






https://github.com/huggingface/transformers
🤗 Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨让最先进的 NLP 技术人人易用。
🤗 Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
🤗 Transformers 支持三个最热门的深度学习库: Jax, PyTorch and TensorFlow — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。
实践:
首先pip install 一下:
pip install transformers -U

情绪分析
from transformers import pipeline
# 使用情绪分析流水线
classifier = pipeline('sentiment-analysis') #会自动下载已有的模型
classifier('We are very happy to introduce pipeline to the transformers repository.')
这样就分析出了语句的正负面情绪,并给出了置信度的分数:

从给定文本中抽取问题答案
# 使用问答流水线
question_answerer = pipeline('question-answering') #自动下载模型
question_answerer({
'question': 'What is the name of the repository ?',
'context': 'Pipeline has been included in the huggingface/transformers repository'
})
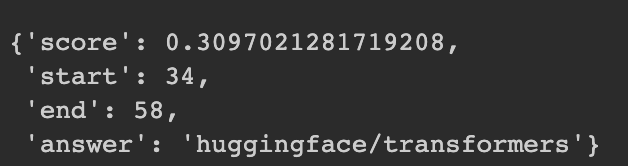
给出了置信度+答案在词符化 (tokenized) 后的文本中开始位置+结束的位置+答案
下载和使用任意预训练模型
pytorch:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello world!", return_tensors="pt")
outputs = model(**inputs)
词符化器 (tokenizer) 为所有的预训练模型提供了预处理,并可以直接对单个字符串进行调用(比如上面的例子)或对列表 (list) 调用。它会输出一个你可以在下游代码里使用或直接通过 ** 解包表达式传给模型的词典 (dict)。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









