







ReFLIP-VAD: Towards Weakly Supervised Video Anomaly Detection via Vision-Language Model
ReFLIP-VAD: Towards Weakly Supervised Video Anomaly Detection via Vision-Language Model 论文阅读
文章信息:

发表于:TCSVT (中科院一区)
原文链接:https://ieeexplore.ieee.org/abstract/document/10723764
源码:https://github.com/prasaddev97/ReFLIP-VAD
阿三抄抄就能发1区了,还好意思开源代码,被他玩明白了
Abstract
视觉语言模型最近在与图像相关的任务中取得了显著的成功,展示了其学习深刻且有意义视觉表示的能力。将这种强大的模型应用于视频分析以检测异常仍然是一个显著的挑战。本文提出了重参数化细粒度语言图像预训练-视频异常检测(ReFLIP-VAD),这是一种旨在利用视觉语言能力进行视频异常检测的新颖方法。ReFLIP-VAD 采用提示编码器生成重参数化的可学习提示模板,增强了对异常相关语义的可解释性和理解能力。 该框架采用双模块架构:一个分类模块利用视觉特征进行二分类,一个视频-文本对齐模块将文本和视觉特征结合以实现精确的语言-视觉对齐。该方法通过 Glimpse-Emphasize 网络进一步增强,有效捕获跨时间的全局和局部时序依赖性,并通过 MIL-Align 机制选择每个标签最具代表性的视频帧来代表整个视频。 ReFLIP-VAD 在两个大规模基准数据集上展示了卓越的性能,在 XD-Violence 数据集上取得了 86.29% 的平均精度(AP),在 UCF-Crime 数据集上实现了 89.14% 的曲线下面积(AUC),显著超过了现有的最新方法。
I. INTRODUCTION
视频异常检测(VAD)任务在包括但不限于公共监控、交通管理、交通监测以及军事场景等实际应用中,近年来受到了广泛关注。该任务主要通过三种范式进行研究,即全监督 VAD(FSVAD)[1]、无监督 VAD(USVAD)[2] 和弱监督 VAD(WSVAD)[3]。传统的 FSVAD 被认为不切实际,因为分散且多样化的异常需要大量人工逐帧标注。相反,无监督 VAD 仅依赖正常视频进行学习以识别开放集异常,往往会产生误报。然而,在仅提供正常视频的情况下,缺乏先验知识使得区分正常与异常本质上非常困难。相比 FSVAD 和 USVAD,我们的主要研究重点是更具实用性的 WSVAD 范式,它仅依赖视频级别的标注,从而降低了人工和详细标注的成本。
当前在视频异常检测(VAD)领域的研究通常遵循一种系统化的方法。首先,使用视觉主干模型(如 C3D [4], [5]、I3D [6], [7]、ViT [8])提取纯视觉特征,这些模型通常预训练于动作识别任务。提取的特征随后被输入基于多实例学习(MIL)框架的二分类器 [9]。最后一步通过预测的异常置信度来检测异常事件。尽管这些直接的方法展示了一定的潜力,但它们未能充分利用视觉与语言之间的跨模态连接。
近年来,视觉语言模型取得了显著进展,例如对比语言-图像预训练(CLIP)[10]、大规模图像与噪声文本嵌入(ALIGN)[11]、上下文优化(CoOp)[12] 和细粒度语言-图像预训练(FLIP)[13]。这些模型旨在获取具有语义概念的通用视觉表示。CLIP 的核心思想是通过对比学习将图像和文本对齐到一个共享的嵌入空间,使其能够将图像与文本描述关联,并执行各种涉及视觉和语言的任务。鉴于视觉语言模型近年来的显著成功,人们对基于 CLIP 构建特定任务模型的探索兴趣日益增长。
尽管视觉语言模型(VLMs)在多种视觉任务中展现了明显的潜力,其主要关注点仍集中在静态图像领域。因此,深入研究如何将基于图像-文本对训练的模型有效转换为能够在有限监督下应对更复杂的视频异常检测挑战的工具显得尤为重要。为了有效利用通用知识并使 FLIP 在弱监督视频异常检测(WSVAD)任务中发挥其全部潜力,必须解决与 WSVAD 特性相关的特定挑战。首先,探索跨时间捕获上下文依赖性的方法至关重要。其次,研究如何利用已有知识并增强视觉-语言连接至关重要。第三,确保视觉语言模型在视频异常检测场景中的性能同样至关重要。
本文的主要贡献如下:
- 提出了一种新颖的框架 ReFLIP-VAD,该框架采用提示编码器生成重参数化的可学习提示模板,而非手工设计的模板。这些模板具有丰富的上下文信息,增强了可解释性,并对与异常相关的特定语义提供了更深入的理解。
- 所提出的方法包括一个分类模块和一个视频-文本对齐模块。分类模块利用视觉特征进行二分类,而视频-文本对齐模块结合文本和视觉特征实现语言与视觉的对齐。因此,这种基于双模块的方法能够在粗粒度和细粒度水平上检测视频异常。
- 提出了一种 Glimpse-Emphasize 网络,可以有效捕获跨时间的全局和局部时序依赖关系。同时,还开发了 MIL-Align 机制,以在弱监督条件下优化视觉-语言对齐。
- ReFLIP-VAD 的有效性在两个大规模基准上得到了验证。ReFLIP-VAD 达到了最先进的性能,包括在 XD-Violence 数据集上取得 86.29% 的平均精度(AP)和在 UCF-Crime 数据集上实现 89.14% 的曲线下面积(AUC),大幅超越了现有的最先进方法。
本文其余部分结构如下:第二部分讨论了视频异常检测的最先进方法以及如何将视觉语言模型应用于视频异常检测。第三部分描述了所提出的方法论,能够有效实现粗粒度和细粒度的视频异常检测。第四部分展示了在 UCF Crime 和 XD-Violence 数据集上的实验结果和讨论。第五部分总结并讨论了未来的研究方向。
II. RELATED WORK
A. Video Anomaly Detection
-
无监督视频异常检测(USVAD):随着深度学习技术的出现,视频异常检测经历了革命性的转变。利用卷积神经网络 [18]–[20]、循环神经网络 [21]、[22] 和变压器 [23]、[24] 的方法逐渐成为该领域研究的主要焦点。Peng 等人 [18] 提出了一个深度单阶段神经网络,通过使用堆叠卷积编码器生成低维的高层次表示,以实现最大的紧凑性。此外,他们还结合了一个解码器,从这些低维表示中重建原始样本。通过采用代理任务学习,Liu 等人 [19] 引入了一个时空记忆增强的自编码器。基于这一结构,研究人员 [25]、[26]、[27] 开发了视频预测网络,分别学习外观和运动的正常性,以预测异常。Zhong 等人 [28] 利用级联结构,结合像素重建和光流预测来增强异常检测。Zeng 等人 [29] 使用图卷积神经网络来检测与人类相关的异常。Jin 等人 [23] 利用变压器学习所有视频帧之间的判别时序特征。Zhong 等人 [30] 开发了基于注意力的特征融合模块,整合前向和后向时空特征,并利用误差金字塔和均值池化进行异常评估,有效地检测复杂场景中不同大小的物体。Li 等人 [31] 利用多分支生成对抗网络来检测异常事件。
-
弱监督视频异常检测(WSVAD):弱监督视频异常检测方法受到了越来越多的关注,特别是在 Sultani 等人 [9] 引入弱监督多实例学习(MIL)框架后。他们将每个视频概念化为一个袋子,其中其片段代表袋子中的实例。该框架基于这样一个前提生成结果:正袋(异常视频)中实例的异常评分应高于负袋(正常视频)中的评分,利用视频级别的注释和排名损失函数。因此,许多研究工作沿着这个方向展开,吸引了研究界的关注。Zhong 等人 [32] 使用图卷积神经网络纠正视频异常检测中的标签噪声。Lv 等人 [33] 提出了一个定位框架,通过采用高级上下文信息模块进行异常定位。Tian 等人 [34] 通过利用自注意力网络和膨胀卷积来捕获短期和长期时序依赖性,开发了一个强大的时序特征幅度学习框架。Huang 等人 [35] 提出了一个时序特征聚合器,用于建模视频片段之间的时序关系。此外,他们还结合了一个判别特征编码器用于特征区分。Liu 等人 [36] 通过引入协同学习模块获取深度判别特征。Chen 等人 [37] 应用幅度对比损失,有效地捕获正常视频和异常视频之间的特征可分性。Fan 等人 [38] 提出了一个片段级注意机制,有效地定位监控视频中的异常事件。
B. Vision-Language Model (VLM)
视觉语言模型因其能够弥合视觉数据与自然语言之间的鸿沟而受到计算机视觉领域的广泛关注。早期的视觉语言模型(VLMs)主要聚焦于图像应用,如图像分类 [12]、场景文本检测 [39] 和图像描述生成 [40]。最近,Xu 等人 [41] 将 VLM 从图像扩展到视频领域,通过对比时间相关的视频-文本对,展示了其在视频任务中的强大零样本能力。Ju 等人 [15] 开发了一个简单的基线模型,通过学习任务特定的提示模板,提升了动作识别任务的效率。Zanella 等人 [42] 利用 CLIP 的潜在特征空间识别正常事件,并建立了基于文本驱动的向量用于检测异常。Wu 等人 [16] 对冻结的 CLIP 模型进行了适配,有效地将预训练的语言视觉知识迁移到弱监督视频异常检测(WS-VAD)中。Yang 等人 [43] 提出了一种新颖的框架,利用 CLIP 模型将视频事件描述文本与对应的视频帧进行对齐,并通过微调、可学习的文本提示和正常性引导改进伪标签生成和自监督学习。Wu 等人 [44] 针对开放词汇视频异常检测提出了一种新范式,利用 CLIP 模型改进了已知和未知异常的检测和分类。
从相关工作中发现基于视觉语言模型的视频异常检测方法存在以下不足:
- 尽管现有方法具有一定的效果,但它们未能有效捕获视频中的动态和时序依赖关系。为了解决这一挑战,我们引入了 Glimpse 和 Emphasize 网络(详见第 III-C 节)。
- 当前的最先进方法未能充分利用视觉特征与语言特征之间的联系,导致性能不够理想。为了解决这一局限性,我们提出了一个双模块结构,其中一个分支专注于视觉特征的粗粒度二分类,另一个分支结合视觉和文本特征进行细粒度异常检测(详见第 III-D 和 III-E 节)。
- 现有方法依赖于手工设计或可学习的提示,但这些方法不足以捕获细微的异常。为了解决这一问题,我们引入了重新参数化的可学习提示(详见第 III-F 节)。
III. METHODOLOGY
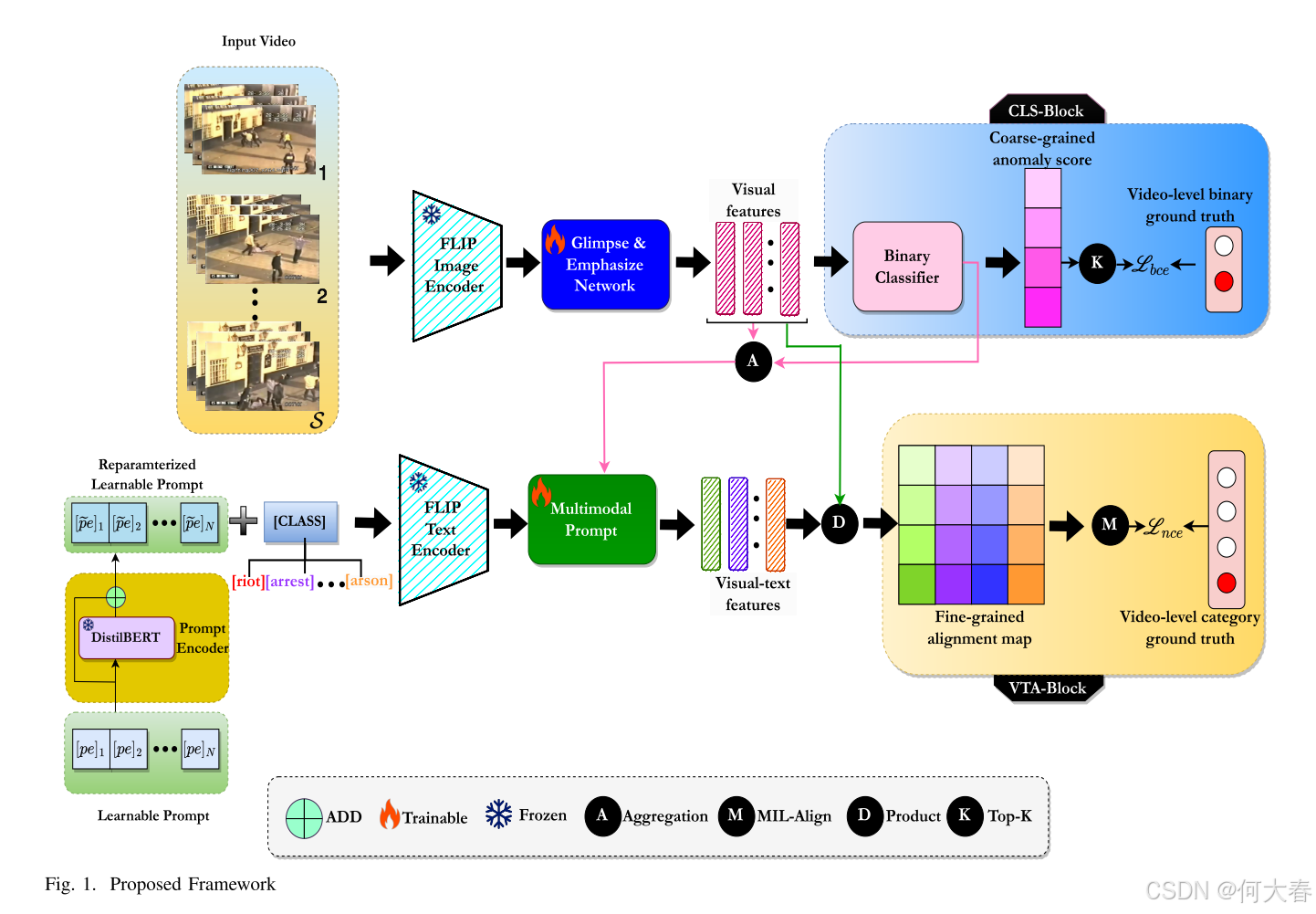
本节详细描述了所提出的 ReFLIP-VAD 方法,该方法旨在解决第 II-B 节中讨论的不足。第 III-A 节定义了弱监督视频异常检测的问题形式化。第 III-B 节概述了视觉特征和文本特征的提取过程。第 III-C 节介绍了 Glimpse 和 Emphasize 网络,展示了如何有效捕获全局和局部上下文信息。第 III-D 和 III-E 节分别描述了分类模块和视频-文本对齐模块。第 III-F 节引入了一种基于 DistilBERT 编码器的新型重新参数化可学习提示。第 III-G 节阐述了视觉嵌入和文本嵌入的融合方式。最后,描述了粗粒度与细粒度对齐以及一种新颖的特征幅值可分性损失函数。图 1 展示了所提出方法的整体框架。
打断
不想看了,抄袭也不是这样抄的,除了Reparameterized Learnable Prompt稍微有点不一样,其他和VadClip全一样。怎么好意思开源的

















 8500
8500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









