







Python 面向对象编程 + 基本数据结构实现【part 2】:堆、二叉树及其遍历
堆
定义
(摘自百度百科)
堆(英语:heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
- 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
一般也用堆实现优先队列,堆一般用于排序,堆排序的时间复杂度为 O ( N log N ) O(N\log N) O(NlogN) 。
堆中元素的序号
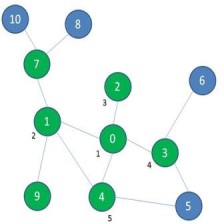
因为堆是一个完全二叉树,因此 i i i 节点的左右子节点的编号一定为 i × 2 , i × 2 + 1 i\times2,i\times 2+1 i×2,i×2+1 。如图(这里区分节点编号,以及节点在一维数组中的键值)

堆的几个函数:
建堆 Build-Heap
主要目的:将一个无序的数组变为一个符合条件的堆(可能是最大堆,也可能是最小堆)思路的证明以及思路的伪代码自己去看CLRS啦
维护堆 Heapify
主要目的:从一个堆节点,确保这个节点底下是一个最大(最小)堆。
堆排序 HeapSort
主要目的:将一个无序的数组变为有序数组
python 实现
这里仍然用类的方法来实现这个算法:因为CLRS上只有最大堆的伪代码,因此我这里也依葫芦画瓢的写了一个最小堆的伪代码,以弥补这个不足。
最大堆,最小堆,以及分别升序、降序的排序都给你们放出来了,够不够意思?
class Heap(object):
# 初始化
def __init__(self):
self.size = None
self.heap = []
# 建立最大堆
def BuildMaxHeap(self, nums):
n = len(nums)
self.size = n
self.heap = nums
for i in range(n//2, -1, -1):
self.MaxHeapify(i)
return self.heap
# 建立最小堆
def BuildMinHeap(self, nums):
n = len(nums)
self.size = n
self.heap = nums
for i in range(n//2, -1, -1):
self.MinHeapify(i)
return self.heap
# 最大堆维护
def MaxHeapify(self, i):
l = i*2 + 1
r = i*2 + 2
largest = i
if l < self.size:
if self.heap[l] > self.heap[i]:
largest = l
if r < self.size:
if self.heap[r] > self.heap[largest]:
largest = r
if largest != i:
self.heap[i], self.heap[largest] = self.heap[largest], self.heap[i]
self.MaxHeapify(largest)
# 最小堆维护
def MinHeapify(self, i):
l = i*2 + 1
r = i*2 + 2
smallest = i
if l < self.size:
if self.heap[l] < self.heap[i]:
smallest = l
if r < self.size:
if self.heap[r] < self.heap[smallest]:
smallest = r
if smallest != i:
self.heap[i], self.heap[smallest] = self.heap[smallest], self.heap[i]
self.MinHeapify(smallest)
# 堆排序
def HeapSort(self, nums, flag = "max"):
if len(nums) <= 1:
return nums
if flag == "max":
self.BuildMaxHeap(nums)
for i in range(self.size - 1, 0, -1):
self.heap[0], self.heap[i] = self.heap[i], self.heap[0]
self.size = self.size - 1
self.MaxHeapify(0)
return self.heap
elif flag == "min":
self.BuildMinHeap(nums)
for i in range(self.size - 1, 0, -1):
self.heap[0], self.heap[i] = self.heap[i], self.heap[0]
self.size = self.size - 1
self.MinHeapify(0)
return self.heap
else:
raise Exception("Non-Legal Type of Heap")这里还加了一句判别了是否是对堆的形式有一个正确的输入,如果不是正常的输入,则抛出异常。
接下来就是测试是否正确:
if __name__ == "__main__":
nums = [4, 1, 3, 2, 16, 9, 10, 14, 8, 7]
heap = Heap()
MaxHeap = heap.HeapSort(nums, flag = "max")
print("MaxHeap", MaxHeap)
MinHeap = heap.HeapSort(nums, flag = "min")
print("MinHeap", MinHeap)得到结果
>>> MaxHeap [1, 2, 3, 4, 7, 8, 9, 10, 14, 16]
>>> MinHeap [16, 14, 10, 9, 8, 7, 4, 3, 2, 1]Remark: 为什么最大堆是升序的,最小堆是降序的?
因为最大堆排序的过程,是不断将最大的放到堆底,而随着堆的大小随之改变,最大值在最后,第二大的在倒数第二位,……,最小的在第一位。
最小堆同理。
Remark: 最大堆还有一个重要的应用,能够在 O ( N log K ) O(N \log K) O(NlogK) 的时间内得到第 K 大的数(维护一个 K K K 大小的最大堆)
二叉树
定义
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。(摘自百度百科)
在 Leetcode 中,确实我还没理解它节点顺序的存储形式,我这里还是通过一个堆来建立二叉树。
二叉树的遍历(更新中)

先序遍历、中序遍历、后序遍历
最常见的遍历方法是:先序遍历、中序遍历、后序遍历 三种,这三种尤其重要。这三种遍历的方法取决于根节点的访问次序:
- 先序遍历:根节点->左子树->右子树
- 中序遍历:左子树->根节点->右子树
- 后序遍历:左子树->右子树->根节点
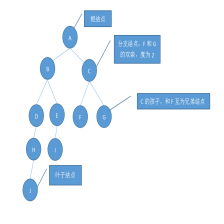
因此对于上面那个二叉树,其三种遍历方式的结果为:
- 先序遍历:FCADBEHGM
- 中序遍历:ACBDFHEMG
- 后序遍历:ABDCHMGEF
简单而言:
- 先序:顺着一路左子树,从根往下走;走不通了,换右子树。
- 中序:找左下角,按左中右,从下往上遍历。
- 后续:找左下角,再找祖先节点的右子树,最后输出祖先节点。
层次遍历
还有一种较为重要的遍历方法,在二叉树可视化中较为重要,称之为:层次遍历。
层次遍历的思路就是图的 BFS 广度优先遍历。在 CLRS 算法导论里有对广度优先的具体伪代码描述。
广度优先有一个非常好的性质:每次输出的都是最小距离。那在树中的距离,其实就是这个节点的深度。只要将相同深度的节点,放在同一层上就可以了
二叉树的代码实现(施工中,仅包含中序、层次遍历)
class TreeNode(object):
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class BinaryTree(object):
def __init__(self):
self.root = TreeNode(None)
def construct(self, lst):
if not lst: return None
stack = []
stack = [TreeNode(i) for i in lst]
n = len(lst)
for i in range(n):
if lst[i] == None:
continue
l, r = 2*i+1, 2*i+2
if r < n:
if lst[r] != None: stack[i].right = stack[r]
if lst[l] != None: stack[i].left = stack[l]
elif r == n:
if lst[l] != None: stack[i].left = stack[l]
else: continue
self.root = stack[0]
def inorderTraversal(self, rt):
if not rt:
return []
Res = self.inorderTraversal(rt.left) + [rt.val] + self.inorderTraversal(rt.right)
return Res
def levelOrder(self):
if not self.root: return []
cur = self.root
gray = [cur]
black = []
dic = dict()
dic[cur] = 0
while gray:
if len(black) <= dic[gray[0]]:
black.append([gray[0].val])
else:
black[dic[gray[0]]].append(gray[0].val)
if gray[0].left:
gray.append(gray[0].left)
dic[gray[0].left] = dic[gray[0]] + 1
if gray[0].right:
gray.append(gray[0].right)
dic[gray[0].right] = dic[gray[0]] + 1
del gray[0]
return black
if __name__ == "__main__":
lst = [3,9,20,None,None,15,7]
Tree = BinaryTree()
Tree.construct(lst)
print("中序遍历:", Tree.inorderTraversal(Tree.root))
print("层次遍历:", Tree.levelOrder())用于测试的树长这样:

执行结果:
>>> 中序遍历: [9, 3, 15, 20, 7]
>>> 层次遍历: [[3], [9, 20], [15, 7]]符合我们的预期。















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









