







目录
逻辑回归
在这一部分的练习中,你将建立一个逻辑回归模型来预测一个学生是否会被大学录取。假设您是一个大学部门的管理员,您想根据申请人在两次考试中的成绩来确定他们的入学机会。您可以使用以前申请人的历史数据作为逻辑回归的训练集。对于每个培训示例,您都有申请人在两门考试中的成绩和录取决定。
数据可视化
在开始执行任何学习算法之前,如果可能的话,最好将数据可视化。首先我们需要先导入所用到的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt接着导入本次实验中所用到的数据
# 导入数据
path = r'E:\Code\ML\ml_learning\ex2-logistic regression\ex2data1.txt'
data = pd.read_csv(path, header=None, names=['Exam1 Sorce', 'Exam2 Sorce', 'Admitted'])数据如下
| Exam1 Sorce | Exam2 Sorce | Admitted | |
|---|---|---|---|
| 0 | 34.623660 | 78.024693 | 0 |
| 1 | 30.286711 | 43.894998 | 0 |
| 2 | 35.847409 | 72.902198 | 0 |
| 3 | 60.182599 | 86.308552 | 1 |
| 4 | 79.032736 | 75.344376 | 1 |
| ... | ... | ... | ... |
| 95 | 83.489163 | 48.380286 | 1 |
| 96 | 42.261701 | 87.103851 | 1 |
| 97 | 99.315009 | 68.775409 | 1 |
| 98 | 55.340018 | 64.931938 | 1 |
| 99 | 74.775893 | 89.529813 | 1 |
接着我们需要根据Admitted对数据进行分类,将不同的数据使用不同符号进行绘画
positive代表通过考试,negative代表不通过考试
positive = data[data['Admitted'].isin([1])]
negative = data[data['Admitted'].isin([0])]接下来进行数据可视化
fig, ax = plt.subplots(figsize=(12, 8))
# 录取的使用蓝圆表示
# 不录取的使用红叉表示
ax.scatter(x=positive['Exam1 Sorce'], y=positive['Exam2 Sorce'], color='b', marker='o', label='Admitted')
ax.scatter(x=negative['Exam1 Sorce'], y=negative['Exam2 Sorce'], color='r', marker='x', label='Not Admitted')
ax.legend() # 显示图例,默认右上角
# 设置坐标轴标题
ax.set_xlabel('Exam1 Sorce')
ax.set_ylabel('Exam2 Sorce')
plt.show()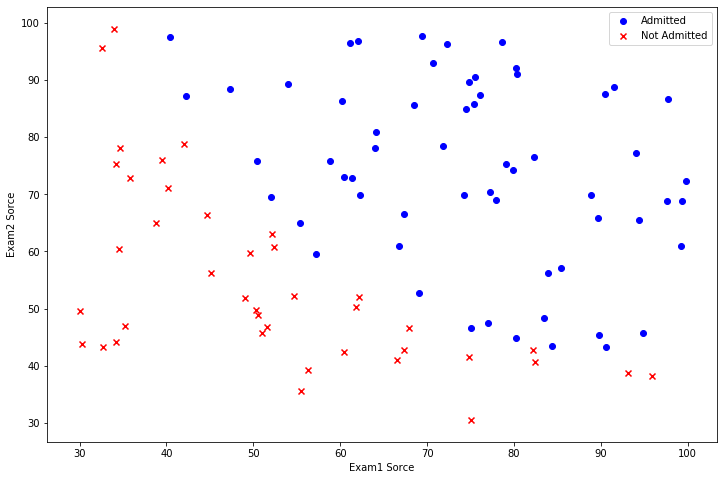
数据处理
# 数据处理部分
# 添加x0 = 1
if 'Ones' not in data.columns:
data.insert(0, 'Ones', 1)
# 输入输出
cols = data.shape[1]
X = np.matrix(data.iloc[:, 0:cols - 1])
y = np.matrix(data.iloc[:, cols - 1:cols])
theta = np.zeros(X.shape[1])实现
Sigmoid函数
逻辑回归函数的定义为:
其中g代表一个常用的逻辑函数为S形函数(Sigmoid function),公式为:
故我们的逻辑回归函数为:
# sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))代价函数与梯度
逻辑回顾的代价函数为:
梯度为:
尽管梯度公式与线性回归的梯度公式相同,但是由于不同,所以公式实际上是不一样的。
# 代价函数
def cost(theta, X, y):
# 转成矩阵运算
# 经过优化算法后的theta是narray类型,不能和martix类型直接相乘,需要重新转成matrix类型
# 或者使用np.dot()进行相乘
theta = np.matrix(theta)
part1 = y.T * np.log(sigmoid(X * theta.T))
part2 = (1 - y).T * np.log(1 - sigmoid(X * theta.T))
# 使用np.dot()时
# 写成这种形式个人认为还就是符合矩阵运算规则
# part1 = np.log(sigmoid(X.dot(theta)))*y
# part2 = np.log(1 - sigmoid(X.dot(theta)))*y
return -(part1 + part2) / len(X)
# 计算梯度
def gradient(theta, X, y):
theta = np.matrix(theta)
return (X.T * (sigmoid(X * theta.T) - y)) / len(X)写好之后调用cost函数可知初始参数的代价为0.6931471805599452
调用工具库计算θ
在线性回归的作业中,我们使用了梯度下降找到了线性回归模型的最优参数,但在本次作业中我们不再自己实现梯度下降,而是调用已有的库,找到最优解,意味着我们不需要自己定义迭代次数与学习率。在Python中我们可以调用scipy.optimize.fmin_tnc或.minimize找到最优解
# 使用高级优化算法
# 两种方法
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
result2 = opt.minimize(fun=cost, x0=theta, jac=gradient, args=(X, y), method='TNC')
print(result)
print(result2)其中所得到的最优参数为[-25.16131858, 0.20623159, 0.20147149],其代价为0.203
画出决策曲线
# 画图
# 决策边界
plotting_x1 = np.linspace(30, 100, 100)
plotting_h1 = (- result[0][0] - result[0][1] * plotting_x1) / result[0][2]
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(plotting_x1, plotting_h1, 'y', label='Prediction')
# 散点图
ax.scatter(x=positive['Exam1 Sorce'], y=positive['Exam2 Sorce'], color='b', marker='o', label='Admitted')
ax.scatter(x=negative['Exam1 Sorce'], y=negative['Exam2 Sorce'], color='r', marker='x', label='Not Admitted')
ax.legend() # 显示图例
ax.set_xlabel('Exam1 Sorce')
ax.set_ylabel('Exam2 Sorce')
plt.show()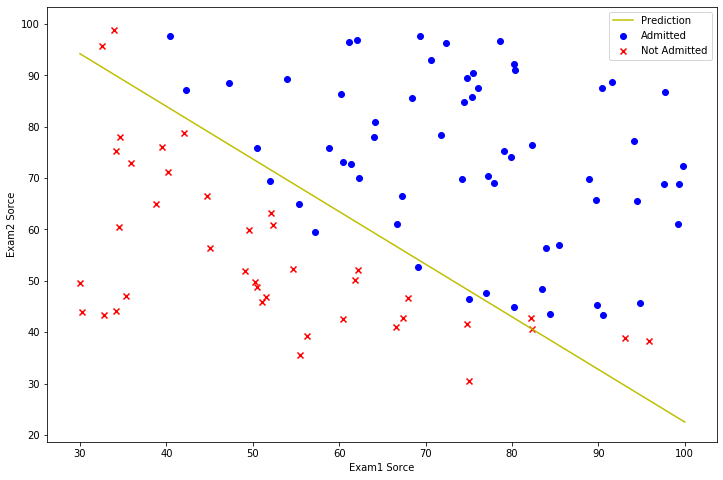
评价逻辑回归模型
在确定参数之后,我们可以使用这个模型来预测某学生是否录取。如果一个学生exam1得分35,exam2得分95,通过该模型得到的录取概率为0.768
def hfunc(theta, X):
return sigmoid(np.dot(X, theta))正则化的逻辑回归
在本部分练习中,您将实现正则化逻辑回归来预测来自制造厂的微芯片是否通过质量保证(QA)。在QA过程中,每个微芯片都要经过各种测试,以确保其正常运行。假设您是工厂的产品经理,在两个不同的测试中有一些微芯片的测试结果。从这两项测试中,您想确定该微芯片是否应该被接受或拒绝。为了帮助您做出决定,您有一个关于过去微芯片测试结果的数据集,从中您可以建立一个逻辑回归模型。
数据可视化
先导入库和数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
# 导入数据
path = r'E:\Code\ML\ml_learning\ex2-logistic regression\ex2data2.txt'
data = pd.read_csv(path, header=None, names=['Test1', 'Test2', 'Accepted'])
数据如下
| Test1 | Test2 | Accepted | |
|---|---|---|---|
| 0 | 0.051267 | 0.699560 | 1 |
| 1 | -0.092742 | 0.684940 | 1 |
| 2 | -0.213710 | 0.692250 | 1 |
| 3 | -0.375000 | 0.502190 | 1 |
| 4 | -0.513250 | 0.465640 | 1 |
| ... | ... | ... | ... |
| 113 | -0.720620 | 0.538740 | 0 |
| 114 | -0.593890 | 0.494880 | 0 |
| 115 | -0.484450 | 0.999270 | 0 |
| 116 | -0.006336 | 0.999270 | 0 |
| 117 | 0.632650 | -0.030612 | 0 |
数据可视化与第一部分练习类似,这里将可视化部分封装在函数中方便复用,其中注释掉的那条代码用于画最后的决策边界。
# 数据可视化
def plotData():
# 根据Admitted分类
positive = data[data['Accepted'].isin([1])]
negative = data[data['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(6, 5))
# 录取的使用蓝圆表示
# 不录取的使用红叉表示
ax.scatter(x=positive['Test1'], y=positive['Test2'], s=70, color='y', marker='o', label='Admitted')
ax.scatter(x=negative['Test1'], y=negative['Test2'], s=50, color='r', marker='x', label='Not Admitted')
ax.legend() # 显示图例
ax.set_xlabel('Test1')
ax.set_ylabel('Test2')
# ax.contour(xx, yy, z, 0)
plt.show()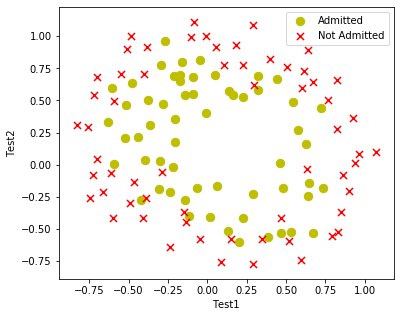
通过上图可知,我们不可以直接使用直线将其区分开,因为逻辑回归只能找到一个线性的决策边界,故不能很好的拟合这里的数据。
特征工程
因此我们可以尝试通过给每个数据点创造更多特征,使其更好的拟合数据,在这里我们可以将特征映射到x1,x2的6次方的多项式项,从而我们的特征向量从两个变成28维向量,更高纬度向量上训练处理的逻辑回归的分类器具有更加复杂的决策边界,因此能产生非线性边界

代码能产生00,01,10,20,11,02等序列
# 特征工程
def featureMapping(x1, x2, degree):
data = {}
for i in np.arange(degree + 1):
for j in np.arange(i + 1):
data["F{}{}".format(i - j, j)] = np.power(x1, i - j) * np.power(x2, j)
pass
return pd.DataFrame(data)| F00 | F10 | F01 | F20 | F11 | F02 | F30 | F21 | F12 | F03 | ... | F23 | F14 | F05 | F60 | F51 | F42 | F33 | F24 | F15 | F06 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.051267 | 0.699560 | 0.002628 | 0.035864 | 0.489384 | 1.347453e-04 | 0.001839 | 0.025089 | 0.342354 | ... | 0.000900 | 1.227829e-02 | 1.675424e-01 | 1.815630e-08 | 2.477505e-07 | 3.380660e-06 | 4.613055e-05 | 6.294709e-04 | 8.589398e-03 | 1.172060e-01 |
| 1 | 1.0 | -0.092742 | 0.684940 | 0.008601 | -0.063523 | 0.469143 | -7.976812e-04 | 0.005891 | -0.043509 | 0.321335 | ... | 0.002764 | -2.041205e-02 | 1.507518e-01 | 6.362953e-07 | -4.699318e-06 | 3.470651e-05 | -2.563226e-04 | 1.893054e-03 | -1.398103e-02 | 1.032560e-01 |
| 2 | 1.0 | -0.213710 | 0.692250 | 0.045672 | -0.147941 | 0.479210 | -9.760555e-03 | 0.031616 | -0.102412 | 0.331733 | ... | 0.015151 | -4.907685e-02 | 1.589699e-01 | 9.526844e-05 | -3.085938e-04 | 9.995978e-04 | -3.237900e-03 | 1.048821e-02 | -3.397345e-02 | 1.100469e-01 |
| 3 | 1.0 | -0.375000 | 0.502190 | 0.140625 | -0.188321 | 0.252195 | -5.273438e-02 | 0.070620 | -0.094573 | 0.126650 | ... | 0.017810 | -2.385083e-02 | 3.194040e-02 | 2.780914e-03 | -3.724126e-03 | 4.987251e-03 | -6.678793e-03 | 8.944062e-03 | -1.197765e-02 | 1.604015e-02 |
| 4 | 1.0 | -0.513250 | 0.465640 | 0.263426 | -0.238990 | 0.216821 | -1.352032e-01 | 0.122661 | -0.111283 | 0.100960 | ... | 0.026596 | -2.412849e-02 | 2.189028e-02 | 1.827990e-02 | -1.658422e-02 | 1.504584e-02 | -1.365016e-02 | 1.238395e-02 | -1.123519e-02 | 1.019299e-02 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 113 | 1.0 | -0.720620 | 0.538740 | 0.519293 | -0.388227 | 0.290241 | -3.742131e-01 | 0.279764 | -0.209153 | 0.156364 | ... | 0.081199 | -6.070482e-02 | 4.538330e-02 | 1.400354e-01 | -1.046913e-01 | 7.826790e-02 | -5.851357e-02 | 4.374511e-02 | -3.270412e-02 | 2.444980e-02 |
| 114 | 1.0 | -0.593890 | 0.494880 | 0.352705 | -0.293904 | 0.244906 | -2.094682e-01 | 0.174547 | -0.145447 | 0.121199 | ... | 0.042748 | -3.562096e-02 | 2.968243e-02 | 4.387691e-02 | -3.656200e-02 | 3.046659e-02 | -2.538737e-02 | 2.115493e-02 | -1.762810e-02 | 1.468924e-02 |
| 115 | 1.0 | -0.484450 | 0.999270 | 0.234692 | -0.484096 | 0.998541 | -1.136964e-01 | 0.234520 | -0.483743 | 0.997812 | ... | 0.234178 | -4.830370e-01 | 9.963553e-01 | 1.292688e-02 | -2.666414e-02 | 5.499985e-02 | -1.134476e-01 | 2.340073e-01 | -4.826843e-01 | 9.956280e-01 |
| 116 | 1.0 | -0.006336 | 0.999270 | 0.000040 | -0.006332 | 0.998541 | -2.544062e-07 | 0.000040 | -0.006327 | 0.997812 | ... | 0.000040 | -6.317918e-03 | 9.963553e-01 | 6.472253e-14 | -1.020695e-11 | 1.609667e-09 | -2.538495e-07 | 4.003286e-05 | -6.313306e-03 | 9.956280e-01 |
| 117 | 1.0 | 0.632650 | -0.030612 | 0.400246 | -0.019367 | 0.000937 | 2.532156e-01 | -0.012252 | 0.000593 | -0.000029 | ... | -0.000011 | 5.555592e-07 | -2.688181e-08 | 6.411816e-02 | -3.102482e-03 | 1.501196e-04 | -7.263830e-06 | 3.514745e-07 | -1.700678e-08 | 8.229060e-10 |
代价函数与梯度
尽管特征映射能构建一个更强大的分类器,但是同时也很容易发生过拟合的问题,因此我们需要使用正则化逻辑回归拟合数据
代价函数的定义为
其中正则化是从θ1开始而不是从θ0
故梯度的定义为
其中learnRate是参数λ,计算梯度的时候并没有采用for循环然后if语句判断,而是直接使用上面第二条公式,但是j = 0时,后面那一项被赋值为0。
# 正则化代价函数
def costReg(theta, X, y, learningRate):
# 转成矩阵运算
# 经过优化算法后的theta是narray类型,不能和martix类型直接相乘,需要重新转成matrix类型
# 或者使用np.dot()进行相乘
theta = np.matrix(theta)
part1 = y * np.log(sigmoid(X * theta.T))
part2 = (1 - y) * np.log(1 - sigmoid(X * theta.T))
part3 = (learningRate / (2 * len(X))) * theta * theta.T
return float(-(part1 + part2) / len(X) + part3)
# 计算梯度
def gradientReg(theta, X, y, learnRate):
theta = np.matrix(theta)
reg = (learnRate / len(X)) * theta
reg[0, 0] = 0
gradient = (X.T * (sigmoid(X * theta.T) - y.T)) / len(X)
return gradient + reg.T调用代价函数可知初始参数的代价为0.693
在这里我们同样使用高级优化算法计算最优参数
# 数据准备
x1 = np.array(data['Test1'])
x2 = np.array(data['Test2'])
data2 = featureMapping(x1, x2, 6)
X = np.matrix(data2)
y = np.matrix(data['Accepted'])
theta = np.zeros(X.shape[1])
learnRate = 0.5
result = opt.fmin_tnc(func=costReg, x0=theta, fprime=gradientReg, args=(X, y, learnRate))
final_theta = result[0]得到的最优参数如下
array([ 1.69807202, 0.97487663, 1.66774106, -2.71241653, -1.48773984,
-2.10885161, 0.2720763 , -0.56458993, -0.51103726, -0.18845331,
-1.97742887, -0.03557666, -0.89624193, -0.46813131, -1.62936247,
-0.29086477, -0.29607859, -0.01239111, -0.43124108, -0.47347733,
-0.47101481, -1.4229088 , 0.07459948, -0.41702859, 0.04547877,
-0.48484035, -0.26513722, -1.12833145])
画图
在这里用利用contour函数将决策边界画出来
x = np.linspace(-1, 1.5, 150)
xx, yy = np.meshgrid(x, x)
z = np.array(featureMapping(xx.ravel(), yy.ravel(), 6))
z = z @ final_theta
z = z.reshape(xx.shape)
plotData()
# 数据可视化
def plotData():
# 根据Admitted分类
positive = data[data['Accepted'].isin([1])]
negative = data[data['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(6, 5))
# 录取的使用蓝圆表示
# 不录取的使用红叉表示
ax.scatter(x=positive['Test1'], y=positive['Test2'], s=70, color='y', marker='o', label='Admitted')
ax.scatter(x=negative['Test1'], y=negative['Test2'], s=50, color='r', marker='x', label='Not Admitted')
ax.legend() # 显示图例
ax.set_xlabel('Test1')
ax.set_ylabel('Test2')
ax.contour(xx, yy, z, 0)
plt.show()结果如下
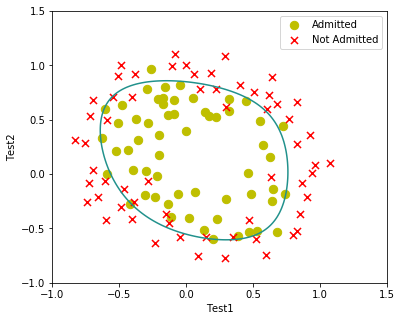
完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
# 导入数据
path = r'E:\Code\ML\ml_learning\ex2-logistic regression\ex2data1.txt'
data = pd.read_csv(path, header=None, names=['Exam1 Sorce', 'Exam2 Sorce', 'Admitted'])
# 数据可视化 需要将不同类型的数据使用不同标记画,故不能使用上次的data.plot()
# 根据Admitted分类
positive = data[data['Admitted'].isin([1])]
negative = data[data['Admitted'].isin([0])]
fig, ax = plt.subplots(figsize=(12, 8))
# 录取的使用蓝圆表示
# 不录取的使用红叉表示
# ax.scatter(x=positive['Exam1 Sorce'], y=positive['Exam2 Sorce'], color='b', marker='o', label='Admitted')
# ax.scatter(x=negative['Exam1 Sorce'], y=negative['Exam2 Sorce'], color='r', marker='x', label='Not Admitted')
# ax.legend() # 显示图例
# ax.set_xlabel('Exam1 Sorce')
# ax.set_ylabel('Exam2 Sorce')
# plt.show()
# 数据处理部分
# 添加x0 = 1
if 'Ones' not in data.columns:
data.insert(0, 'Ones', 1)
# 输入输出
cols = data.shape[1]
X = np.matrix(data.iloc[:, 0:cols - 1])
y = np.matrix(data.iloc[:, cols - 1:cols])
theta = np.zeros(X.shape[1])
# sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 代价函数
def cost(theta, X, y):
# 转成矩阵运算
# 经过优化算法后的theta是narray类型,不能和martix类型直接相乘,需要重新转成matrix类型
# 或者使用np.dot()进行相乘
theta = np.matrix(theta)
part1 = y.T * np.log(sigmoid(X * theta.T))
part2 = (1 - y).T * np.log(1 - sigmoid(X * theta.T))
# 使用np.dot()时
# 写成这种形式个人认为还就是符合矩阵运算规则
# part1 = np.log(sigmoid(X.dot(theta)))*y
# part2 = np.log(1 - sigmoid(X.dot(theta)))*y
return float(-(part1 + part2) / len(X))
# 计算梯度
def gradient(theta, X, y):
theta = np.matrix(theta)
return (X.T * (sigmoid(X * theta.T) - y)) / len(X)
def hfunc(theta, X):
return sigmoid(np.dot(X, theta))
# 使用高级优化算法
# 两种方法
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
result2 = opt.minimize(fun=cost, x0=theta, jac=gradient, args=(X, y), method='TNC')
print(result)
# print(result2)
# 画图
# 决策边界
# plotting_x1 = np.linspace(30, 100, 100)
# plotting_h1 = (- result[0][0] - result[0][1] * plotting_x1) / result[0][2]
# fig, ax = plt.subplots(figsize=(12, 8))
# ax.plot(plotting_x1, plotting_h1, 'y', label='Prediction')
# # 散点图
# ax.scatter(x=positive['Exam1 Sorce'], y=positive['Exam2 Sorce'], color='b', marker='o', label='Admitted')
# ax.scatter(x=negative['Exam1 Sorce'], y=negative['Exam2 Sorce'], color='r', marker='x', label='Not Admitted')
# ax.legend() # 显示图例
# ax.set_xlabel('Exam1 Sorce')
# ax.set_ylabel('Exam2 Sorce')
# plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.optimize as opt
# 导入数据
path = r'E:\Code\ML\ml_learning\ex2-logistic regression\ex2data2.txt'
data = pd.read_csv(path, header=None, names=['Test1', 'Test2', 'Accepted'])
# 数据可视化
def plotData():
# 根据Admitted分类
positive = data[data['Accepted'].isin([1])]
negative = data[data['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(6, 5))
# 录取的使用蓝圆表示
# 不录取的使用红叉表示
ax.scatter(x=positive['Test1'], y=positive['Test2'], s=70, color='y', marker='o', label='Admitted')
ax.scatter(x=negative['Test1'], y=negative['Test2'], s=50, color='r', marker='x', label='Not Admitted')
ax.legend() # 显示图例
ax.set_xlabel('Test1')
ax.set_ylabel('Test2')
ax.contour(xx, yy, z, 0)
plt.show()
# 特征工程
def featureMapping(x1, x2, degree):
data = {}
for i in np.arange(degree + 1):
for j in np.arange(i + 1):
data["F{}{}".format(i - j, j)] = np.power(x1, i - j) * np.power(x2, j)
pass
return pd.DataFrame(data)
# 实现函数
# sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 正则化代价函数
def costReg(theta, X, y, learningRate):
# 转成矩阵运算
# 经过优化算法后的theta是narray类型,不能和martix类型直接相乘,需要重新转成matrix类型
# 或者使用np.dot()进行相乘
theta = np.matrix(theta)
part1 = y * np.log(sigmoid(X * theta.T))
part2 = (1 - y) * np.log(1 - sigmoid(X * theta.T))
part3 = (learningRate / (2 * len(X))) * theta * theta.T
# 使用np.dot()时
# 写成这种形式个人认为还就是符合矩阵运算规则
# part1 = np.log(sigmoid(X.dot(theta)))*y
# part2 = np.log(1 - sigmoid(X.dot(theta)))*y
return float(-(part1 + part2) / len(X) + part3)
# 计算梯度
def gradientReg(theta, X, y, learnRate):
theta = np.matrix(theta)
reg = (learnRate / len(X)) * theta
reg[0, 0] = 0
gradient = (X.T * (sigmoid(X * theta.T) - y.T)) / len(X)
return gradient + reg.T
# 数据准备
x1 = np.array(data['Test1'])
x2 = np.array(data['Test2'])
data2 = featureMapping(x1, x2, 6)
X = np.matrix(data2)
y = np.matrix(data['Accepted'])
theta = np.zeros(X.shape[1])
learnRate = 0.5
result = opt.fmin_tnc(func=costReg, x0=theta, fprime=gradientReg, args=(X, y, learnRate))
final_theta = result[0]
x = np.linspace(-1, 1.5, 150)
xx, yy = np.meshgrid(x, x)
z = np.array(featureMapping(xx.ravel(), yy.ravel(), 6))
z = z @ final_theta
z = z.reshape(xx.shape)
plotData()















 4666
4666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











