







SFC: Shared Feature Calibration in Weakly Supervised Semantic Segmentation 论文阅读
文章信息:

发表于:AAAI2024
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/28584
源码:https://github.com/Barrett-python/SFC
Abstract
图像级弱监督语义分割因其低标注成本而受到越来越多的关注。现有方法主要依赖于类激活映射(Class Activation Mapping, CAM)来生成伪标签,用于训练语义分割模型。在本研究中,我们首次揭示了训练数据中的长尾分布会导致通过分类器权重计算的CAM在头部类别上过度激活,而在尾部类别上激活不足,这主要是由于头部和尾部类别之间共享特征的存在。这种情况会降低伪标签的质量,并进一步影响最终的语义分割性能。为了解决这一问题,我们提出了一种用于CAM生成的共享特征校准(Shared Feature Calibration, SFC)方法。具体来说,我们利用承载正共享特征的类别原型,并提出了一种多尺度分布加权(Multi-Scaled Distribution-Weighted, MSDW)一致性损失,以在训练过程中缩小通过分类器权重和类别原型生成的CAM之间的差距。MSDW损失通过校准头部/尾部类别分类器权重中的共享特征,平衡了过度激活和激活不足的问题。实验结果表明,我们的SFC方法显著改善了CAM的边界质量,并在性能上达到了新的当前最优状态(state-of-the-art)水平。
Introduction
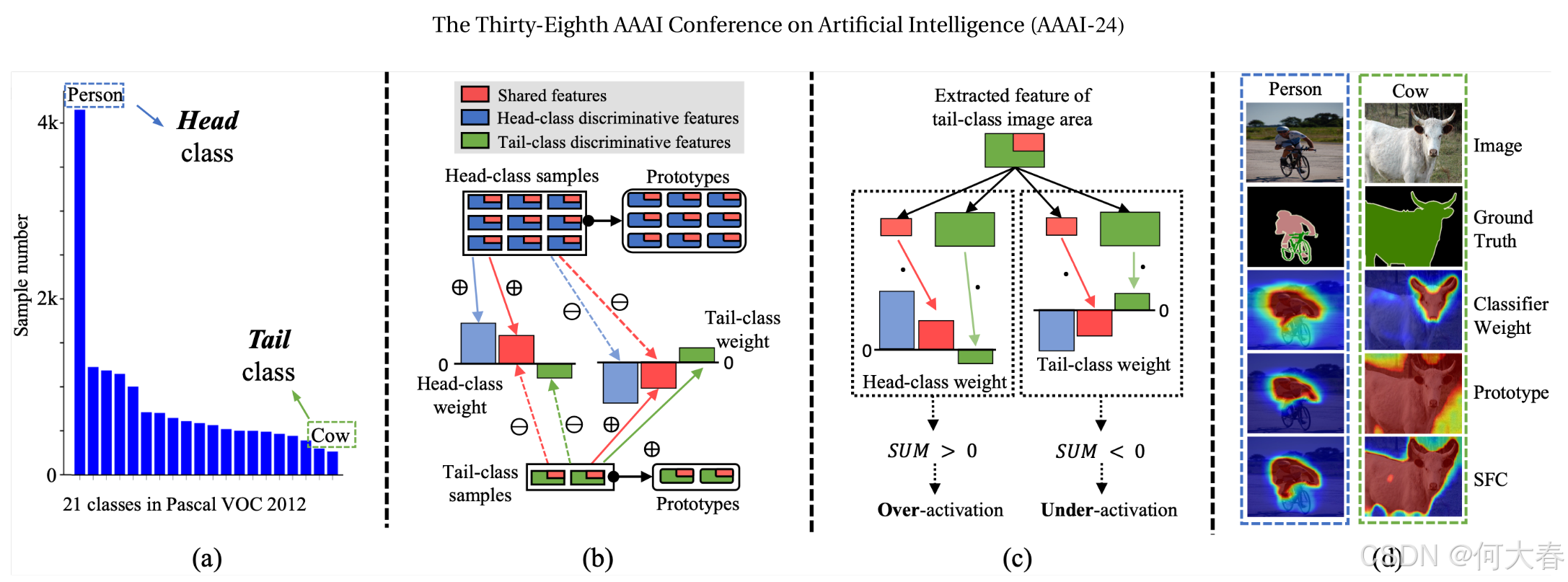
图 1:展示了共享特征在长尾场景下如何影响 CAM 以及我们提出的 SFC 的效果。(a) 显示了 Pascal VOC 2012 数据集 (Everingham 等人, 2010) 是一个天然长尾分布的数据集。(b) 解释了头类和尾类分类器权重及原型中的共享特征组成。( c) 展示了过度激活和欠激活是如何发生的。(d) 显示了头类和尾类样本的 CAM。我们的 SFC 通过适当的激活区域实现了更好的效果。
语义分割(Minaee 等,2021)通过为图像像素分配语义标签,在自动驾驶、机器人等应用领域中起着至关重要的作用(Zhang 等,2022)。然而,为训练深度学习模型获取准确的像素级标注是一个既费时又费力的过程。一种替代方案是采用仅依赖图像级标签的弱监督语义分割(Weakly Supervised Semantic Segmentation, WSSS)(Ahn, Cho, and Kwak 2019; Wang 等,2020; Zhang 等,2020; Lee, Kim, and Yoon 2021; Xu 等,2022; Zhang 等,2023a, 2021a)。通常,这些方法利用类激活映射(Class Activation Mapping, CAM)(Zhou 等,2016)从分类模型中生成具有辨别力的语义掩码。然后,通过一系列后处理方法(Kr¨ahenb¨uhl 和 Koltun,2011)对掩码进行优化,获得像素级伪标签,最后利用这些伪标签来训练语义分割模型(Chen 等,2016)。
然而,我们发现弱监督语义分割(WSSS)的训练数据通常呈现长尾分布(如图1(a)所示)。这种分布导致共享特征成分(Li 和 Monga,2020)在头部类别分类器权重中倾向为正,而在尾部类别分类器权重中倾向为负。这是因为头部类别的权重接收到的正梯度(标记为⊕)多于负梯度(标记为⊖),而尾部类别的权重则接收到更多负梯度而非正梯度(如图1(b)所示)。因此,包含共享特征的像素会被头部类别分类器权重激活(即特征和权重的点积 > 0),而包含尾部类别特征的像素不会被尾部类别权重激活(即特征和权重的点积 < 0),如图1( c)所示。这使得通过分类器权重计算的CAM不可避免地在头部类别上过度激活,而在尾部类别上激活不足(如图1(d)所示)。这一问题降低了伪标签的质量,进而影响了最终的WSSS性能。另一方面,如图1(d)所示,由头部类别原型(Chen 等,2022a)激活的CAM相较于由头部类别分类器权重激活的CAM,其激活程度更低;而由尾部类别原型激活的CAM则相比尾部类别分类器权重激活的CAM,其激活程度更高。
受上述发现的启发(在主要论文的 SFC 分析部分提供了详细的理论分析),我们提出了一种共享特征校准(Shared Feature Calibration, SFC)方法,用于减少头类分类器权重中的共享特征比例,同时增加尾类分类器权重中的共享特征比例,从而避免共享特征引起的过度或不足激活问题。具体来说,我们在通过类原型和分类器权重生成的 CAM 上计算多尺度分布加权(Multi-Scaled Distribution-Weighted, MSDW)一致性损失,其中针对某一类别的一致性损失幅度根据该类别与其他类别之间的样本数量差异进行重新加权。这种重新加权策略背后的理论也得到了验证,证明通过我们的 SFC 方法可以生成具有更好边界的伪标签。本工作的贡献包括:
- 我们首先指出,在长尾场景下,头类和尾类共享的特征可能会扩大由分类器权重生成的头类 CAM,同时缩小尾类的 CAM。
- 我们提出了一种共享特征校准(SFC)CAM 生成方法,旨在平衡不同分类器权重中的共享特征比例,从而提升 CAM 的质量。
- 我们的方法在 Pascal VOC 2012 和 COCO 2014 数据集上仅使用图像级标签,达到了新的弱监督语义分割(WSSS)性能的最新水平。
Related Works
Weakly Supervised Semantic Segmentation
在 WSSS 中,伪标签的生成基于注意力映射 (Wang 等人, 2020; Zhang 等人, 2021a)。关键步骤是生成高质量的 CAM (Sun 等人, 2020; Yoon 等人, 2022)。一些工作设计了启发式方法,例如擦除和累积 (Zhang 等人, 2021b; Yoon 等人, 2022),以迫使网络挖掘新的区域,而不仅仅专注于判别性区域。此外,还提出了包括自监督学习 (Wang 等人, 2020; Chen 等人, 2022a)、对比学习 (Du 等人, 2022) 和跨图像信息 (Xu 等人, 2023) 在内的策略,以生成准确且完整的 CAM。最近,视觉-语言预训练已成为解决下游视觉-语言任务(包括 WSSS,Lin 等人, 2023)的流行方法 (Zhu 等人, 2023)。由于初始图边界粗糙,诸如 CRF (Kr¨ahenb¨uhl 和 Koltun, 2011) 和 IRN (Ahn, Cho 和 Kwak, 2019) 等优化方法被用来进一步增强。然而,据我们所知,以往没有工作致力于解决由长尾分布的训练数据导致的过度/欠激活问题。本文分析了过度/欠激活背后的原因,并通过共享特征校准 (SFC) 方法来解决这一问题。
Shared Feature in Classification
分类是语义分割的上游任务 (Zhang 等人, 2023b),共享特征在这一任务中已被广泛研究 (Li 和 Monga, 2020)。大多数现有方法 (Zheng 等人, 2017; Yao 等人, 2017; Peng, He 和 Zhao, 2017) 通常只提取用于分类的判别性部分特征,并防止共享特征对分类性能产生影响。尽管分类任务和 WSSS 都是在分类损失下进行训练,但与分类任务不同的是,WSSS 不能仅依赖判别性特征来构建完整的 CAM。现有方法 (Lee, Kim 和 Shim, 2022; Chen 等人, 2022a) 会冻结预训练编码器的若干层,以避免不具判别性的特征发生灾难性遗忘 (Vasconcelos, Birodkar 和 Dumoulin, 2022)。在这项工作中,我们专注于在长尾场景下平衡分类器权重中的共享特征比例,从而提升 WSSS 的性能。
Methodology
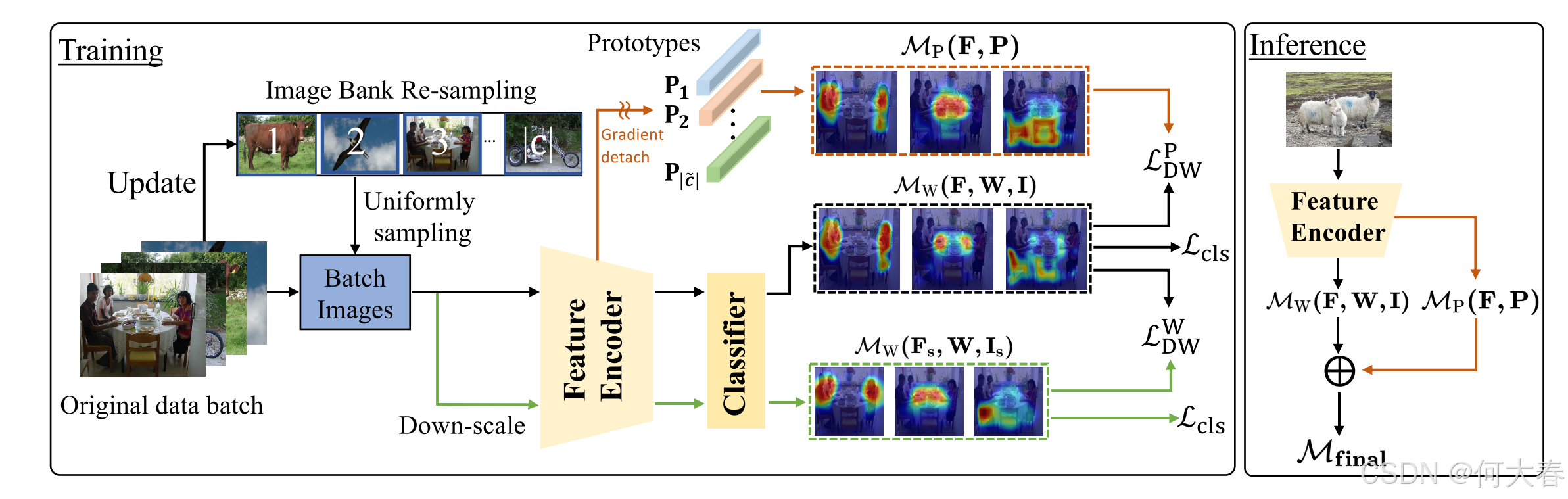
图 2:我们提出的 SFC 的整体结构。对于每张训练图像,计算两个分布加权一致性损失 ( L P D W (L_P^{{DW}} (LPDW 和 L D W W L^W_{DW} LDWW),其中 L P D W L_P^{DW} LPDW 是在原始图像的原型 CAM ( M P (M_P (MP) 和分类器权重 CAM ( M W M_W MW) 之间计算的,而 L W DW L_W^{\text{DW}} LWDW 是在缩小尺度后的图像与原始图像的分类器权重 CAM 之间计算的。此外,维护了一个图像库,用于存储不同类别最近出现的图像,并从中均匀采样图像以补充原始训练批次,从而提高对尾类的一致性损失优化频率。最后,在推理过程中,分类器权重 CAM 与原型 CAM 相互补充。
我们的 SFC 流程如图 2 所示。该流程包括一个图像库重采样(Image Bank Re-sampling,IBR)和一个多尺度分布加权(Multi-Scaled Distribution-Weighted,MSDW)一致性损失。
Preliminary
Classifier Weight CAM
给定输入图像
I
I
I,由编码器从
I
I
I 提取的特征表示为
F
∈
R
H
×
W
×
D
F \in \mathbb{R}^{H \times W \times D}
F∈RH×W×D,类别
c
c
c 的分类器权重表示为
W
c
∈
R
D
×
1
W_c \in \mathbb{R}^{D \times 1}
Wc∈RD×1,其中
H
×
W
H \times W
H×W是特征图的大小,
D
D
D 是特征维度。分类损失是一个多标签软边界损失(multi-label soft margin loss),其计算公式为:
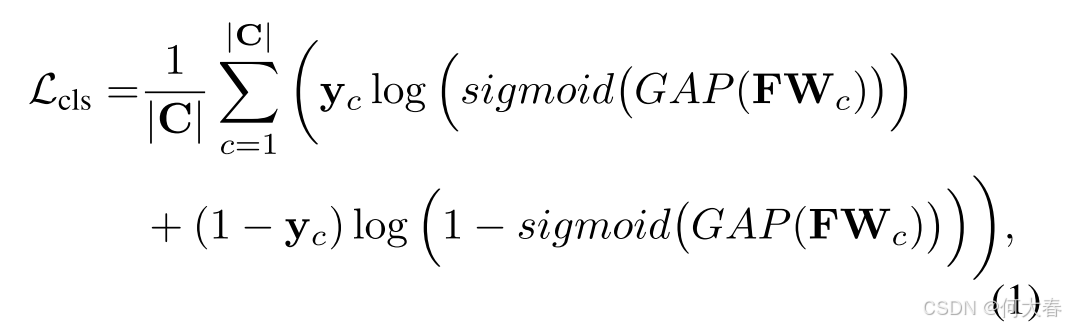
其中, C C C是前景类别集合, ∣ C ∣ |C| ∣C∣表示其大小; y c y_c yc 表示类别 c c c 的二值标签; GAP ( ⋅ ) \text{GAP}(\cdot) GAP(⋅)表示全局平均池化(Global Average Pooling)。随后,通过分类器权重 W W W(即分类器权重生成的 CAM)在输入图像 I I I 提取的特征 F F F 上计算的 CAM 表达式如下:
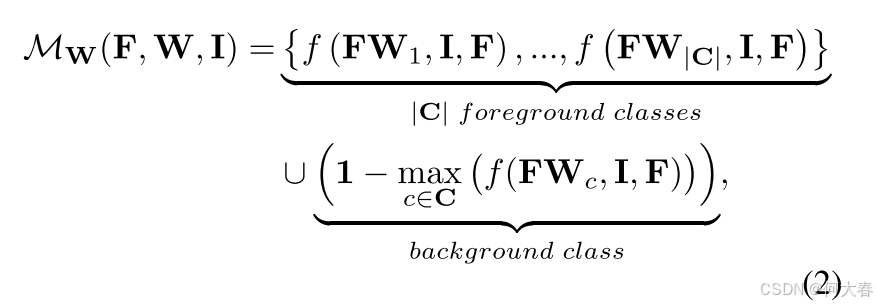
其中, M W M_W MW 表示分类器权重生成的 CAM; f ( ⋅ ) f(\cdot) f(⋅)表示一个函数,该函数将归一化的 ReLU 激活特征 F W FW FW、输入图像 I I I 和特征 F F F输入像素相关模块(Pixel Correlation Module,PCM)(Wang et al. 2020),以根据不同像素之间的低级特征关系优化 CAM。
Prototype CAM
按照(Chen et al. 2022a, 2023)的方法,类原型通过对提取特征的掩码平均池化计算得到。具体来说,从特征提取器不同层提取的分层特征表示为 F 1 , F 2 , F 3 , F 4 F_1, F_2, F_3, F_4 F1,F2,F3,F4; L ( ⋅ ) L(\cdot) L(⋅) 表示线性投影操作,其对特征提取器的梯度传播会停止。然后,类 c ~ \tilde{c} c~( c ~ \tilde{c} c~ 可以是前景类或背景类)的原型 P c ~ P_{\tilde{c}} Pc~ 计算如下:
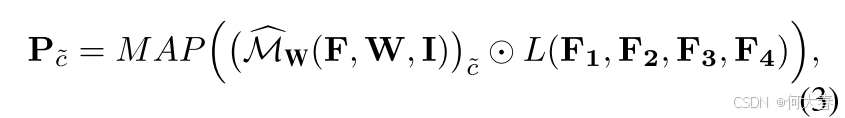
其中, M ^ W ( F , W , I ) \widehat{M}_{W}(F, W, I) M W(F,W,I) 是类 c ~ \tilde{c} c~的二值掩码,用于将激活值高于设定阈值的像素标记为 1; M A P ( ⋅ ) MAP(\cdot) MAP(⋅)表示掩码平均池化操作。最后,通过类 c ~ \tilde{c} c~的原型计算得到的 CAM(即原型 CAM)表示为:
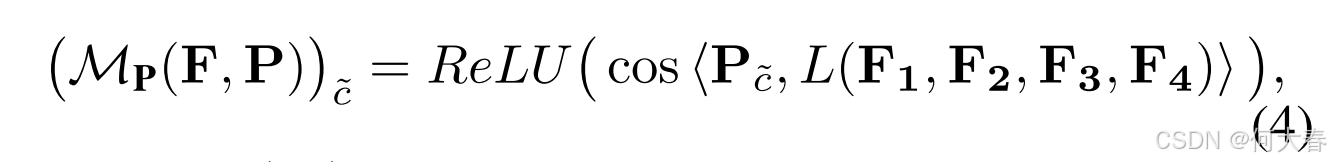
其中,cos ⟨·, ·⟩ 表示两项之间的余弦相似度。
Shared Feature Calibration
Image Bank Re-sampling (IBR) 我们维护了一个图像库 B = ( b 1 , . . . , b c ) B = (b_1, ..., b_c) B=(b1,...,bc),其中存储了 ∣ C ∣ |C| ∣C∣个前景类别对应的 ∣ C ∣ |C| ∣C∣ 张图像。对于当前训练批次中的每张图像 I I I,如果第 c c c类出现在 I I I 中,我们用 I I I 更新 b c b_c bc;否则,保持 b c b_c bc 不变。在更新图像库后,我们从当前库中均匀采样 N I B R N_{IBR} NIBR张图像,并将它们与原始训练批次拼接,作为最终的训练输入。均匀采样不会因为长尾分布而带来额外的共享特征问题,因为不同类别的采样数量几乎是均衡的。
我们提出的 IBR 用于提高尾类的采样频率,从而使 MSDW 损失更频繁地作用于尾类,有效地校准尾类分类器权重中的共享特征。
Multi-Scaled Distribution-Weighted Consistency Loss为了解决头类的过度激活问题和尾类的欠激活问题,我们提出了两种分布加权(DW)一致性损失: L D W P \mathcal{L}^P_{DW} LDWP和 L D W W \mathcal{L}^W_{DW} LDWW。其中, L D W P \mathcal{L}^P_{DW} LDWP是在原型 CAM 和分类器权重 CAM 之间计算的,其公式为:
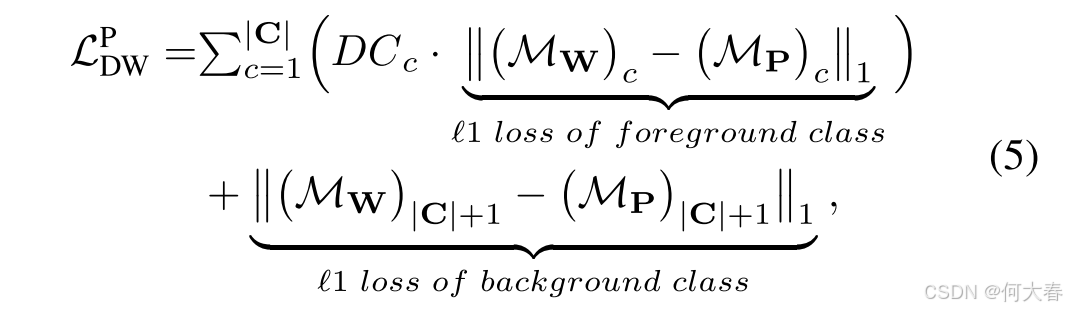
其中, D C c DC_c DCc 表示缩放后的分布系数(Scaled Distribution Coefficient),针对每个前景类别 (c) 计算,公式为:
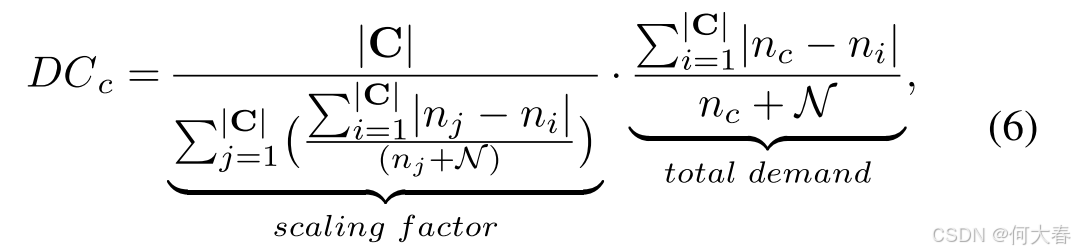
其中, n c n_c nc 表示类别 c c c的样本数量; N \mathcal{N} N表示通过我们提出的 IBR 方法对每个类别估计的增加样本数量,计算公式为:
N = N IBR ⋅ C IBR ⋅ N iter ∣ C ∣ \mathcal{N} = \frac{N_{\text{IBR}} \cdot C_{\text{IBR}} \cdot N_{\text{iter}}}{|C|} N=∣C∣NIBR⋅CIBR⋅Niter
这里, N iter N_{\text{iter}} Niter 表示一个训练周期中的迭代次数; N IBR N_{\text{IBR}} NIBR是从图像库中采样的数量; C IBR C_{\text{IBR}} CIBR 是单张图像中覆盖的类别平均数量。
我们计算类别
c
c
c与其他类别之间样本数量差距的总和,并将此总和视为类别
c
c
c 在一致性损失上的总需求。接下来,将该总需求除以
n
c
+
N
n_c + \mathcal{N}
nc+N(即类别
c
c
c的估计样本总数量)以求得平均值,并结合缩放因子进行缩放,从而得到缩放分布系数(即
D
C
c
DC_c
DCc)。
缩放因子的作用是将前景类别的
ℓ
1
\ell_1
ℓ1 损失幅度调整到与背景类别相同的水平。
D C c DC_c DCc 最终用于对类别 c c c 的一致性损失进行重新加权,为总需求更高的类别分配更高的一致性损失,因为过度/欠激活问题的严重程度与总需求正相关。
同时,当前训练批次中的所有图像通过双线性插值算法以 0.5 的比例进一步下采样,并用于计算损失
L
D
W
W
L^W_{DW}
LDWW:
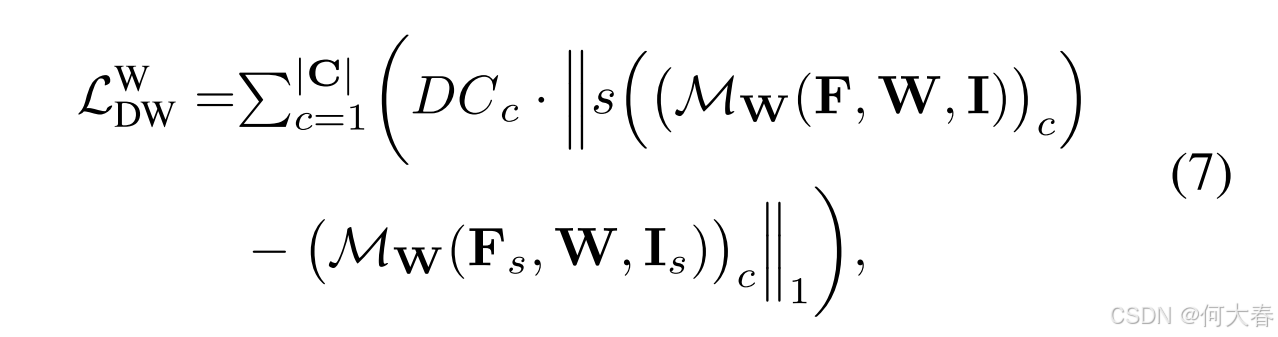
其中, s ( ⋅ ) s(\cdot) s(⋅) 表示双线性下采样操作; I s I_s Is 表示下采样后的图像, F s F_s Fs 表示从其提取的特征。类似于公式 (5),我们通过分布系数 D C DC DC对一致性损失进行重新加权。考虑到下采样图像上的原型 CAM 的准确性低于原始图像上计算的下采样分类器权重 CAM(详见附录中的多尺度方案 L W D W L_W^{DW} LWDW),我们计算的是原始图像上的下采样分类器权重 CAM 与下采样图像上的分类器权重 CAM 之间的一致性损失。 L D W W L^W_{DW} LDWW 进一步提升了性能改进。我们的多尺度分布加权一致性损失 L M S D W L_{MSDW} LMSDW 表达式如下:
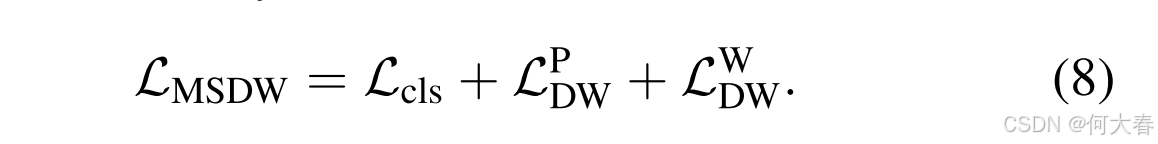
Inference 推理的最终CAM计算如下:
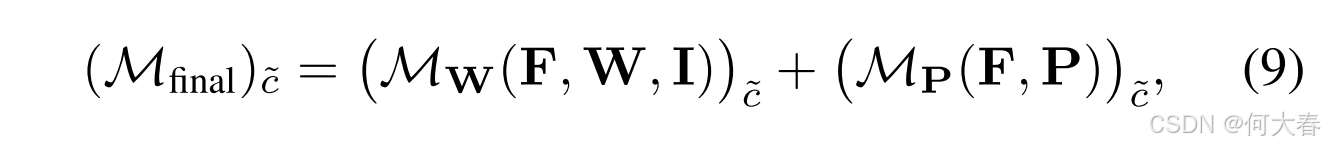
其中, ( M final ) c ~ (\mathcal{M}_{\text{final}})_{\tilde{c}} (Mfinal)c~ 表示类别 c ~ \tilde{c} c~ 的最终 CAM; c ~ \tilde{c} c~ 可以是前景类别或背景类别。通过这种方式,分类器权重 CAM 被原型 CAM 补充,从而共同解决过度/欠激活问题。
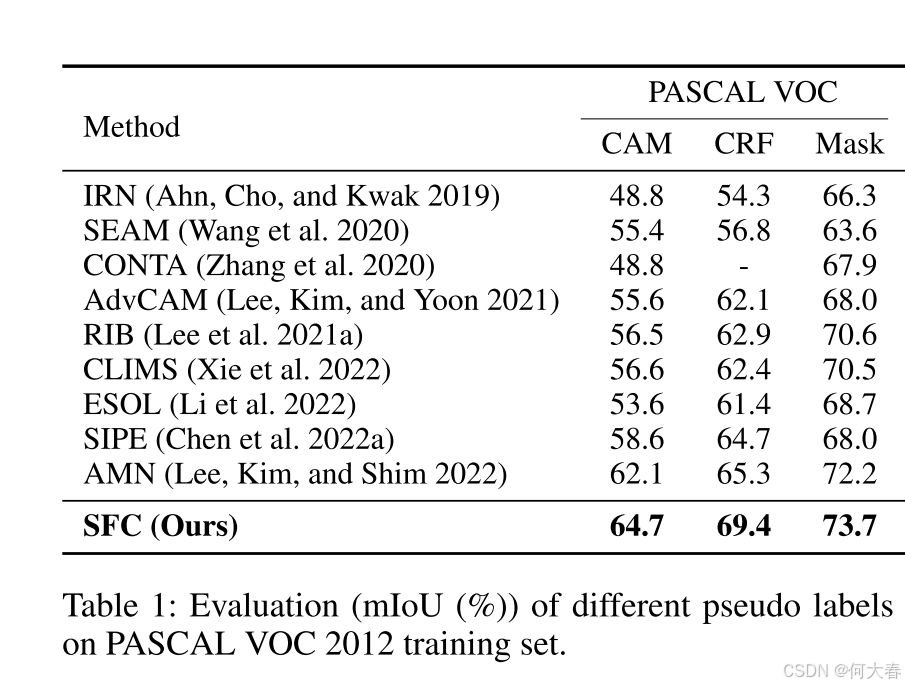
Experiments
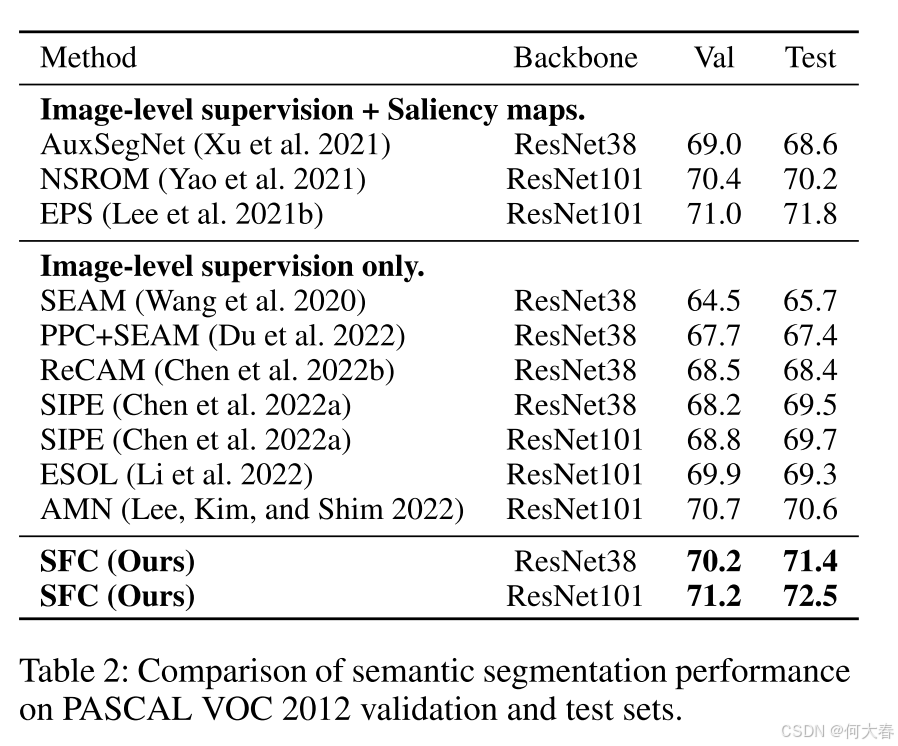
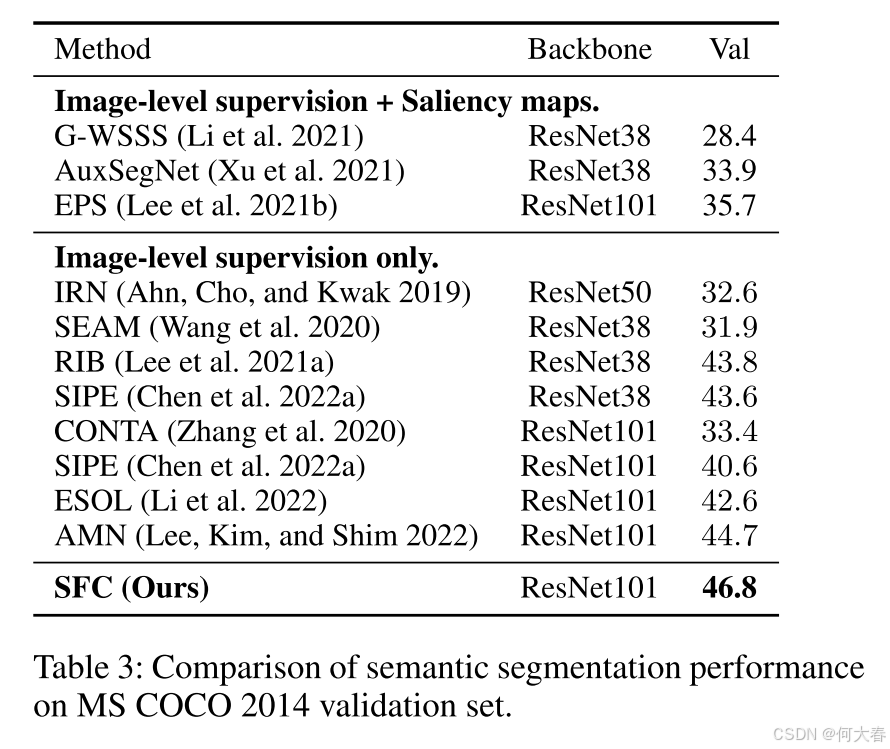
Conclusion
在本文中,我们首先证明了在长尾场景下,共享特征会导致类别激活图(CAM)生成过程中出现过度/不足激活的问题。随后,我们提出了一种新颖的共享特征校准(Shared Feature Calibration,SFC)方法来解决这些问题,并实现了新的最先进性能。我们的工作为提高图像级弱监督语义分割中的 CAM 准确性提供了一个新的视角,未来工作中将探索其他可能的解决方案。
阅读总结
作者怎么证明共享特征会导致类别激活图(CAM)生成过程中出现过度/不足激活的问题有兴趣的可以看看原文,我就不深入研究了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









