右下角坐标
gt_bboxes_per_image_l = (
(gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1)
.repeat(1, total_num_anchors)
) # [n_gt, n_anchor]
gt_bboxes_per_image_r = (
(gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1)
.repeat(1, total_num_anchors)
) # [n_gt, n_anchor]
gt_bboxes_per_image_t = (
(gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1)
.repeat(1, total_num_anchors)
) # [n_gt, n_anchor]
gt_bboxes_per_image_b = (
(gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1)
.repeat(1, total_num_anchors)
) # [n_gt, n_anchor]
- 前4行代码计算锚框中心点(x_center,y_center)和gt标注框左上角(gt_l,gt_t),右下角(gt_r,gt_b)两个角点的相应距离。
b_l = x_centers_per_image - gt_bboxes_per_image_l
b_r = gt_bboxes_per_image_r - x_centers_per_image
b_t = y_centers_per_image - gt_bboxes_per_image_t
b_b = gt_bboxes_per_image_b - y_centers_per_image
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2)
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0
- 而在第五行,将四个值叠加之后,通过第六行,判断是否都大于0?就可以将落在groundtruth矩形范围内的所有anchors,都提取出来了。因为ancor box的中心点,只有落在矩形范围内,这时的b_l,b_r,b_t,b_b都大于0。
- .根据目标框来判断

以Ground Truth Boxes中心点为基准,四周向外扩展2.5倍stride,构成边长为5倍stride的正方形,挑选anchor box中心点落在正方形内的所有锚框。
- 以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。
- 如果图片的尺寸为 640 × 640,且当前特征图的尺度为 80 × 80,则此时stride为 8, 将 5 × 5 的正方形映射回原图,fixed bbox 尺寸为 400 × 400。
- 找出所有中心点(x_center,y_center)在正方形内的锚框。
- 未选中的预测框为负样本,直接打上负样本标签。
总体来说get_in_boxes_info返回两个值,fg_mask和is_in_boxes_and_center,fg_mask为29400维数组,即29400个框的正负性,用ture和false表示,is_in_boxes_and_center为[gt_num, 正样本个数]
② simOTA
假定图片上有3个目标框,即3个groundtruth,且检测类别为1。
上一节中,我们知道有29400个锚框,但是经过初步筛选后,假定有1000个锚框是正样本锚框。
- 初筛正样本信息提取
根据位置,可以将网络预测的候选检测框位置bboxes_preds、前景背景目标分数obj_preds、类别分数cls_preds等信息,提取出来。
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask] # [1000, 4]
cls_preds_ = cls_preds[batch_idx][fg_mask] # [1000, 1]
obj_preds_ = obj_preds[batch_idx][fg_mask] # [1000, 1]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0] # 1000
- Loss函数计算
针对筛选出的1000个候选检测框,和3个groundtruth计算Loss函数。
- 首先是位置信息的loss值:
pair_wise_ious_loss[3,1000]
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False) # [gt_num, matched_anchor]
gt_cls_per_image = ( # [gt_num, matched_anchor, class_num]
F.one_hot(gt_classes.to(torch.int64), self.num_classes)
.float().unsqueeze(1)
.repeat(1, num_in_boxes_anchor, 1)
)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
- 然后是综合类别信息和目标信息的loss值:
pair_wise_cls_loss[3,1000]
cls_preds_ = ( # [gt_num, matched_anchor, 1]
cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() # [gt_num, matched_anchor, 1]
* obj_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() # [gt_num, matched_anchor, 1]
)
pair_wise_cls_loss = F.binary_cross_entropy( # [gt_num, matched_anchor]
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
).sum(-1)
- cost成本计算
有了reg_loss和cls_loss,就可以将两个损失函数加权相加,计算cost成本函数了。
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center)
)
- SimOTA
采用一种简化版的SimOTA方法,求解近似最优解。这里对应的函数,是get_assignments函数中的self.dynamic_k_matching:
num_fg,gt_matched_classes, gt_matched_ids, pred_ious_this_matching, matched_gt_inds,)
= self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, gt_ids, num_gt, fg_mask)
2.3.4 Loss计算
loss_iou = (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets) # [matched_anchor, 4]
).sum() / num_fg
loss_obj = (self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets) # [all_anchor, 1]
).sum() / num_fg
loss_cls = (self.bcewithlog_loss(
cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets # [matched_anchor, 1] )
).sum() / num_fg
在前面精细化筛选中,使用了reg_loss和cls_loss,筛选出和目标框所对应的预测框。
因此这里的iou_loss和cls_loss,只针对目标框和筛选出的正样本预测框进行计算。
而obj_loss,则还是针对29400个预测框。














 2053
2053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









