







A New Comprehensive Benchmark for Semi-supervised Video Anomaly Detection and Anticipation 论文阅读
文章信息:

发表于:CVPR2023
文章链接:https://openaccess.thecvf.com/content/CVPR2023/html/Cao_A_New_Comprehensive_Benchmark_for_Semi-Supervised_Video_Anomaly_Detection_and_CVPR_2023_paper.html
源码:https://github.com/zugexiaodui/campus_vad_code
Abstract
半监督视频异常检测(VAD)是智能监控系统中的关键任务。然而,在VAD中一种名为场景相关异常的基本类型的异常并没有得到研究人员的关注。此外,目前还没有研究探讨异常预测,这是一个更重要的任务,用于预防异常事件的发生。为此,我们提出了一个新的综合数据集,NWPU Campus,包含43个场景,28类异常事件和16小时的视频。目前,它是最大的半监督VAD数据集,具有最多的场景和异常类别,最长的持续时间,并且是唯一考虑到场景相关异常的数据集。同时,它也是第一个用于视频异常预测的数据集。我们进一步提出了一种新颖的模型,能够同时检测和预测异常事件。与近年来7种优秀的VAD算法相比,我们的方法在处理场景相关异常检测和异常预测方面表现良好,在ShanghaiTech、CUHK Avenue、IITB Corridor以及新提出的NWPU Campus数据集上始终达到了最先进的性能。我们的数据集和代码可在以下网址获取:https://campusvad.github.io。
1. Introduction
总之,我们的贡献有三个方面:
- 我们提出了一个新的数据集NWPU Campus,这是迄今为止最大,最复杂的半监督视频异常检测基准。它弥补了目前研究领域中场景依赖异常的不足。
- 我们提出了一个新的视频异常预测任务,提前预测异常事件的发生,NWPU Campus也是第一个提出的异常预测数据集,填补了这方面的研究空白。
- 我们提出了一种新颖的方法,可以同时检测和预测异常事件,并且可以处理场景相关的异常。在NWPU Campus、ShanghaiTech、CUHK Avenue和IITB Corridor数据集上,与7种最先进的VAD方法进行比较,结果表明我们的方法的优越性。
4. Proposed Method
4.1. Problem Formulation
视频异常检测(VAD)旨在检测当前时刻是否发生异常。至于异常预测,考虑到预测异常事件发生的确切时间既困难又不必要,我们定义视频异常预测(VAA)为预测未来一段时间内是否会发生异常,这对异常事件的早期预警具有意义和用处。我们在图3中说明了VAD和VAA任务。
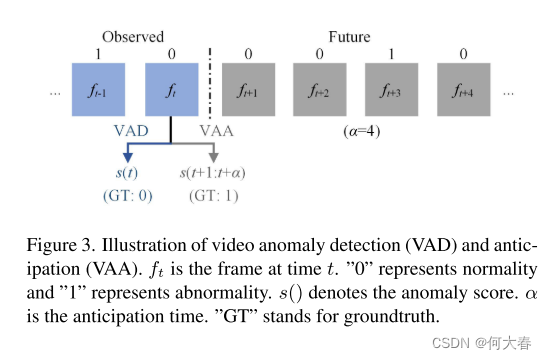
假设当前时间步为
t
t
t。对于VAD,算法可以基于观察到的帧
f
t
−
n
,
…
,
f
t
f_{t-n}, \ldots, f_t
ft−n,…,ft 计算当前帧
f
t
f_t
ft 的异常分数
s
(
t
)
s(t)
s(t),其中
n
n
n 表示观察持续时间。在图3中,
f
t
f_t
ft 是正常帧,因此预期异常分数
s
(
t
)
s(t)
s(t) 应尽可能低。
对于VAA,在当前时刻 t t t,我们预测在尚未观察到的时间段 [ t + 1 , t + α ] [t + 1, t + α] [t+1,t+α] 中是否会发生异常,其中 α ≥ 1 α ≥ 1 α≥1 是预测时间。我们使用得分 s ( t + 1 : t + α ) s(t + 1 : t + α) s(t+1:t+α) 表示在 t + 1 t + 1 t+1 到 t + α t + α t+α 帧期间发生异常的预期概率。在图3中,取 α = 4 α = 4 α=4 作为示例,由于 f t + 3 f_{t+3} ft+3 是异常的,因此 s ( t + 1 : t + α ) s(t + 1 : t + α) s(t+1:t+α) 的真实值为 1,表示在帧 f t + 1 , … , f t + 4 f_{t+1}, \ldots, f_{t+4} ft+1,…,ft+4 中将会出现异常。我们期望异常分数 s ( t + 1 : t + α ) s(t + 1 : t + α) s(t+1:t+α) 尽可能高,这与 s ( t ) s(t) s(t)相反。
正如可以看到的那样,对于VAD和VAA,其地面真实标签是不同的。对于VAD,我们将视频的帧级标签表示为
G
0
=
{
g
t
}
t
=
1
T
G_0 = \{g_t\}^T_{t=1}
G0={gt}t=1T,其中
g
t
g_t
gt ∈ {
0
,
1
0, 1
0,1} 表示帧
f
t
f_t
ft 是正常(0)还是异常(1),而
T
T
T 是视频的长度。基于
G
0
G^0
G0,可以通过以下方式计算帧级标签,其中预测时间为
α
α
α 的VAA:
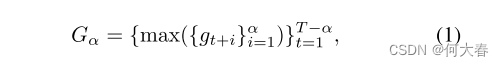
其中
m
a
x
(
)
max()
max()表示集合中的最大值。
请注意,动作预测模型(例如[41-43])不适用于半监督的VAA,因为没有异常数据和标签可以以监督方式训练它们。因此,我们在下一节提出了一种新颖的半监督VAD和VAA方法。
4.2. Forward-backward Scene-conditioned Autoencoder
我们的模型基于普遍的帧预测模型。然而,在VAA中,未来的真实帧是不可见的,因此无法计算预测误差。为了解决这个问题,我们提出通过前向-后向预测来估计未来帧的预测误差,所提出的模型如图4所示。

此外,我们提议采用场景条件自编码器来处理场景相关的异常。具体来说,我们将场景图像的编码作为条件输入到条件变分自编码器(CVAE)中,训练它生成与场景相关的图像特征,最后将这些特征解码成预测帧。
4.2.1 Forward-backward Frame Prediction
如图4所示,我们的模型包括一个前向和一个后向帧预测网络。前向网络基于观察到的帧一次性预测多个未来帧,而后向网络则根据前向网络生成的未来帧和部分观察到的帧逆向预测观察到的帧。我们的动机是,如果在前向预测中未来帧是异常的,那么预测的图像将不准确。当我们将不准确的图像作为后向帧预测模型的一部分输入时,输出帧与已观察到的地面真实帧之间也会有很大的误差。因此,我们可以通过前向-后向帧预测的误差来预测未来的异常情况。
在当前时间步 t,前向网络将观察到的帧
f
t
−
n
,
…
,
f
t
−
1
f_{t-n}, \ldots, f_{t-1}
ft−n,…,ft−1 作为输入,并输出预测的帧
f
^
t
,
…
,
f
^
t
+
α
\hat{f}_t, \ldots, \hat{f}_{t+\alpha}
f^t,…,f^t+α。我们计算每个预测帧
f
^
t
+
i
(
i
∈
[
0
,
α
]
)
\hat{f}_{t+i} (i ∈ [0, \alpha])
f^t+i(i∈[0,α]) 与其真实帧之间的均方误差
(
M
S
E
)
(MSE)
(MSE)损失和
λ
L
1
\lambda_{L1}
λL1 损失,用于训练前向网络:
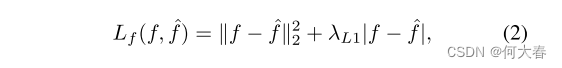
其中
λ
L
1
\lambda_{L1}
λL1是
L
1
L1
L1损失的权重。
为了训练反向网络,即预测第 i 个(
i
∈
[
1
,
α
]
i ∈ [1, \alpha]
i∈[1,α])未来帧的异常分数,我们分别将预测的未来帧
f
^
t
+
i
,
…
,
f
^
t
+
1
\hat{f}_{t+i}, \ldots, \hat{f}_{t+1}
f^t+i,…,f^t+1 和真实未来帧
f
t
+
i
,
…
,
f
t
+
1
f_{t+i}, \ldots, f_{t+1}
ft+i,…,ft+1,分别与观察到的帧
f
t
f_{t}
ft,
…
,
f
t
+
i
+
1
−
n
\ldots, f_{t+i+1-n}
…,ft+i+1−n 输入其中。通过这种方式,我们的反向网络可以利用观察到的信息进行更准确的短期异常预测。这两种形式的输入输出的预测帧分别表示为
f
^
t
+
i
−
n
(
1
)
\hat{f}^{(1)}_{t+i-n}
f^t+i−n(1) 和
f
^
t
+
i
−
n
(
2
)
\hat{f}^{(2)}_{t+i-n}
f^t+i−n(2),它们共享相同的地面真实帧
f
t
+
i
−
n
f_{t+i-n}
ft+i−n。我们计算
f
^
t
+
i
−
n
(
1
)
\hat{f}^{(1)}_{t+i-n}
f^t+i−n(1) 与
f
t
+
i
−
n
f_{t+i-n}
ft+i−n,以及
f
^
t
+
i
−
n
(
2
)
\hat{f}^{(2)}_{t+i-n}
f^t+i−n(2) 与
f
t
+
i
−
n
f_{t+i-n}
ft+i−n 之间的平均均方误差(MSE)和
L
1
L1
L1 损失,用于训练反向网络:
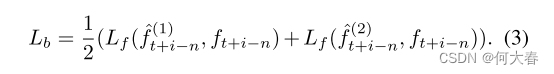
在推断过程中,只需要预测的前向未来帧
f
^
t
+
i
,
…
,
f
^
t
+
1
\hat{f}_{t+i}, \ldots, \hat{f}_{t+1}
f^t+i,…,f^t+1 和观察到的帧
f
t
,
…
,
f
t
+
i
+
1
−
n
f_{t}, \ldots, f_{t+i+1-n}
ft,…,ft+i+1−n 进行反向预测。对于不同的时间步
t
+
1
,
…
,
t
+
α
t+1, \ldots, t+\alpha
t+1,…,t+α,反向网络共享相同的权重。
4.2.2 Scene-conditioned VAE
前向和后向网络都是相同架构的三级UNets [44],包含了指导输入帧编码与场景相关的CVAEs。输入帧在时间和通道维度上合并,然后被馈送到2D卷积网络的编码器中,该编码器输出三个不同形状的特征图。U2和U3级别的特征图被馈送到CVAEs中,以生成受场景图像条件约束的新特征图。然后,场景条件特征图以权重 γ ∈ [ 0 , 1 ] γ ∈ [0, 1] γ∈[0,1]添加到CVAEs的输入中。最后,通过后续的解码卷积层生成预测帧。
一个CAVE接受帧的特征图和场景图像的编码作为输入。需要注意的是,帧只关注检测到对象的局部区域,而场景图像中的对象被掩盖并且只保留了背景。场景图像通过卷积层编码,与帧特征图拼接后被送入CVAE的编码器,以生成后验分布的参数。我们使用再参数化技术 [45] 从后验分布中采样潜在变量,并在与场景编码拼接后送入CVAE解码器以生成场景条件的特征图。我们假设先验分布是标准高斯分布,并计算其与后验分布之间的Kullback-Leibler (KL) 散度作为损失。
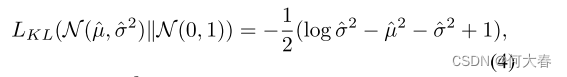
其中,
µ
^
\hatµ
µ^ 和
σ
^
2
\hatσ^2
σ^2 是后验高斯分布的均值和方差。在测试阶段,如果输入的特征图与场景不匹配,它们将被CVAE重建,由于存在较大的误差,因此可以识别出场景相关的异常。
最后,总损失是前向预测、后向预测和KL散度损失的加权和,其中KL散度的权重为 λ K L λ_{KL} λKL。我们最小化总损失来共同训练整个模型。
4.2.3 Anomaly Score
在推断过程中,我们通过公式(2)计算预测的前向帧
f
^
t
\hat{f}_t
f^t 与其真实帧
f
t
f_t
ft 之间的误差作为VAD的异常分数。

对于具有预测时间
α
α
α 的 VAA,我们首先通过前向后向预测来估计
f
t
+
i
(
i
∈
[
1
,
α
]
)
f_{t+i}(i ∈ [1, α])
ft+i(i∈[1,α])的异常分数。然后,在
[
t
+
1
,
t
+
α
]
[t + 1, t + α]
[t+1,t+α] 时间段内的最大误差被视为预测的异常分数。
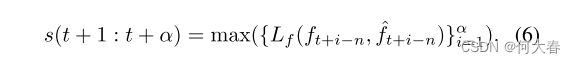
因此,我们可以同时检测和预测异常。
5. Experiments
5.1. Experimental Setup
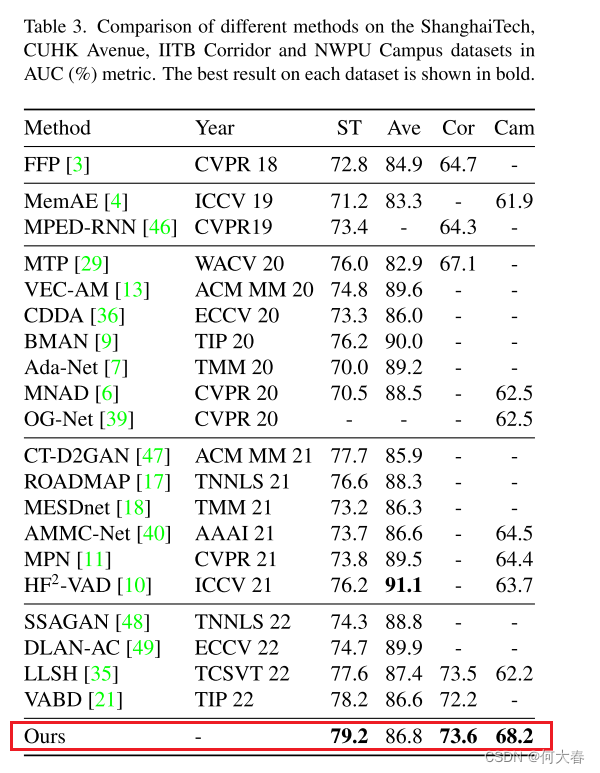
Datasets.我们在ShanghaiTech[23],Avenue [27],IITB Corridor[29]以及我们提出的NWPU Campus数据集上进行实验,这些数据集在表1和相关工作部分中有描述。我们的数据集将在双盲评审后发布。为了方便起见,我们在下表中将上述数据集分别缩写为“ST”,“Ave”,“Cor”和“Cam”。
Evaluation Metric.我们使用受试者工作特征(ROC)曲线下的面积(AUC)来评估VAD和VAA的性能。请注意,我们将数据集中的所有帧连接起来,然后计算整体帧级AUC,这是被广泛采用的。
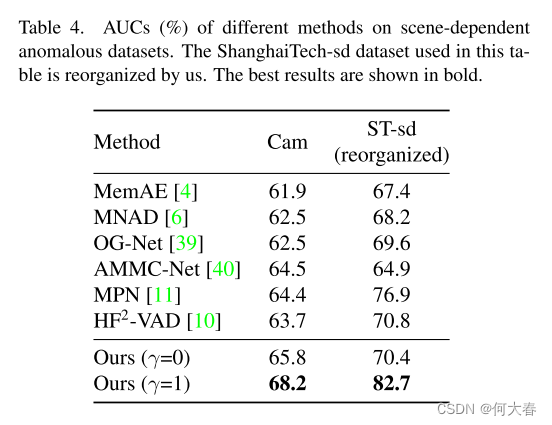
Implementation Details.我们模型的输入帧是由预训练的ByteTrack [50]检测到的对象周围的256×256像素区域。对于前向和后向网络,它们都将 T i n T_{in} Tin=8帧作为输入,而它们的输出分别是Tout=7帧和Tout=1帧。前向网络输出的第一帧用于异常检测,第二到第七帧被送入后向网络,用于不同预测时间的异常预测。我们基于ResNet [52]设计了U-Net的编码器,解码器是多个卷积层。场景编码网络是一个分类模型,用于对场景进行分类,首先使用已知的场景信息进行训练,然后在训练整个模型期间冻结。默认情况下,权重 γ γ γ, λ L 1 λ_{L1} λL1和 λ K L λ_{KL} λKL分别为1, 1和0.1。我们采用最大局部误差 [53] 来关注局部区域的误差。有关我们模型的详细描述,请参阅补充材料。
只贴部分实验结果:
Conclusion
在这项工作中,
-
我们提出了一个新的综合数据集 NWPU Campus,它是半监督视频异常检测中最大的数据集,也是唯一考虑到场景相关异常的数据集,并且是首个用于视频异常预测(VAA)的数据集。
-
我们定义了 VAA,用于预测未来一段时间内是否会发生异常事件,这对于异常事件的及早警告非常重要。
-
此外,我们提出了一种前向-后向的场景条件模型,用于 VAD 和 VAA,并且处理了场景相关的异常情况。
-
未来,我们的研究重点不仅会放在短期 VAA 上,还会关注长期预测。
总结
- 制作了一个新的数据集
- 开创了一个新的领域
- 提出了一个前向后向的场景条件模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









