






作业
题目概要:建立一对多的逻辑回归模型来识别手写数字(0-9)
导入相关库
import numpy as np
# loadmat 读取Matlab文件
from scipy.io import loadmat
from scipy.optimize import minimize
from sklearn.metrics import classification_report
1.导入数据和数据集处理
'''
导入数据集
ex3data1.mat中为我们提供了一个数据集,其中包含5000个手写数字的训练样本。.mat格式表示该数据已保存为MATLAB矩阵格式,而不是文本(ASCII)格式。
使用loadmat函数可以将这些矩阵直接读取到程序中。
'''
path = r'D:\code\Machine\ex3-neural network\ex3data1.mat'
data = loadmat(path) # 导入Matlab文件
# print(data)
print(data['X'].shape, data['y'].shape)
# X-(5000,400) 5000个训练样本,每个样本都是像素20 × 20 20\times2020×20的数字灰度图像
X = data['X']
# y-(5000,1) 训练集对应数字,注意matlab中没有零标签。0用10表示,
y = data['y']
# print(X.shape, y.shape) X-(5000, 400) y-(5000, 1)
# 样本个数(5000)
m = X.shape[0]
X = np.insert(X, 0, values=np.ones(m), axis=1)
# 参数个数(401)
param = X.shape[1]
# 数字标签个数(0-9:10个)
num_labels = 10
2.相关函数构造
'''
sigmoid()
'''
def sigmoid(z):
return 1 / (1 + np.exp(-z))
'''
正则化代价函数
'''
def CostReg(theta, X, y, learnRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
part1 = y.T * np.log(sigmoid(X * theta.T))
part2 = (1 - y.T) * np.log(1 - sigmoid(X * theta.T))
part3 = (learnRate / (2 * m)) * theta * theta.T
return (-part1-part2) / m + part3
'''
正则化的梯度计算
'''
def GradientReg(theta, X, y, learnRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
reg = (learnRate / m) * theta
reg[0, 0] = 0
error = sigmoid(X * theta.T) - y
return X.T * error / m + reg.T
3. 一对多分类(One-vs-all Classification)
'''
One-vs-all
涉及方法介绍:
minimize(fun, x0, args, method, jac) 参数分别代表:要最小化的目标函数、初始参数、需要传递的其他参数、优化算法、是否计算梯度
'''
def one_vs_all(X, y, num_labels, learnRate):
# 一个数字一个分类器
all_theta = np.zeros((num_labels, param))
for i in range(1, num_labels + 1):
# 对每个数字分类器的参数先初始化
theta = np.zeros(params + 1)
# 为原始标签向量y中的每个元素创建了一个One-Hot编码向量y_i
# 为该类则为1,否则为0.
y_i = np.array([1 if label == i else 0 for label in y])
y_i = np.reshape(y_i, (m, 1))
# 求解最优参数
fmin = minimize(fun=CostReg, x0=theta, args=(X, y_i, learnRate), method='TNC', jac=GradientReg)
all_theta[i - 1, :] = fmin.x
return all_theta
4. 一对多预测(One-vs-all Prediction)
'''
One-vs-all Prediction
'''
def Predict_all(X, all_thetas):
X = np.matrix(X)
all_theta = np.matrix(all_theta)
# h为预测每个数字的概率
h = sigmoid(X * all_thetas.T)
# 获取概率最大的数字索引 np.argmax() 返回数组中最大值的索引
h_argmax = np.argmax(h, axis=1)
# 索引加1即为对应数字
num = h_argmax+1
# 缺少这一步骤调用classification_report函数会报错
num = np.asarray(num)
return num
all_theta = one_vs_all(X, y, num_labels, 1)
y_pre = predict_all(X, all_theta)
# classification_report用于生成分类模型的评估报告,评估报告中包括了模型的各项性能指标,例如准确率、召回率、F1值等。
all_theta = one_vs_all(X, y, num_labels, 1)
最终结果:accuracy = 94%
结果
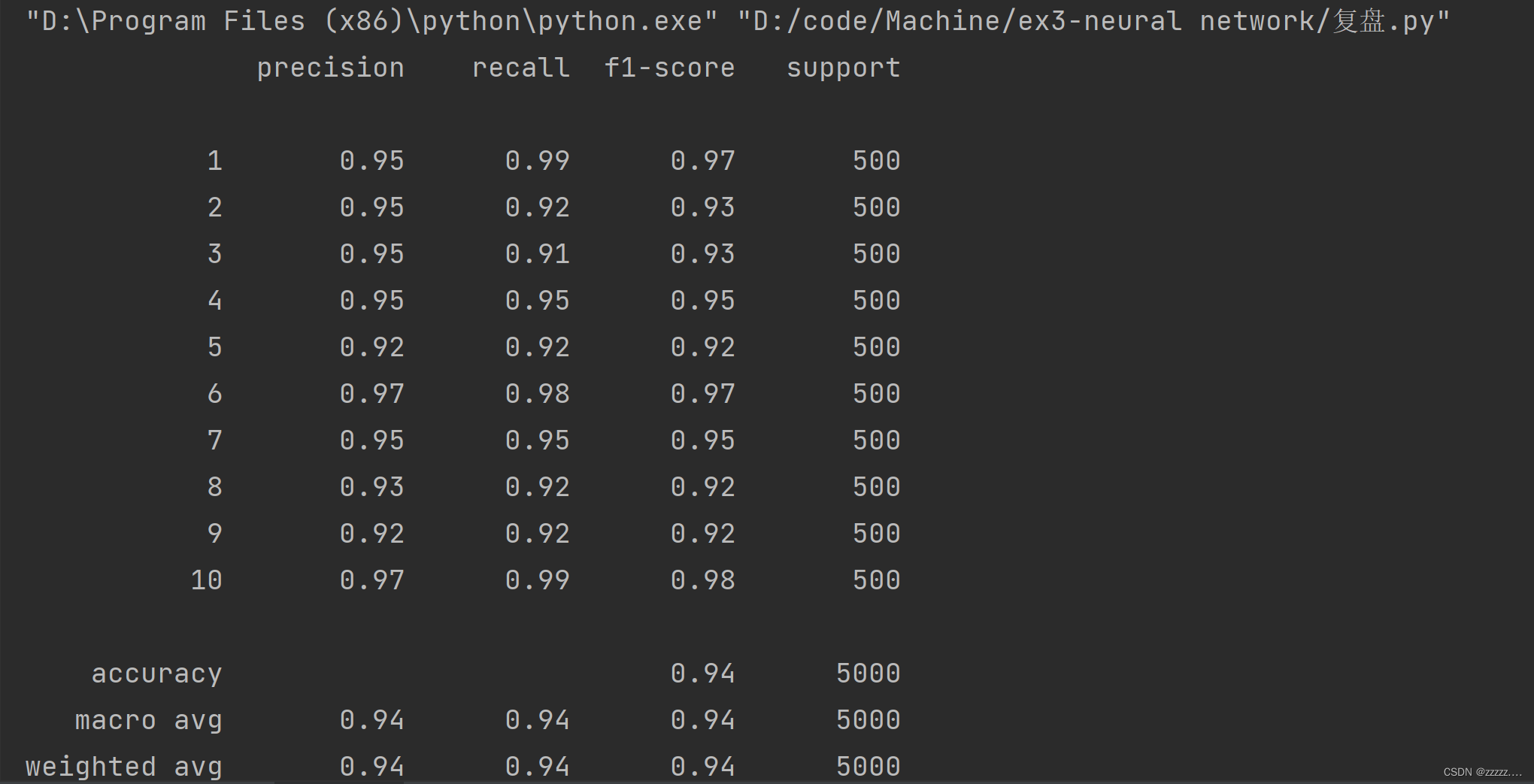
参考
https://blog.csdn.net/weixin_50345615/article/details/126285245















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









