







预训练的大型语言模型通常被称为基础模型,它们在各种任务上表现良好,我们可以将它们用作目标任务微调的基础。大型语言模型 (LLM) 在客户服务、营销、法律、金融、医疗保健、教育等领域有着广泛的应用,而微调使我们能够使模型适应目标领域和目标任务,这就是 LLM 的微调之处。
低阶自适应参数高效微调 (LoRA) 简介
一些微调的最佳实践包括使用强正则化、使用较小的学习率和少量的epochs。对于LLM,我们使用一种类似的方法,称为参数高效微调(PEFT)。其中一种流行的PEFT方法是低秩适应(LoRA),LoRA 是低秩适应 (Low-Rank Adaptation) 的缩写,其是一种用于微调深度学习模型的新技术,它在模型中添加了少量可训练参数模型,而原始模型参数保持冻结。LoRA 是用于训练定制 LLM 的最广泛使用、参数高效的微调技术之一。
LoRA 可以将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍。尽管可训练参数更少、训练吞吐量更高且无需额外推理,LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量表现与微调相当或更好延迟。
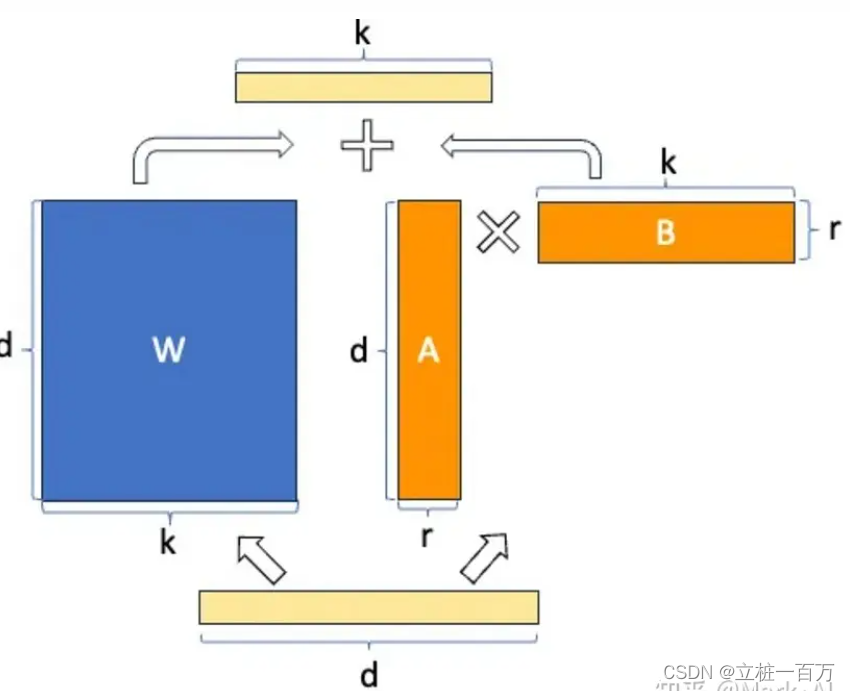
LoRA 将权重矩阵分解为两个较小的权重矩阵,如下所示,以更参数有效的方式近似完全监督微调。
LoRA是怎么去微调适配下游任务的
流程很简单,LoRA利用对应下游任务的数据,只通过训练新加部分参数来适配下游任务。而当训练好新的参数后,利用重参的方式,将新参数和老的模型参数合并,这样既能在新任务上到达fine-tune整个模型的效果,又不会在推断的时候增加推断的耗时。
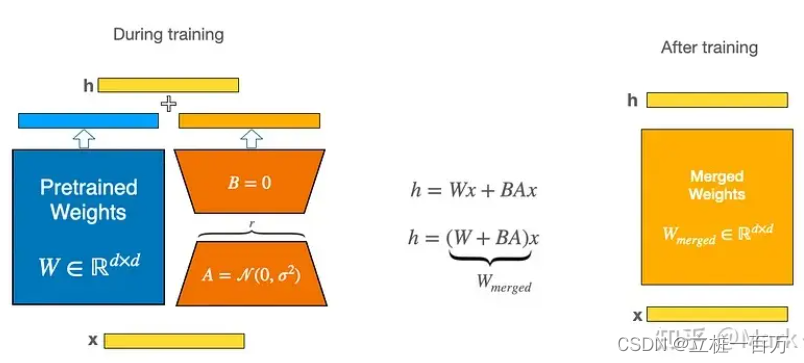
具体思路是,与微调预训练的大型语言模型的权重矩阵(W)中的所有权重相比,微调两个较小的矩阵(A和B),这两个矩阵近似于对原始矩阵的更新。![]()
这些矩阵构成LoRA适配器。这里的“r”是一个超参数(该论文建议使用1、2、4、8或64,其中4或8在大多数情况下效果最好)。在训练期间,W0被冻结,不接收梯度更新,而A和B包含可训练参数。W0和ΔW = BA与相同的输入进行乘法运算,它们的输出向量在坐标上进行求和。A使用随机高斯初始化,B使用零初始化,因此在训练开始时ΔW = BA为零。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。\
LoRA 原理对应伪代码
LoRA 的实现相对简单。我们可以将其视为 LLM 中全连接层的修改前向传递。在伪代码中,如下所示:
input_dim = 768 # e.g., the hidden size of the pr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









