






重点知识回顾
拟合问题
Underfit欠拟合:模型较为简单,与训练数据存在较高误差。
Just right:较为理想的模型,拟合情况刚好。
Overfitting过拟合:模型较为复杂,与训练数据过于贴近。
正则化
目的:解决过拟合问题
基本思想:保留所有的特征,减少参数的大小。通过惩罚模型的复杂度来避免过拟合问题。
正则化后的代价函数(逻辑回归):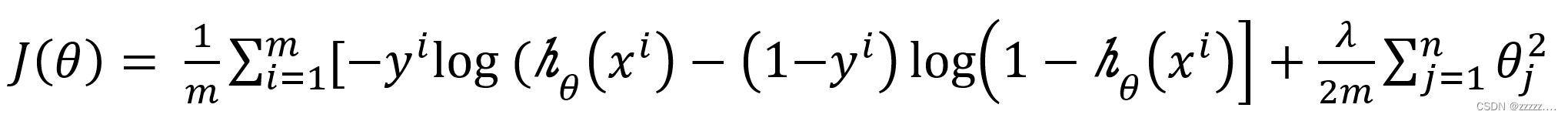
简化后对应的梯度公式:注意正则化不对θ0进行
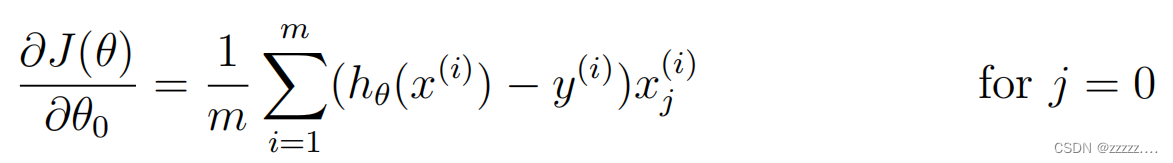
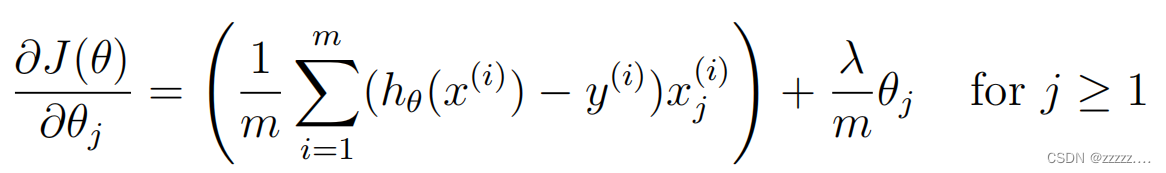
作业
题目概要
根据微芯片的两次质量测试判断接受还是拒绝该微芯片
导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
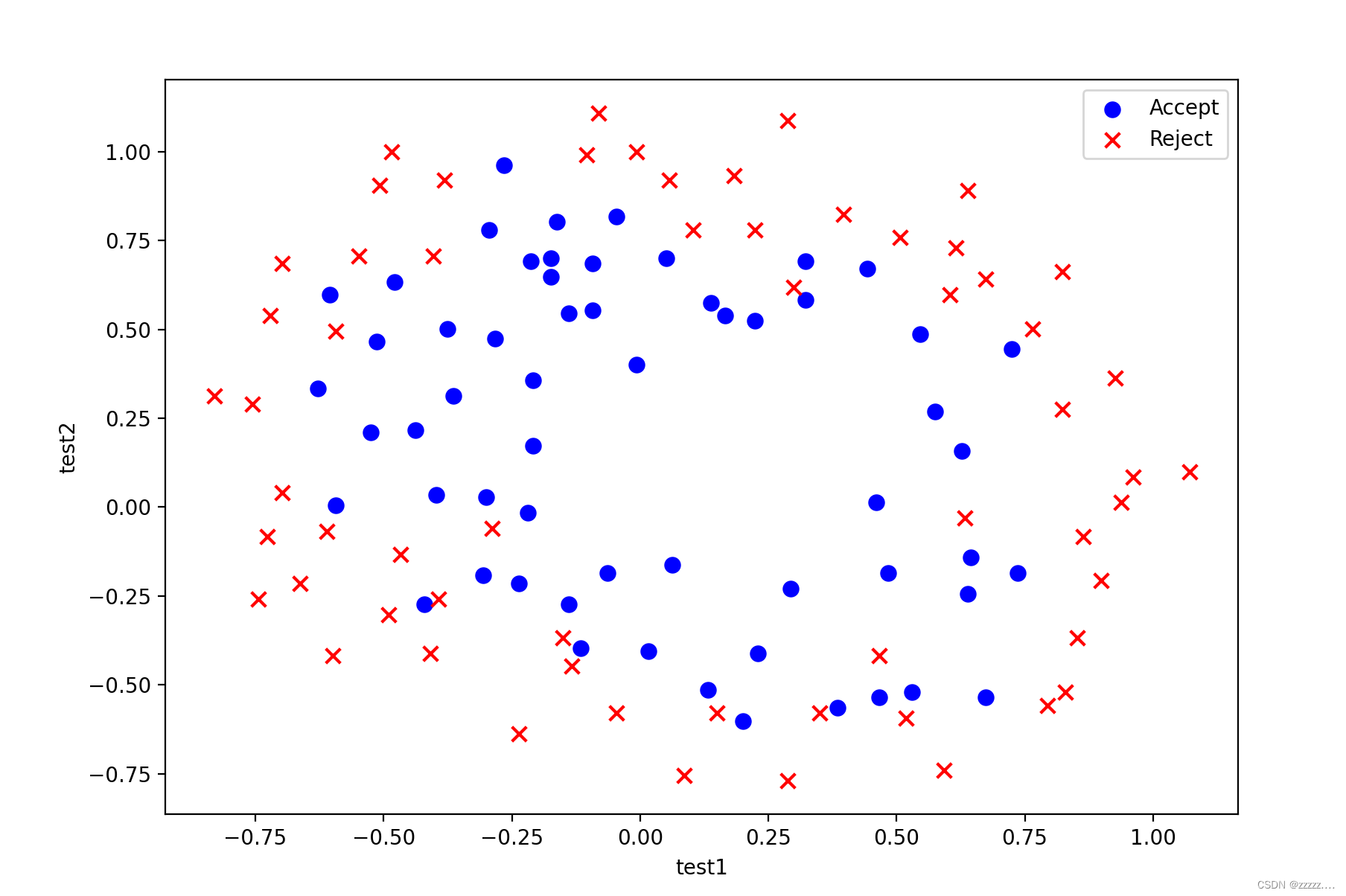
1.数据可视化(Visualizing the data)
'''
1.数据可视化(Visualizing the data)
'''
#导入数据
path = r'D:\code\Machine\ex2-logistic regression\ex2data2.txt'
data = pd.read_csv(path, header=None, names=['test1', 'test2', 'answer'])
#print(data.head())
Accept = data[data['answer'].isin([1])]
Reject = data[data['answer'].isin([0])]
#绘制散点图
fig, ax = plt.subplots(figsize=(12, 8))
ax.scatter(x=Accept['test1'], y=Accept['test2'], s=50, c='b', marker='o', label='Accept')
ax.scatter(x=Reject['test1'], y=Reject['test2'], s=50, c='r', marker='x', label='Reject')
ax.legend()
ax.set_xlabel('test1')
ax.set_ylabel('test2')
plt.show()
散点图呈现如下:
2. 特征映射(Feature mapping)和数据集处理
给每个数据创造更多的特征值以达到良好的拟合效果,这里将x1,x2映射到六次方,如下图:

'''
2.将特征映射到更高次数的多项式,帮助我们捕捉数据中的非线性关系,并使我们的模型能够更好地拟合数据。
'''
def featureMap(x1, x2, degree):
data = {} #以字典的形式创建一个新的空数据
for i in range(degree + 1):
for j in range(i + 1):
data["F{}{}".format(i - j, j)] = np.power(x1, i - j) * np.power(x2, j) #format字符串格式化
return pd.DataFrame(data)
x1 = data['test1']
x2 = data['test2']
degree = 6
data2 = featureMap(x1, x2,degree)
#print(data2)
X = np.matrix(data2)
y = np.matrix(data['answer'])
theta = np.zeros((X.shape[1]))
m = X.shape[0]
完成后的数据前五行如下: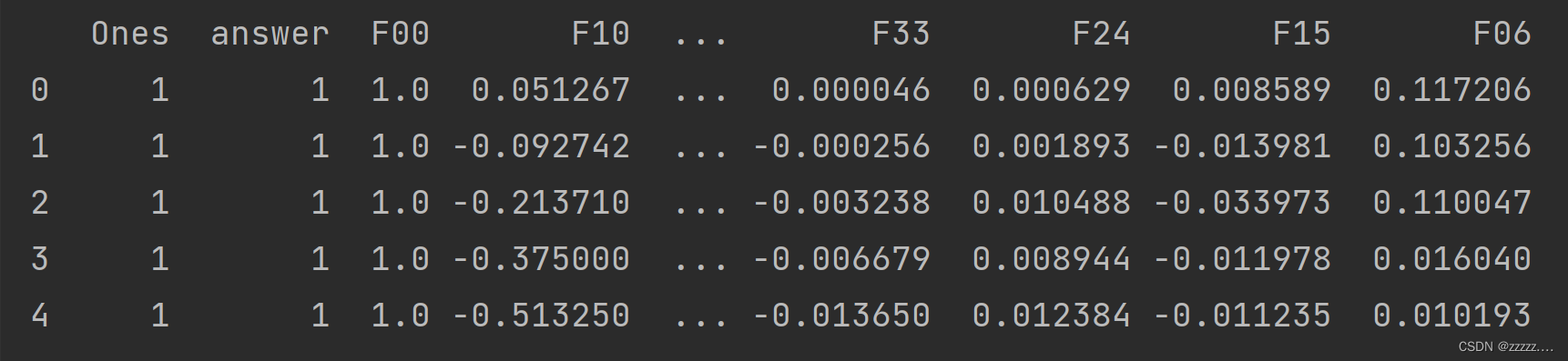
特征值说明: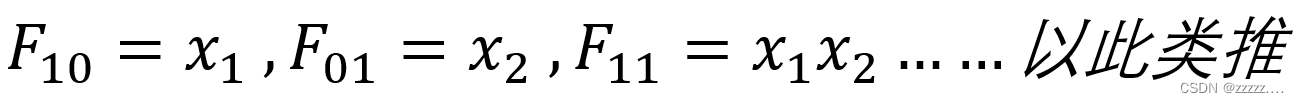
3.相关函数构造
参考上述内容的数学公式构造函数
'''
Sigmoid()
'''
def sigmoid(z):
return 1 / (1 + np.exp(-z))
'''
正则化的代价函数,比之前多一个惩罚项
'''
def CostReg(theta, X, y, learningRate):
theta = np.matrix(theta) # 一定要将参数矩阵化,否则算法为自动识别为narray
first = np.dot(y, np.log(sigmoid(X * theta.T)))
second = np.dot((1 - y), np.log(1 - sigmoid(X * theta.T)))
reg = (learningRate / (2 * m)) * theta * theta.T
return np.sum(-first - second) / m + reg
"正则化的梯度计算"
def GradientReg(theta, X, y, learningRate):
theta = np.matrix(theta)
Reg = (learningRate / m) * theta
Reg[0, 0] = 0 # 不对θ0进行处理
error = sigmoid(X * theta.T) - y.T
return (X.T * error) / m + Reg.T
learningRate = 0.5
# print(CostReg(theta, X, y, learningRate))
初始参数集得到的CostReg为0.69314718
4.调用工作库求解最优参数
'''
4.求解使代价函数最小的参数
'''
result = opt.fmin_tnc(func=CostReg, x0=theta, fprime=GradientReg, args=(X, y, learningRate))
final_theta = result[0]
print(final_theta)
得到最优解的参数结果为:
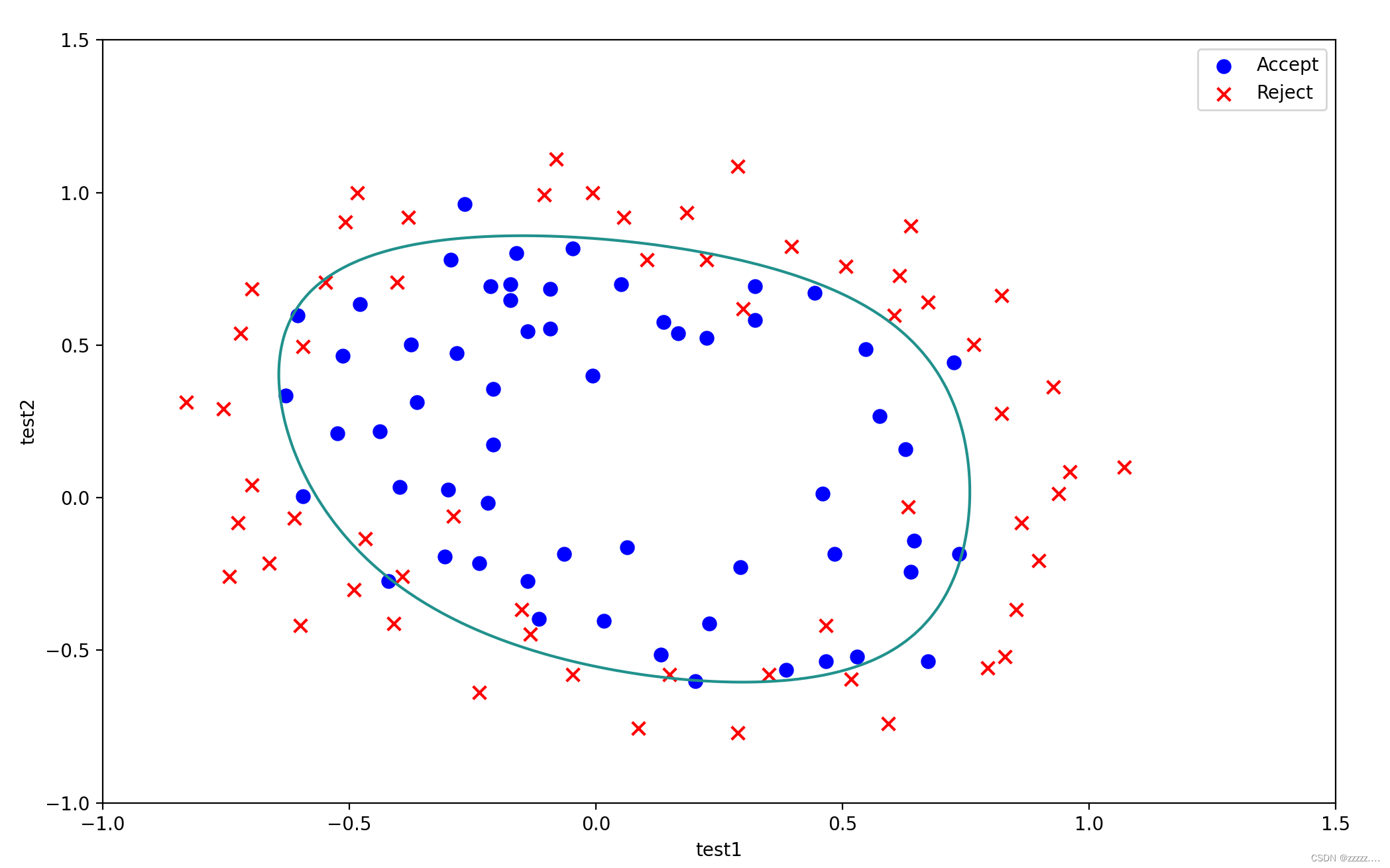
5.绘制决策边界( Plotting the decision boundary)
'''
5.Plotting the decision boundary
散点图与上述数据可视化一致,再使用contour函数绘制决策曲线。
涉及方法介绍:
np.meshgrid() 用于生成网格矩阵
np.ravel(a, order='C') 用于将多维数组转换为一维,a是目标转换的数组,order是可选参数-C代表按行展开;F代表按列展开,默认按行展开。
'''
x = np.linspace(-1, 1.5, 150)
# 使用meshgrid函数生成一个二维网格矩阵xx和yy,其中xx和yy的行和列都等于x的长度,且xx和yy中的元素分别为x中的数值。
xx, yy = np.meshgrid(x, x)
# 使用featureMap函数将xx和yy中的数值映射为高维空间中的特征向量,并将结果转换为一个二维数组z
z = np.array(featureMap(xx.ravel(), yy.ravel(), 6))
# 使用最终权重向量final_theta对特征向量z进行线性变换,得到一个一维数组z。
z = z @ final_theta
# 将一维数组z重新变形为一个二维数组,其形状与xx和yy相同。
z = z.reshape(xx.shape)
Accept = data[data['answer'].isin([1])]
Reject = data[data['answer'].isin([0])]
# 绘制散点图
fig, ax = plt.subplots(figsize=(12, 8))
ax.scatter(x=Accept['test1'], y=Accept['test2'], s=50, c='b', marker='o', label='Accept')
ax.scatter(x=Reject['test1'], y=Reject['test2'], s=50, c='r', marker='x', label='Reject')
ax.legend()
ax.set_xlabel('test1')
ax.set_ylabel('test2')
ax.contour(xx, yy, z, 0)
plt.show()
最终效果图:
参考
https://blog.csdn.net/weixin_50345615/article/details/125984757















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









