







In Chapter 1, we introduce the idea of evolvability: we should aim to build systems that make it easy to adapt to change. In most cases, a change to an application’s features also requires a change to data that it stores: perhaps a new field or a record type needs to be captured, or perhaps existing data needs to be presented in a new way.
In Chapter 2, we discussed different ways of coping with such change.
With server-side applications you may want to perform a rolling upgrade. With cliend-side applications, client may not install the update for some time.
In order for the system to continue work smoothly, we need to maintain compatibility in both old codes and new codes.
- Backward compatibility: Newer code can read data that was written by older code.
- Forward compatibility: Older code can read data that was written by newer code.
Formats for Encoding Data
There are two different representations of data, they are:
- In memory, data is kept in objects, structs, trees, etc. They are optimized for efficient access and manipulation by the CPU.
- When you want to write data to a file or send it over the network, you have to encode it as some kind of self-contained sequence of bytes, such as JSON.
The translation from the in-memory representation to a byte sequence is called encoding, and the reverse is called decoding.
Language-Specific Formats
Many programming languages come with built-in support for encoding in-memory objects into byte sequences. But they have a number of deep problems.
- The encoding is often tied a particular programming language.
- Versioning data is often an afterthought in these libraries.
- Efficiency
- Security problems
JSON, XML, and Binary Variants
Problems:
- In XML and CSV, you cannot distinguish between a number and a string that happens to consist of digits. JSON distingushes strings and numbers, but it doesn’t distingush integers and floats/
- JSON and XML have good support for Unicode character strings, but they don’t support binary strings.
Binary encoding
the following is an example:
- This is JSON format:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
- binary encoding for JSON:
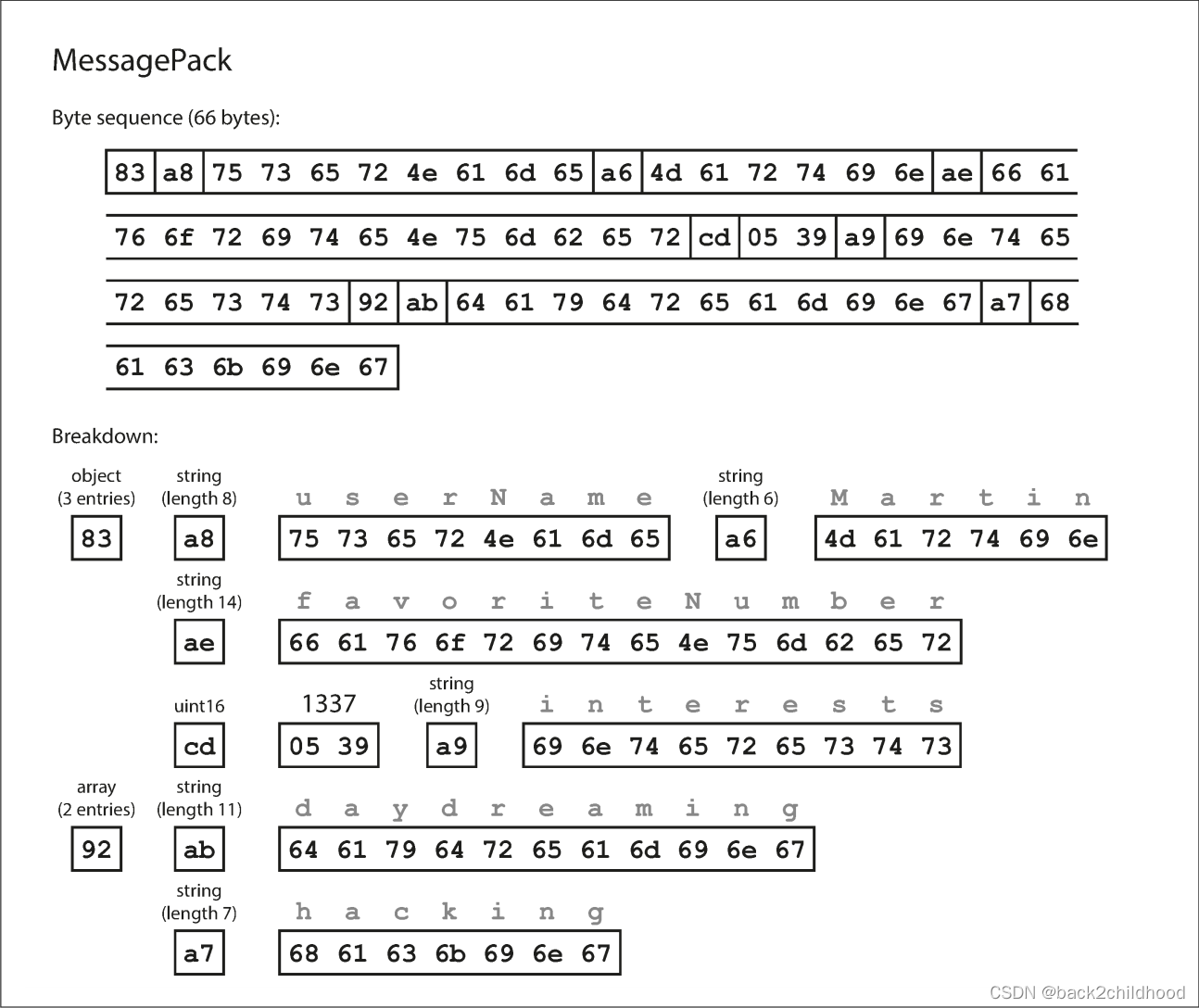
- The first byte, 0x83, indicates that what follows is an object (top four bits = 0x80) with three fields (bottom four bits = 0x03). (In case you’re wondering what happens if an object has more than 15 fields, so that the number of fields doesn’t fit in four bits, it then gets a different type indicator, and the number of fields is encoded in two or four bytes.)
Thrift and Protocol Buffers
Thrift interface definition language (IDL) is like this:
struct Person{
1:required string userName,
2:optional i64 favoriteNumber,
3:optional list<string> interests
}
Protocol Buffers IDL very similar:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Thrift
Thrift has two different binary encoding formats, called BinaryProtocol and CompactProtocol.
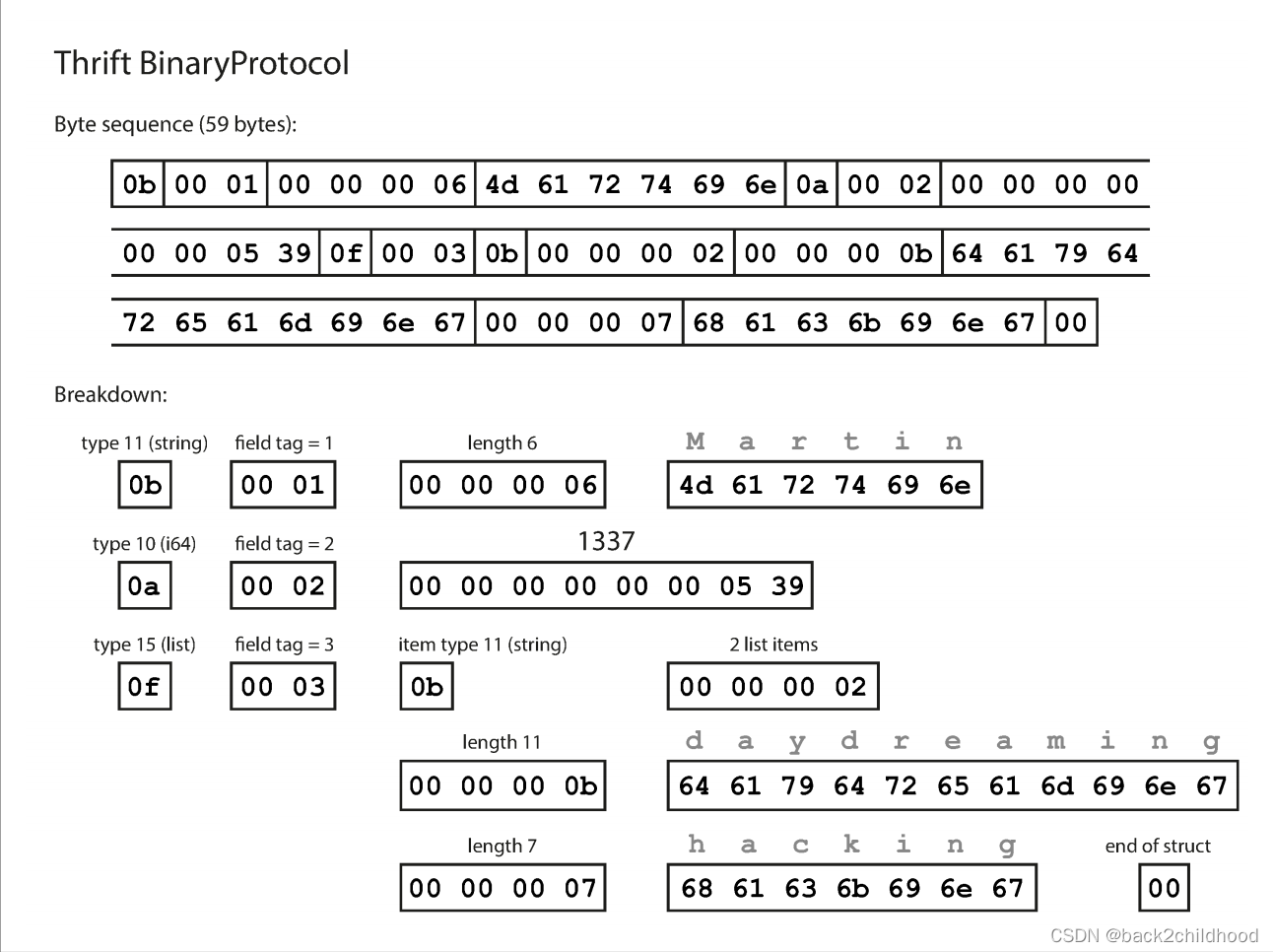
- This is BinaryProtocol:
The big difference compared toMessagePackis that there are no field names(userName, favoriteNumber). Instead, the encoded data contains field tags.
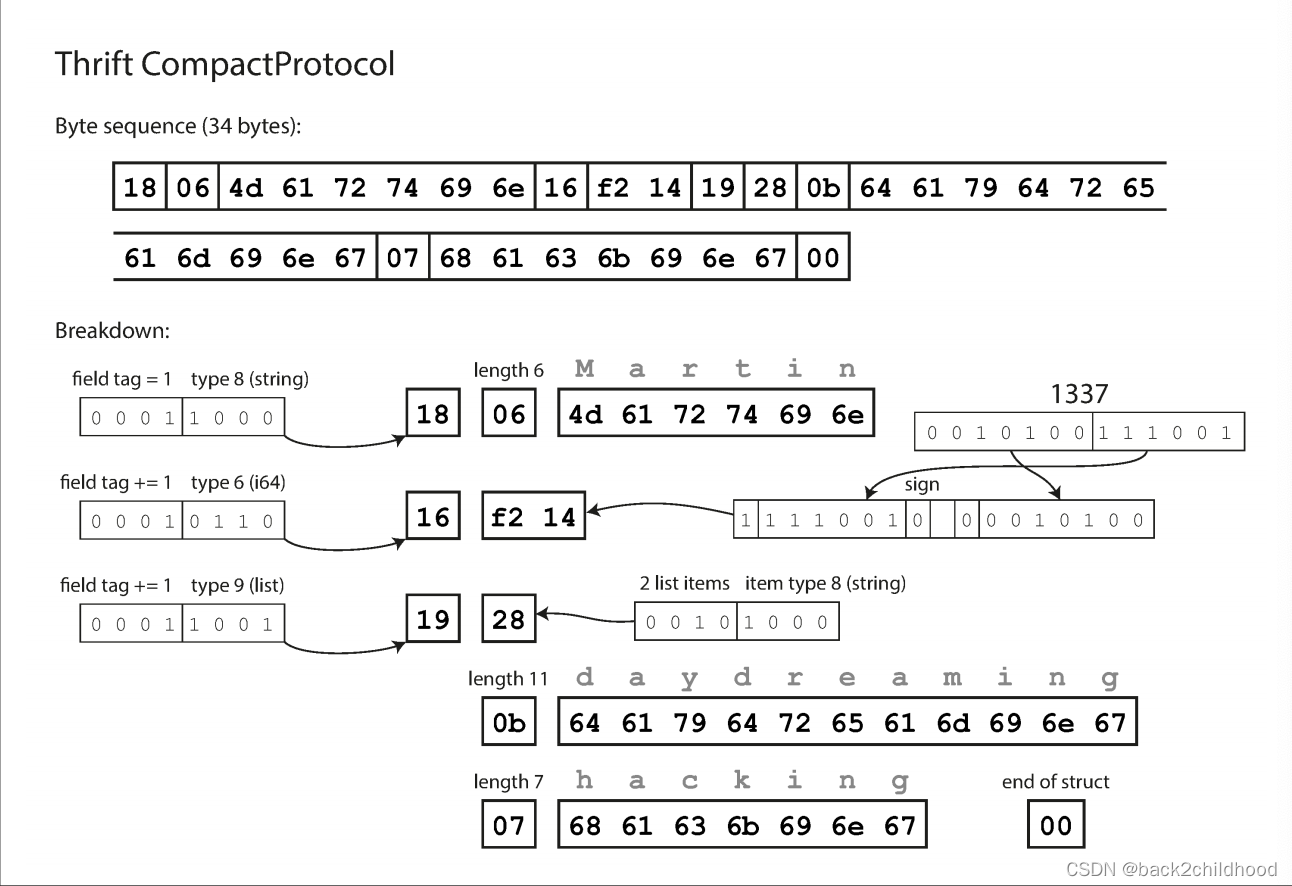
- This is CompactProtocol:
Rather than using a full eight bytes for the number 1337, it is encoded in two bytes, with the top bit of each byte used to indicate whether there are still more bytes to come. This means numbers between –64 and 63 are encoded in one byte, numbers between –8192 and 8191 are encoded in two bytes, etc.
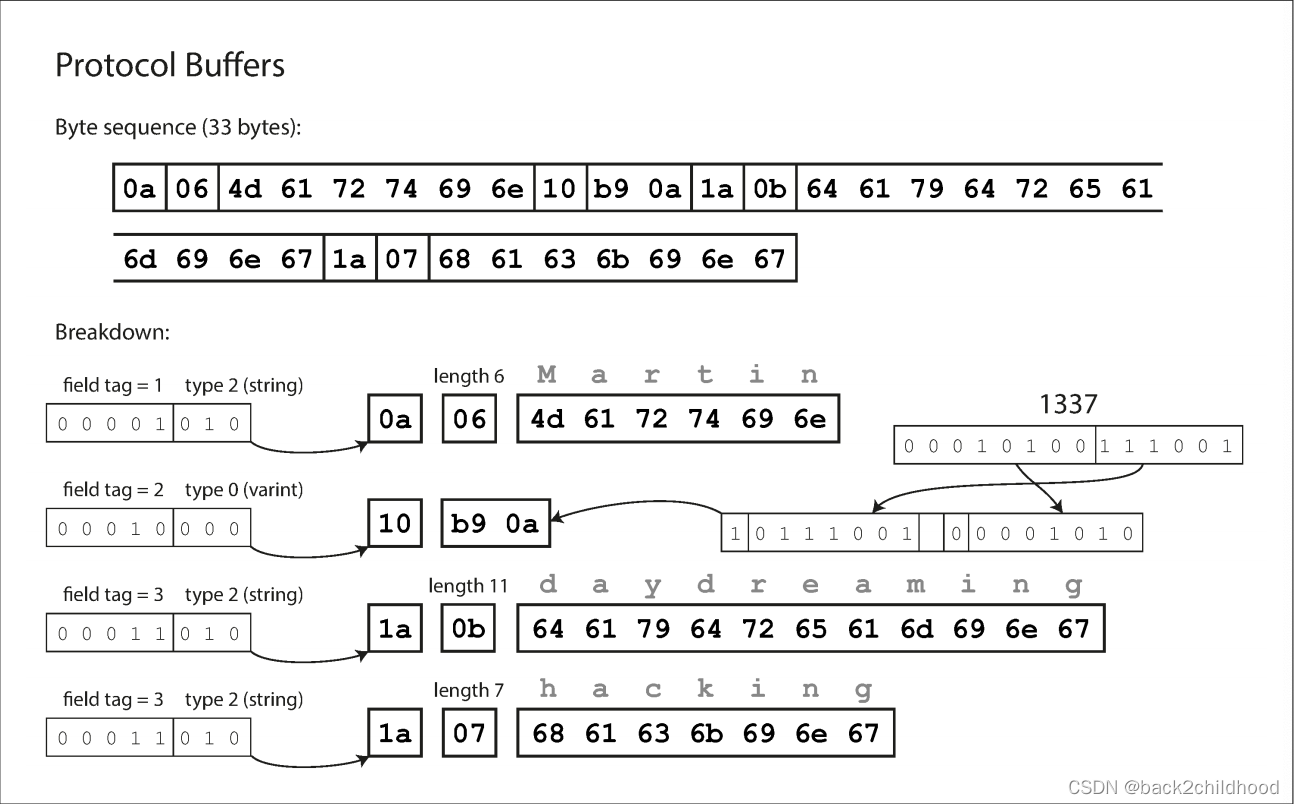
Protocol Buffers
It is similar to Thrift’s CompactProtocol.
in the schemas shown earlier, each field was marked either required or optional, but this makes no difference to how the field is encoded(nothing in the binary data indicates whether a field was required). The difference is simply that required enables a runtime check that fails if the field is not set, which can be useful for catching bugs.
Field tags and schema evolution
How to keep backward and forward compatibility?
- backward compatibility: every field you add after the initial deployment of the schema must be optional or have a default value.
- forward compatibility: only can remove a field that is optional.
Datatypes and schema evolution
However, if old code reads data written by new code, the old code is still using a 32-bit variable to hold the value. If the decoded 64-bit value won’t fit in 32 bits, it will be truncated.
Protocol Buffers is not have a list or array datatype, but instead has a repeated marker for fields.
Thrift has a dedicated list datatype.
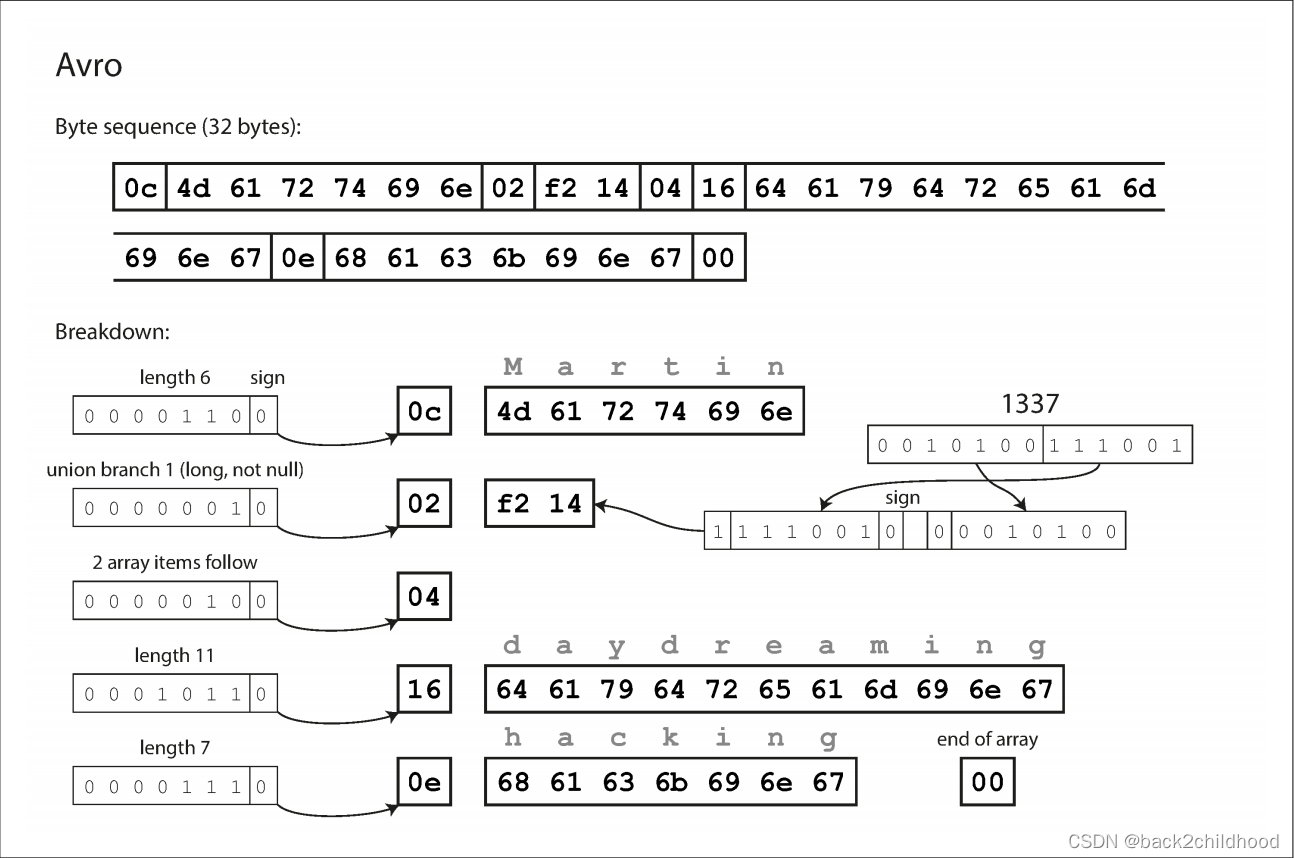
Avro
Avro’s IDL look like this:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
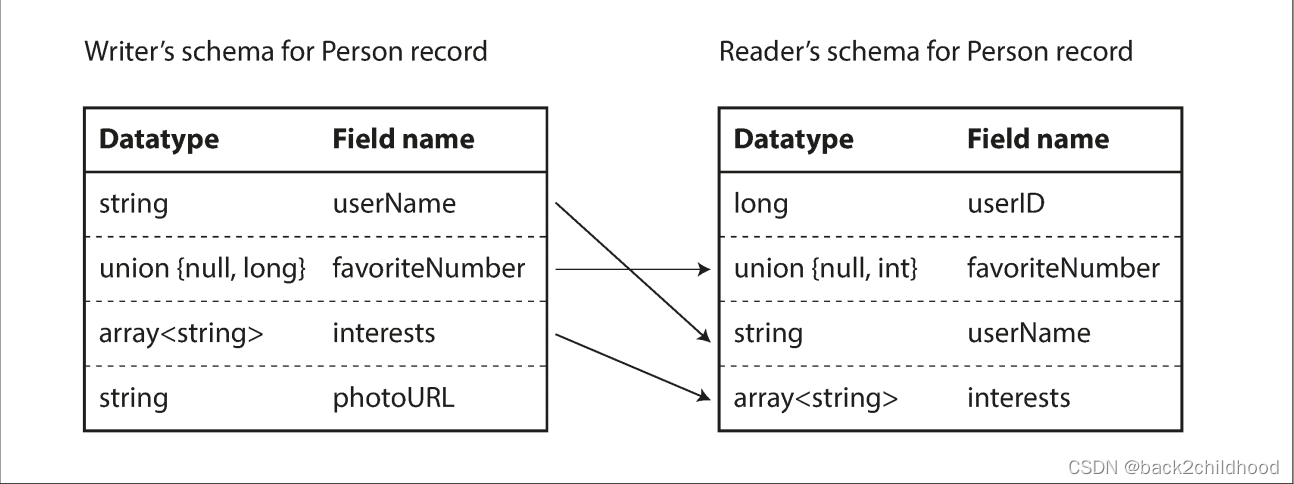
The writer’s schema and the reader’s schema
The Avro library resolves the differences by looking at the writer’s schema and the reader’s schema side by side and translating the data from the writer’s schema into the reader’s schema.
Schema evolution rules
To maintain compatibility, you may only add or remove a field that has a default value.
For example, union { null, long, string } field; indicates that field can be a number, a string, or null.
But what is the writer’s schema?
How does the reader know the writer’s schema?
The answer depends on the context in which Avro is being used. To give a few examples:
- Large file with lots of records
Avro usually stores a large file containing millions of records, in this case, the writer of that file can just include the writer’s schema at the beginning of the file. - Database with individually written records
The simplest solution is to include a version number at the beginning of every encoded record, and to keep a list of schema versions in your database. A reader can fetch a record, extract the version number, and then fetch the writer’s schema for that version number from the database.
Dynamically generated schemas
Avro schema can be easily generated from the relational schema and encode the database contents using that schema. If the database schema changes (for example, a table has one column added and one column removed), you can just generate a new Avro schema from the updated database schema and export data in the new Avro schema.
Code generation and dynamically typed languages
In dynamically typed programming languages such as JavaScript, Ruby, or Python, there is not much point in generating code, since there is no compile-time type checker to satisfy.
Avro provides optional code generation for statically typed programming languages, but it can be used just as well without any code generation.
The Merits of Schemas
Binary encodings have a number of nice properties:
- They can be much more compact than the various “binary JSON” variants, since they can omit field names from the encoded data.
- The schema is a valuable form of documentation, and because the schema is required for decoding, you can be sure that it is up to date (whereas manually maintained documentation may easily diverge from reality).
- Keeping a database of schemas allows you to check forward and backward compatibility of schema changes before anything is deployed.
- For users of statically typed programming languages, the ability to generate code from the schema is useful, since it enables type checking at compile time.
In summary, schema evolution allows the same kind of flexibility as schemaless/schema-on-read JSON databases provide, while also providing better guarantees about your data and better tooling.
Modes of Dataflow
Compatibility is a relationship between one process that encodes the data, and another process that decodes it. In the rest of this chapter, we will explore some of the most common ways how data flows between processes.
- via databases
- via service calls
- via asynchronous message passing
Dataflow Through Databases
It’s common for several processes to be accessing a database at the same time, and those processes might be several instances of the same service. In some cases, such as in a rolling upgrade, some processes will be running newer code and some will be running older code. This means a value may be written by a newer vision and subsequently read by an older version. In order to implement backward compatibility, we can store something in the database as sending a message to your future self.
The desirable behavior is usually for the old code to keep the new field intact, even though it couldn’t be interpreted. However, when you decode a database value into a model object and reencode it, the unknown field might be lost in that translation process.
Different values written at different times
Although you may replace the old version with the new version within a few minutes, it’s an expensive thing to rewrite the data into a new schema. This observation is summed up as data outlives code. Most relational databases allow simple schema changes, such as adding a new column with a null default value.
Archival storage
Perhaps you take a snapshot of your database from time to time, say for backup purposes or for loading into a data warehouse. In this case, the data dump will typically be encoded using the latest schema, even if the original encoding in the source database contained a mixture of schema versions from different eras.
Dataflow Through Services: REST and RPC
A server can itself be a client to another service (for example, a typical web app server scts as client to a database). This way of building applications has traditionally been called a service-oriented architecture(SOA), more recently refined and rebranded as microservices architecture.
A key design goal of a SOA/microservices architecture is to make the application easier to change and maintain by making services independently deployable and evolvable. For example, each service should be owned by one team, and that team should be able to release new versions of the service frequently, without having to coordinate with other teams. In other words, we should expect old and new versions of servers and clients to be running at the same time, and so the data encoding used by servers and clients must be compatible across versions of the service API.
Web services
Several different contexts used web services:
- A client application running on a user’s device making requests to a service over HTTP.
- SOA/microservices architecture: one service makig requests to another service owned by the same organization, often located within the same datacenter.
- One service making requests to a service owned by a different organization via the internet. This is used for data exchange between different organizations’ backend systems.
There are two popular approaches to web services: REST and SOAP
- REST is not a protocol, but also a design philosophy that builds upon the principles of HTTP. REST has been gaining popularity compared to SOAP, at least in the context of cross-organizational service integration, and is often associated with microservices. An API designed according to the principles of REST is called RESTful.
RESTful APIs tend to favor simpler approaches, typically involving less code generation and automated tooling. - SOAP is an XML-based protocol for making network API requests. Although it is most commonly used over HTTP, it aims to be independent from HTTP and avoids using most HTTP features. Instead, it comes with a sprawling and complex multitude of related standards (the web service framework, known as WS-*) that add various features.
The API of SOAP web service is described using an XML-based language called the Web Services Description Language (WSDL). WSDL enables code generation so that a client can access a remote service using local class and method calls(which are encoded to XML messages and decoded again by the framework).
As WSDL is not designed to be human-readable, and as SOAP messages are often too complex to construct manually, users of SOAP rely heavily on tool support, code generation, and IDEs.
The problems with remote procedure calls(RPC)
The RPC model tries to make a request to a remote network service look the same as calling a function or method in your programming language within the same process (this abstraction is called location transparency).
A network request is different from a local function call:
- A local function call is predictable and either succeeds or fails, depending on parameters that are under your control. A network request is unpredictable: the request or response may be lost due to a network problem. We can retry a failed request to anticipate this question.
- A local function call either returns a result, or throws an exception, or never returns (infinite loop). A network request may return without a result due to a timeout. We have no way of knowing whether the request got through or not.
- If you retry a network request, it could happen that the requests are actually getting through and only the responses are getting lost. In that case, retrying will cause the action to be performed multiple times unless you build a mechanism for deduplication (idempotence).
- When you call a local function, it normally take the same time to excute. A network request is much lower than a function call, and its latency is also wildly variable.
- When you make a network request, all those parameters need to be encoded into a sequence of bytes that can be sent over the network.
- The client and the service may be implemented in different programming languages, so the RPC framework must translate datatypes from one language into another.
Current directions for RPC
In this chapter, Thrift and Avro come with RPC support included, gRPC is an RPC implementation using Protocol Buffers, Finagle also uses Thrift, and Rest.li uses JSON over HTTP.
The new generation of RPC framework have some functions different from a local function call.
- Finagle and Rest.li use futures (promises) to encapsulate asynchronous actions that may fail. Futures also simplify situations where you need to make requests to multiple services in parallel and combine their results.
- Some of these frameworks also provide service discovery—that is, allowing a client to find out at which IP address and port number it can find a particular service.
Data encoding and evolution for RPC
We can make a simplifying assumption in the case of dataflow through services: it is reasonable to assume that all the servers will be updated first, and all the clients second. Thus, you only need backward compatibility on requests, and forward compatibility on responses.
The provider of a service has no control over its clients and cannot force them to upgrade. Thus, compatibility needs to be maintained for a long time, perhaps indefinitely.
Message-Passing Dataflow
Asynchronous message-passing systems are somewhere between RPC and databases. They are similar to RPC in that a client’s request (usually called a message) is delivered to another process with low latency. They are similar to databases in that the message is not sent via a direct network connection, but goes via an intermediary called a message broker (also called a message queue or message-oriented middleware), which stores the message temporarily.
Using a message broker has several advantages compared to direct RPC:
- It can improve system reliability by acting as a buffer when the recipient is unavailable or overloaded.
- It can automatically redeliver messages to a process that has crashed, thus prevent messages from being lost.
- It can avoid the sender needing to know the IP address and port number. (In a cloud deployment where virtual machines often come and go).
- It allows one message to be sent to several recipients
- It logically decouples the sender from the recipient (the sender just published messages and doesn’t care who consumes them).
However, a difference compared to RPC is that message-passing communication is usually one-way: a sender normally doesn’t expect to receive a reply to its messages.
Message brokers
More than one process sends a message to a named queue or topic, and the broker ensures that the message is delivered to one or more consumers or subscribers to that topic or queue.
Although a topic provides only one-way dataflow, a consumer may itself publish message to another topic or to a reply queue that is consumed by the sender of the original message.
Message brokers typically don’t enforce any particular data model, a message is just a sequence of bytes with some metadata and you can use any encoding format.
Distributed actor frameworks
The actor model is a programming model for concurrency in a single process. Rather than dealing directly with threads, logic is encapsulated in actors. Each actor typically represents one client or entity, it may have some local state, and it communicates with other actors by sending and receiving asynchronous messages.Message delivery is not guaranteed: in certain error scenarios, messages will be lost.
In distributed actor frameworks, this programming model is used to scale an application across multiple nodes. The same message-passing mechanism is used, no matter whether the sender and recipient are on the same node or different nodes. If they are on different nodes, the message is transparently encoded into a byte sequence, sent over the network, and decoded on the other side.
Summary
In this chapter, we looked at several ways of turning data structures into bytes on the network or bytes on disk. Many services need to support rolling upgrades, it is important that all data flowing around the system is encoded in a way that provides backward compatibility and forward compatibility.
We discussed several data encoding formats and their compatibility properties:
- Programming language-specific encodings are restricted to a single programming language and often fail to provide forward and backward compatibility.
- Textual formats like JSON, XML and CSV are widespread, and their compatibility depends on how you use them.
- Binary schema-driven formats like Thrift, Protocol Buffers and Avro allow compact, efficient encoding with clearly defined forward and backward compatibility semantics.
We discussed several modes of dataflow:
- Databases, where the process writing to the database encodes the data and the process reading from the database decodes it.
- RPC and REST APIs, where the client encodes a request, the server decodes the request and encodes a response, and the client finally decodes the response.
- Asynchronous message passing (using message brokers or actors), where nodes communicate by sending each other messages that are encoded by the sender and decoded by the recipient.















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









