







 博主分享了使用英国2019年高速公路事故数据集进行事故等级预测的项目,涉及数据收集与处理、参数排序及模型建立。通过随机森林确定关键参数,并使用SVM建立预测模型,但预测精度有待提高。
博主分享了使用英国2019年高速公路事故数据集进行事故等级预测的项目,涉及数据收集与处理、参数排序及模型建立。通过随机森林确定关键参数,并使用SVM建立预测模型,但预测精度有待提高。
博主最近做了高速公路交通事故等级预测的项目,使用的数据集为英国高速公路2019年事故数据集。本来博主是用它来写论文的,但最近论文方向发生改变,因此将项目分享出来,给大家参考,如果有人做的是事故发生预测,也可以参考一下,具体方法不会差,只是数据标签变一下。由于水平有限,不足之处请见谅。
一、数据收集与处理
博主找过很多数据,最终采用的是英国高速公路2019年事故数据,在很多论文里也看到有人使用美国高速公路数据,这里推荐大家在csdn上搜一搜,能够搜到,也推荐大家一个公众号“交通邦”,一个东南学长创的,数据比较全,不过英国数据集是2018年的,如果有人需要2019年数据可以和博主联系,但是由于博主收集辛苦,可能需要点费用,后面也会将数据压缩包放到csdn里,关注博主后可以找到发布的下载链接,数据内容具体如图:
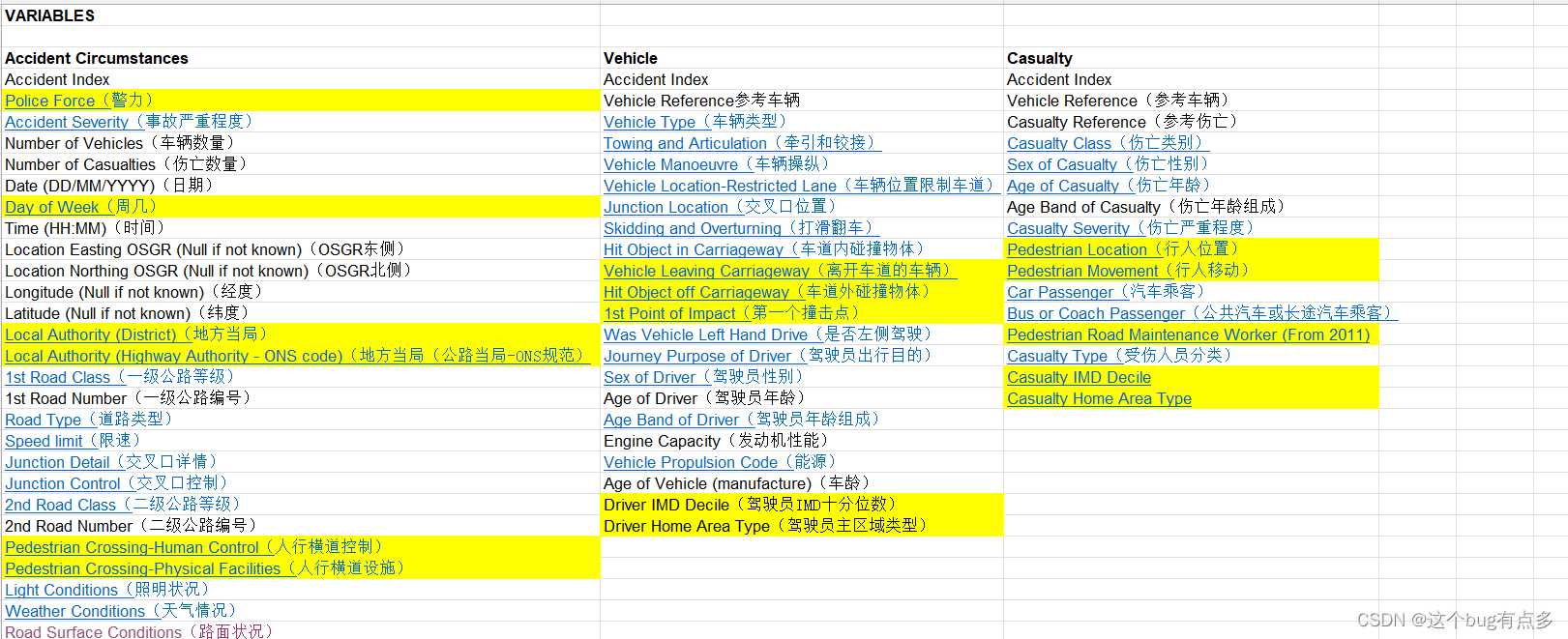
上图可以看出,数据集里面的内容很全,有事故等级、天气、路面条件、灯光等等。对每个数据还会有专门的标注,大家下载之后就能看出。同时,做事故等级预测需要用到交通流数据,我这里也是根据位置在英国的观测点地图上一个个手工定位,花了好几天时间,也会保存到压缩包里发送给有需要的同学,具体也可看图:
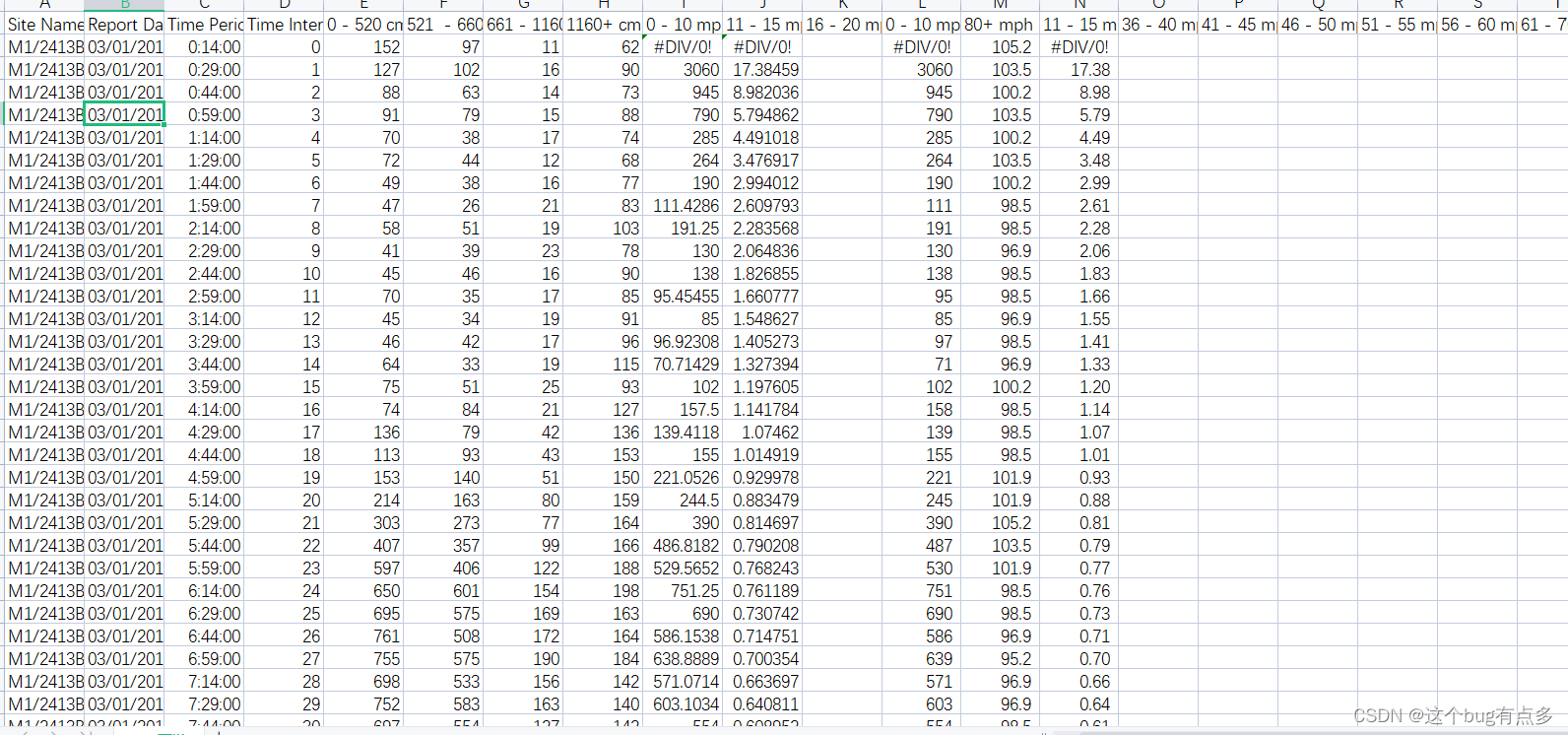
上图是一处事故发生点的上游数据,做这方面论文研究的都知道,事故预测是需要用到事故上下游数据的,工作量很大。这已经完成了初步论文处理,紧接着就是对数据进行繁琐的清楚异常值、筛选变量等等操作,统称为数据清洗。这里的程序虽然简单,但是内容繁杂,就不将代码粘贴上来了。
二、参数排序
我们将数据清洗完成之后,就需要面临一个问题,选择哪些参数来建立预测模型。从之前的数据图中也可以看到,可选数据太多,这不是一个好现象,会造成算法的崩溃。因此,我在这里选择用随机森林对各数据的重要度进行排序,代码如下所示:
import numpy as np
import pandas as pd
testset=pd.read_csv("C:\\Users\\15217\\Desktop\\病例组.csv")
#print(testset.head(5))#可以试运行,查看运行结果
"""进行数据集导入"""
dataset=testset
#将不需要进行排序的路面条件提取出来
dataset.target=testset['Road_Surface_Conditions']
dataset.target.head(287)
#将不需要进行排序的列删除
del_key = ['Location_Easting_OSGR','Location_Northing_OSGR','Longitude','Latitude','Accident_Severity','Number_of_Vehicles',
'Number_of_Casualties','Date','Time','1st_Road_Class','1st_Road_Number','Speed_limit','2nd_Road_Class','2nd_Road_Number',
'Urban_or_Rural_Area','Vehicle_Reference','Casualty_Reference','Casualty_Class','Casualty_Severity','Car_Passenger',
'Bus_or_Coach_Passenger','Casualty_Type','上游线圈平均交通量','上游线圈平均速度','上游线圈平均时间占有率',
'下游线圈平均交通量(辆/30s)','下游线圈平均速度(km/h)','下游线圈平均时间占有率','Location_Northing_OSGR.1']
for key in del_key:
testset.drop(columns=[key],inplace=True)
#剩余需要排序的特征
dataset.feature_names=testset. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











