






文章为自己总结面试常见问题的学习记录,其中包含多个学习链接,部分文字总结于链接文章中,如原作者有异议可联系修改。
Redis
redis有哪几种数据结构?link1 link2

zset底层数据结构是什么?为什么使用跳表?跟B+树怎么比?查找的时间复杂度是多少?什么是跳表₁
Redis可以做消息队列吗?有什么缺点?link1 link2
-
基于List的 LPUSH+BRPOP 的实现
-
PUB/SUB,订阅/发布模式
-
基于Sorted-Set的实现
-
基于Stream类型的实现
redis使用场景
排行榜及相关问题,分布式锁,秒杀活动,缓存,消息队列。
Redis 本身有持久化,为什么还要写进 MySQL? link
权限控制,数据完整(备份),负载均衡,数据隔离,数据库可以使用事务,需求不同(统计)
redis持久化
RDB方式:是在“N秒内至少有M个改动”才进行持久化操作,需要将所有内存数据写入文件,然后替换原有文件,如果数据量很大,频繁的生成快照会很耗性能。但是如果策略间隔很大,会导致redis宕机的时候会丢失数据。优点就是因为二进制文件,所以恢复起来比较快。
AOF方式:是每执行一次修改命令 或者 每秒,会把执行的命令追加到aof文件中,有点类似mysql利用binlog日志做增量备份。
redis缓存穿透,雪崩,击穿 详细原因 解决方案详解
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据库。比如第一,自身业务代码或者数据出现问题(例如:set 和 get 的key不一致),第二,一些恶意攻击、爬虫等造成大量空命中(爬取线上商城商品数据,超大循环递增商品的ID)。
解决方案:1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;2.布隆过滤器:将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对DB的查询。
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:1.使用互斥锁:当缓存失效时,不立即去load db,先使用如Redis的setnx去设置一个互斥锁,当操作成功返回时再进行load db的操作并回设缓存,否则重试get缓存的方法。【若时间过长会死锁,吞吐量降低。一致性好,后端负载低。】2.永远不过期:物理不过期,但逻辑过期(后台异步线程去刷新)【数据不一致】。
缓存雪崩:当缓存服务器宕机、重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,大量请求直接到达存储层,存储层压力过大导致系统雪崩。
解决方案:1.宕机重启类型可缓存设计成高可用,可利用sentinel或cluster实现。2.集中失效的处理方法可将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值。
布隆过滤器 实战配置参考
/**
* 优化手动初始化bloom过滤器
*/
@Override
public void initBloom() {
bloomFilter.delete();
RedissonConf.creatBloomFilter(bloomFilter);
initBloomFilter();
}
秒杀活动方案 link1 link2
RPUSH key value 插入秒杀请求.
LPOP key 读取秒杀成功者的用户id,进行后续处理。
或者使用LRANGE key start end命令读取秒杀成功者的用户id,进行后续处理。每完成一条秒杀记录的处理,就执行INCR key_num。
(不重要)GEO是干嘛的?举个场景 link
地理定位计算距离,比如外卖配送范围。
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指- 定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
(不重要)HyperLogLog是干嘛的? link1 link2
计数的,如统计一个网页的UV浏览量,若用set集合存储user信息去重再统计很占用空间,可以使用HyperLogLog 。
HyperLogLog 的优点是,即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定的、并且是很小的。每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog 不能像集合那样,返回输入的各个元素
语法:PFADD(添加),PFCOUNT(统计) ,PFMERGE(合并)
redis> PFADD str1 "apple" "banana" "cherry"
(integer) 1
redis> PFCOUNT str1
(integer) 3
redis> PFADD str2 "apple" "cherry" "durian" "mongo"
(integer) 1
redis> PFCOUNT str2
(integer) 4
redis> PFMERGE strSum str1 str2
OK
redis> PFCOUNT strSum
(integer) 5
乐观锁悲观锁 1.原理详解 2.总结转自「JavaGuide」
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
分布式锁 1.redis实现 2.总结转载自「二次元boy」
使用场景
比如转账,订单库存等业务中,可能出现同一时间多个请求操作同一任务的情况。典型案例库存超卖。
用处
分布式锁保证了在分布式部署的应用集群中,同一个方法在同一操作只能被一台机器上的一个线程执行。常见加锁方式是redis,数据库,zookeeper。
redis分布式锁的两种方式
-
使用setNX方式。通过.setIfAbsent插入key和唯一值,插入成功返回true则加锁成功执行业务,插入失败fasle则退出流程。
注意几点:
1.在finally中释放的锁要保证是当前线程的,比如在华为的发票系统中,把订单号和国家代码作为key保证单笔订单不重复处理,同时生成唯一值作为value,在finally中检验key对应的value是否本线程一直。
2.防止宕机导致锁不能释放,通常会添加过期时间比如setIfAbsent(key, value, 30, TimeUnit.SECONDS);
3.同时为了防止 业务执行时间>锁失效时间,会添加类似“看门狗的线程”比如ScheduledThreadPool定时为锁延时。 -
Redisson框架。加锁续锁释放锁都用的LUA脚本保证原子性,同时自带“看门狗”机制,默认锁持有30秒,默认续锁是在1/3时间的时候续锁,同时也不需要自己生成唯一的value。
RLock redissonLock = redissonClient.getLock(“key name”);
redissonLock.tryLock(0, 30, TimeUnit.SECONDS);等待0秒持有30秒
redissonLock.unlock();
数据库分布式锁实现
缺点:、1.db操作性能较差,并且有锁表的风险
2.非阻塞操作失败后,需要轮询,占用cpu资源;
3.长时间不commit或者长时间轮询,可能会占用较多连接资源
Redis(缓存)分布式锁实现
缺点:1.锁删除失败 过期时间不好控制
2.非阻塞,操作失败后,需要轮询,占用cpu资源;
ZK分布式锁实现
缺点:性能不如redis实现,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower。
总之:ZooKeeper有较好的性能和可靠性。
从理解的难易程度角度(从低到高)数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库
Mysql
sql中分页数据limit100000,10优化link
慢的原因:磁盘需要多次IO翻过前面数据,再取当页的那几条。磁盘拿整个数据页到存储引擎缓冲区,如果每次磁盘IO只能取到几条,所以要翻掉前100条,需要多次IO,就会慢。
方式一:改造limit 100,10这个sql,用where id > 100 limit 10。不缓存前面100页,从直接过滤掉钱100,取10条。
方式二:先分页取主键,再回表查询所有主键对应数据。主键相对于整行数据占用内存小。
DATE_FORMAT,TO_DAY函数导致时间索引失效处理
WHERE DATE_FORMAT(time,‘%Y-%m-%d’) > ‘2022-01-01’;会导致time索引
改为WHERE time > ‘2020-01-01’;
范围导致索引失效
非主键的情况下,二级索引的范围如果过大,比如超过10%-30%这样且不止查询主键和索引的情况,优化器可能判断推荐全表扫描
联合索引问题
(a,b,c)组合索引,查询语句select…from…where a=… and c=…走索引吗?
最佳左前缀法,如果索引了多列,要遵守最左前缀法则,否则索引失效
按最左前缀原则,a能走索引,c走不了,只能用到a部分索引
原因:MySQL创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序
int(1)和int(10)的区别
即使int(1)也可以插入4294967295最大值说明int后面的数字,不影响int本身支持的大小。
例如:20210917。这里的(8)不是想限制长度,而且"声明"字段意义和长度。通常配合zerofill能看出效果,进行不够则前方补0。
MySQL的MVCC及实现原理
1.@Transactional 2.Spring事务注解@Transactional
主从同步
原因:网络延迟,max allowed packet过小sql执行失败等
解决方案:1.跳过错误继续同步。2.如果差异过大或者必须数据强一致的话就重做主从。
Mysql分区
就是把一张表数据分块存储,将表物理截断,但在逻辑上依然是一个整体,提升索引的查询效率。
过滤条件为分区的字段时才会自动寻找分区,否则还是全表扫描。
JVM
JVM1.了解2.调优3.结构模型
jdk:开发工具包。
jre:把java代码编译成字节码文件.class。
jvm:java虚拟机,把字节码文件编译成计算机认识的(二进制01010…)文件。
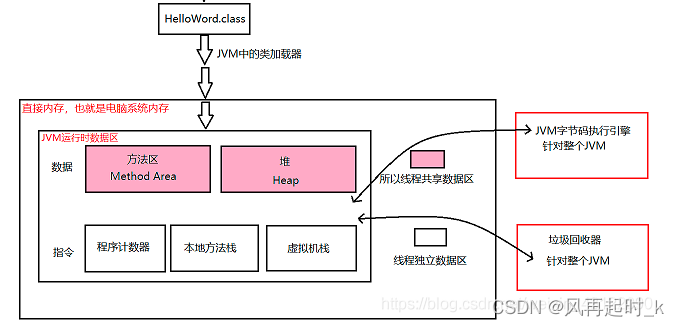
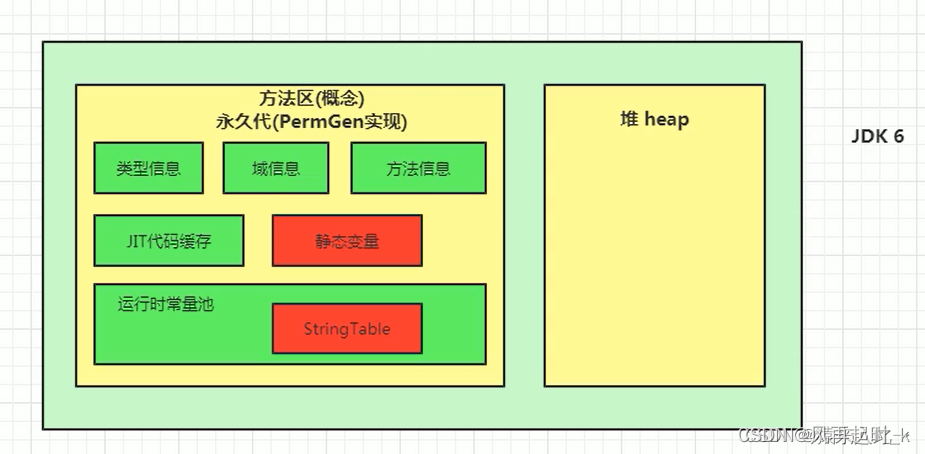
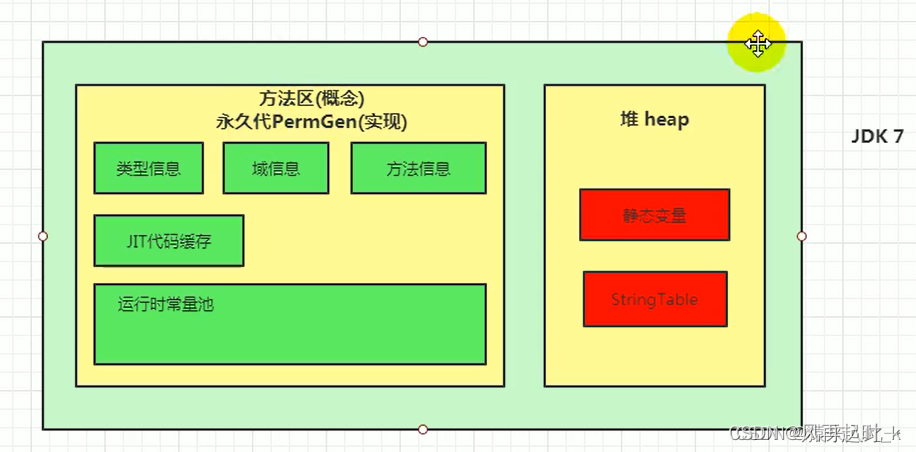
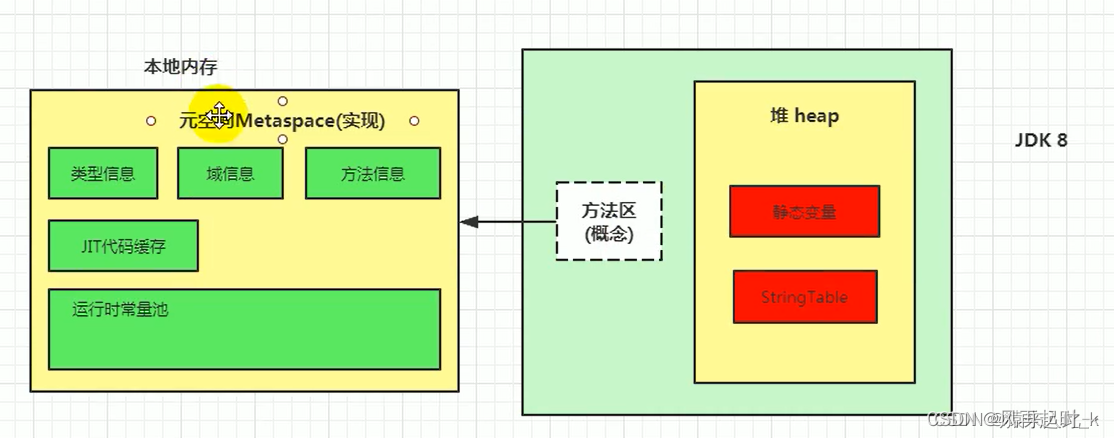
名词解释
jdk改动对方法区和常量池的变动
堆:是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象。
方法区存:jdk1.6存储运行时常量池、静态变量(static)以及方法信息(修饰符、方法名、返回值、参数等)、类信息(类变量)等。
在1.7之后将字符串常量池和静态变量放入堆内存中。
在1.8的时候改为元数据区,这块区域移动到本地内存中。
虚拟机栈:每个方法会分配一块栈帧内存空间。栈帧中包含:局部变量表、操作数栈、动态链接和方法出口。
——局部变量表:存储基本数据类型(int、float、byte等),如果是引用数据类型,则存储的是其在堆中的内存地址,也就是指向对象的一个指针。
——操作数栈:操作数运算时一块临时的空间来存放操作数。
——动态链接:将代码的符号引用转换为在方法区(运行时常量池)中的直接引用。
——方法出口:存储了栈帧中的方法执完之后回到上一层方法的位置。
(操作数栈、动态链接、方法返回地址解释)
各冲常量池和方法区详解
本地方法栈:存储本地接口库里调用的方法,同虚拟机栈,只不过就是java里面native关键字修饰的方法。
程序计数器:每个线程启动是都会创建一个程序计数器,保存的是正在执行的jvm指令,程序计数器总是指向下一条将被执行指令的地址。生命周期与线程的生命周期保持一致。
java中的基本数据类型和引用类型在JVM中存储在哪?
并不是都在虚拟机栈的局部变量表中,方法中申明的局部变量在栈帧的局部变量表,类中申明的基本数据类型为成员变量不会随着方法结束消失,他是在堆中的。
具体:
1.在方法中声明的变量可以是基本类型的变量,也可以是引用类型的变量。
当声明是基本类型的变量的时,其变量名及值(变量名及值是两个概念)是放在JAVA虚拟机栈中
当声明的是引用变量时,所声明的变量(该变量实际上是在方法中存储的是内存地址值)是放在JAVA虚拟机的栈中,该变量所指向的对象是放在堆内存中的。
2.同样在类中声明的变量即可是基本类型的变量,也可是引用类型的变量
当声明的是基本类型的变量其变量名及其值放在堆内存中的
引用类型时,其声明的变量仍然会存储一个内存地址值,该内存地址值指向所引用的对象。引用变量名和对应的对象仍然存储在相应的堆中
tip2:new String(“abc“)创建几个对象问题
-
GC主要用于Java堆的管理。
-
System.gc();手动gc建议回收。
-
每次gc前都会调用finalize()方法。
-
堆被划分成两个不同的区域:
新生代:大批对象死去,用 复制算法 回收。
┗Eden区,Survivor区。E区满了进行Minor GC(快),存活的对象年龄+1并放到S区,默认年龄到15后移到老年代。
老年代:对象存活率高,用 标记法 回收。进行Major GC(慢,通常跟full GC等价),会伴随着新生代的Minor GC。gc还处理方法区(永久代),更不易回收。Full GC是两个区域都清理。
-
JVM参数
-Xms:初始堆大小,JVM 启动的时候,给定堆空间大小。
-Xmx:最大堆大小,JVM 运行过程中,初始堆空间不足时,最大可扩展到多少。
还可以设置新生代老年代比例,栈大小等。 -
JVM调优,比如OutOfMemoryError
-
直接内存与堆内存的区别:
直接内存申请空间耗费很高的性能,堆内存申请空间耗费比较低
直接内存的IO读写的性能要优于堆内存,在多次读写操作的情况相差非常明显
堆内存ByteBuffer.allocate()
系统直接内存ByteBuffer.allocateDirect() -
内存泄漏的一种情况:
A指向B,B指向A,造成内存泄漏 -
Java heap space
原因:比如查询结果集过大导致创建比较大的对象,或者像file这些资源没有被回收。
解决:大部分情况修改-Xmx参数可以解决。解决不了的话优化查询方案,排查内存泄漏。
Nacos 雨田说码
Nacos
nacos概念:作为册中心,用来完成服务的注册与发现,做一些配置管理。
nacos怎么使用:至少要在配置文件里配上nacos的服务名称和地址,把各个服务注册到nacos上,然后通过feign进行相互调用。还可以把配置文件放到nacos上管理。
nacos通信:nacos他有一套opneapi,比如服务注册,心跳检查,集群节点同步等,nacos底层会依靠这些api进行通信和功能实现。服务注册的话本质就是发送一个web请求。
Ribbon
Ribbon nacos本身自带ribbon做负载均衡,默认使用轮训策略,此时页面权重是无效的。使用权重策略需要引入loadbalancer依赖在配置文件中开启。
OpenFeign
Feign怎么使用:调用接口的话首先引入openfeign依赖,在启动项加@EnableFeignClients注解,写FeignClient接口,在类注解上写明需要调用的服务名称,方法上使用@PostMapping(“/需要调用方法”)表名请求类型和具体方法名,再写详细的RequestMapping,使用的时候Autowired注入进去调用方法。
Gateway
用来做网关处理,作为外部系统调用内部接口的统一入口,起到服务路由和鉴权等过滤拦截功能。
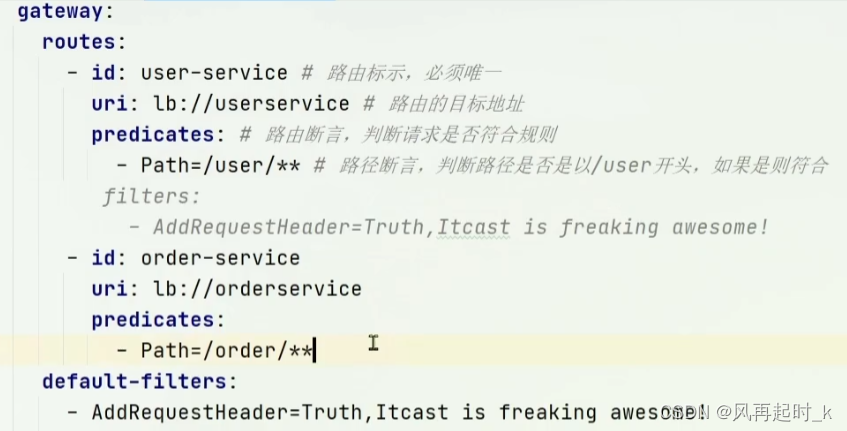
注册到Nacos,添加Gateway配置,通过路由断言走到目标地址,断言还可以配置校验时间,参数,域名,请求头内容等,以及做路由过滤。也可以实现全局的过滤器GlobalFilter接口自定义鉴权逻辑。
路由过滤顺序可以通过比如注解@orader传入int值越小优先级越高 。值相同的话按照default过滤器>局部过滤器>全局的GlobalFilter。
浏览器禁止前端发起与服务端跨域的ajax请求,跨域问题可以在服务端(gateway)配置cors策略允许那些地址哪类请求比如post,get等,以及检测有效时间。
Sentinel (限流,隔离,熔断降级等手段保护微服务)
可以针对接口,也可以使用@SentinelResource(“name”)配置方法资源限流。针对接口时也可以细化到参数级别的限制。
为什么要用Sentinel
微服务雪崩:一个服务故障,引起调用链相关联的服务故障,比如长时间等待,tomcat连接资源耗尽。
可以通过流量控制来避免,或者用其他三种方式来防止故障传播。

怎样整合Sentinel

页面通过设置流控规则,监控QPS或者线程并发数设置阈值进行限流。
流控模式:直连/关联/链路
流控效果:快速失败/WarmUp/排队等待
关联:A配置流控关联B接口,B达到阈值限流A
链路:比如AB都使用M方法,对M方法进行链路,只有A在超过阈值时限流
效果方面:快速失败和WarmUp都在达到最大阈值后直接失败,只不过WarmUp是一个预热状态,逐步达到最大值;排队等待是设置超时时间,在并发数波动的情况下可以有效保证出口速度,不会直接将请求失败。
隔离降级相关
实现FallbackFactory接口并注册为Bean,提供PlanB或者进行记录日志,有好提示等。在FeignClient接口中指定配置。
熔断
慢调用:比如10秒内10个请求,有一半请求执行时间超过500毫秒,就熔断2秒。
异常比例/异常数:监控发生异常比例进行熔断。

授权
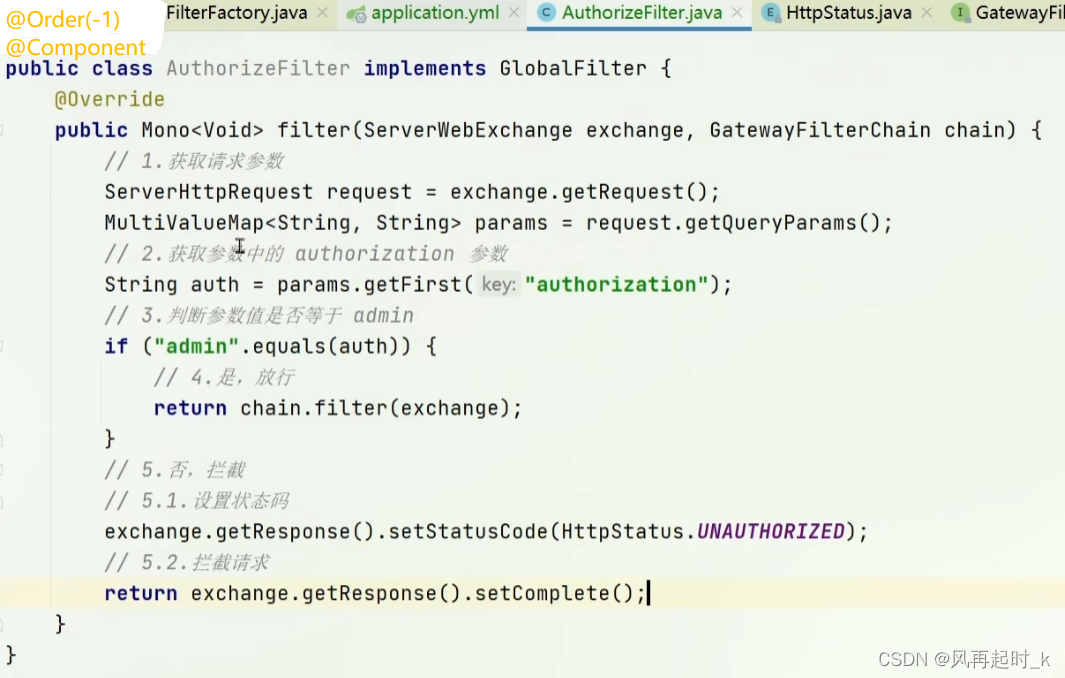
假如绕过gateway直接请求到内部服务接口,则gateway的过滤策略没用,可以在Sentinel中配置白名单黑名单再测进行授权
持久化
可以用pull模式保存在本地文件,定时读取,可能数据不一致。
或者push模式配合nacos进行保存,可以监听变更实时更新。
RabbitMQ## 1.生产消费流程 2.在springboot中的使用
MQ主要作用:
异步处理、服务解耦、流量控制(削峰)
MQ消息丢失 :
1.队列本身出问题:如宕机重启等,对队列、消息、交换机做持久化,保存到磁盘。
队列和交换机持久化durable=true;消息持久化MessageProperties.PERSISTENT_TEXT_PLAIN。
2.持久化写入磁盘时出问题:做集群镜像。
3.消费时出问题:设置ACK回调机制(acknowledgement)处理失败设置标识退回给消费者。
MQ消息重复消费
原因:消费者接收处理消息后没有手动提交给MQ或者手动自动提交后网络故障MQ没收到,消息就会回到队列再次消费。
解决:可以在消费端作处理保持幂等性,添加主键或者set到Redis。或者给消息添加唯一ID保存日志。
MQ的五种工作模式和四种交换机1.图解 2.SpringBoot中的代码示例
1、简单队列: 一个生产者对应一个消费者
2、work 模式: 一个生产者对应多个消费者,但是一条消息只能有一个消费者获得消息
3、发布/订阅模式: 一个消费者将消息首先发送到交换器,交换器绑定到多个队列,然后被监听该队列的消费者所接收并消费。
4、路由模式: 生产者将消息发送到direct交换器,在绑定队列和交换器的时候有一个路由key,生产者发送的消息会指定一个路由key,那么消息只会发送到相应key相同的队列,接着监听该队列的消费者消费消息。
5、主题模式: 上面的路由模式是根据路由key进行完整的匹配(完全相等才发送消息),这里的通配符模式通俗的来讲就是模糊匹配。符号“#”表示匹配一个或多个词,符号“*”表示匹配一个词。
四种交换器
1、direct (路由模式绑定key) 如果路由键完全匹配的话,消息才会被投放到相应的队列。
2、fanout (发布订阅) 当发送一条消息到fanout交换器上时,它会把消息投放到所有附加在此交换器上的队列。
3、topic (主题模式) 设置模糊的绑定方式,“*”操作符将“.”视为分隔符,匹配单个字符;“#”操作符没有分块的概念,它将任意“.”均视为关键字的匹配部分,能够匹配多个字符。
4、header headers 交换器 允许匹配 AMQP 消息的 header 而非路由键,除此之外,header 交换器和 direct 交换器完全一致,但是性能却差很多,因此基本上不会用到该交换器
类加载机制和双亲委派 详解
类加载过程:包括了加载、验证、准备、解析、初始化五个阶段。
加载:主要是把class文件加载到虚拟机,在Java堆中创建一个个Class对象。
验证:主要是验证文件格式、元数据、字节码和符号引用,确保字节流符合要求。
准备:为类变量分配内存并设置类变量初始值。但是通常默认都是0,null,false这些。同时被final和static修饰的会立即赋值。
解析:对类或者接口通过不断向父类或父接口进行递归解析。
初始化:比如对静态变量赋值,因为准备阶段都是赋予初始值,这里是进行代码赋值。
四种类加载器:启动类加载器,扩展类加载器,应用类加载器,自定义类加载器。
双亲委派:类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器在它的搜索范围中没有找到所需的类时,即无法完成该加载,子加载器才会尝试自己去加载该类。
Spring相关
Spring面试题
AOP相关
面向切面编程,可以通过指定切面,包括指定监听哪个文件或者哪个文件夹下的方法,通过前置、后置、环绕通知这些来进行类似拦截的功能。用来写日志,做事务处理或者一些校验认证。我在项目里主要是配合自定义注解,在类似开退票的接口上用环绕通知获取请求头信息,参数,这些,做部分校验后放行,然后记录执行日志。
1.类上面用@Aspect标注切面类
2.方法上使用@Pointcut标注切人点,可以是具体的方法路径,也可以配合自定义注解使用
3.@Before@Around通知类型
自定义注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Log {
String detail() default "";
}
IOC相关 Bean加载流程 生命周期1 生命周期2 bean加载代码步骤3
认识:把对象控制权交给spring,由spring来控制对象的生命周期和依赖关系,它帮我们创建、查找及注入依赖对象。主要通过工厂模式加反射机制实现。
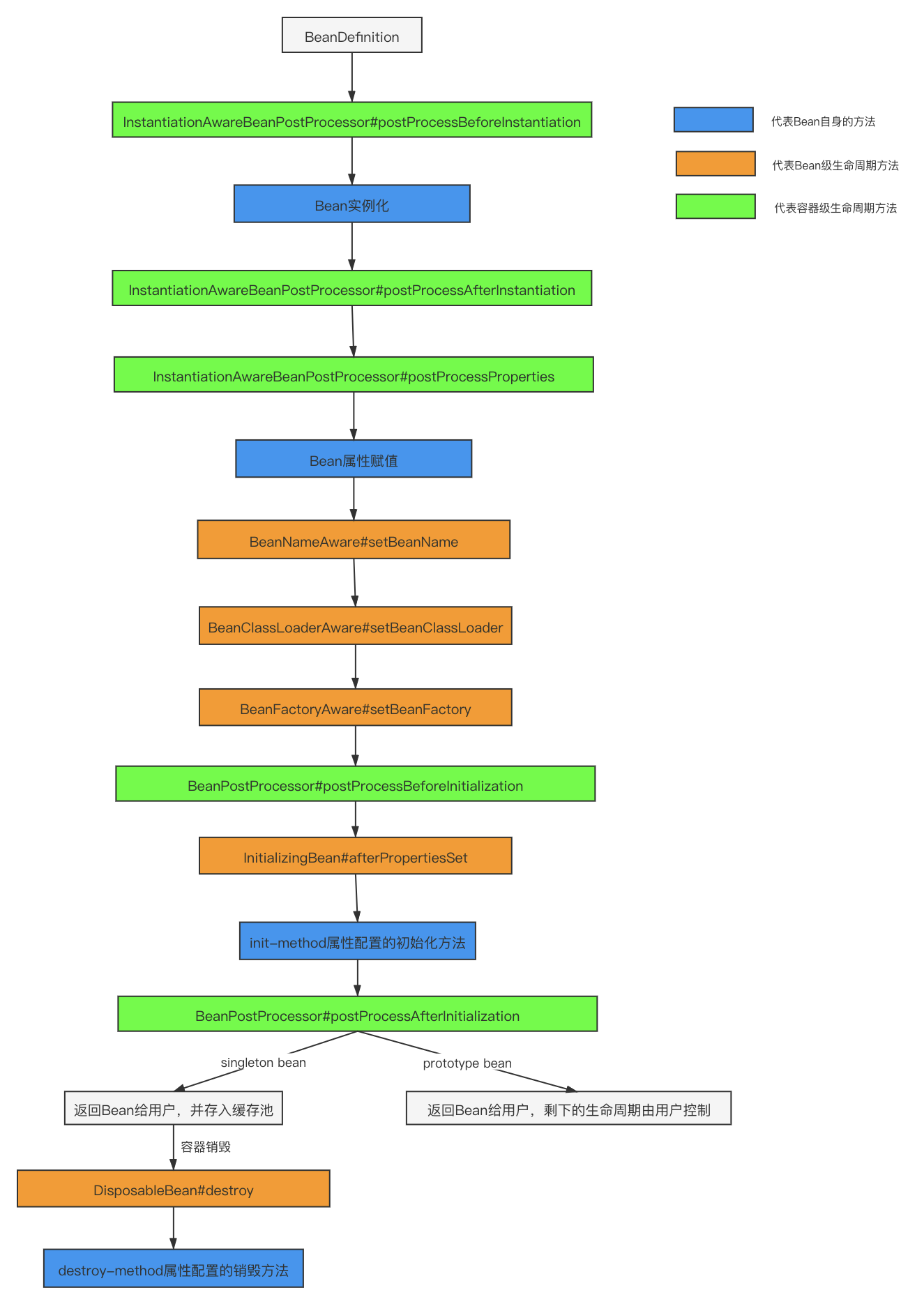
Bean生命周期:实例化,属性赋值,初始化,销毁。
实例化:容器启动后spring先是把各种配置元信息加载到内存,转化为BeanDefination的形式。所有的 BeanDefination会以键值对的形式注册到BeanDefinationRegistry。(非抽象,非单例,非懒加载的bean会在容器启动后立即进行)
属性赋值:通过BeanWrapper提供的设置属性的接口完成属性设置与依赖注入
初始化:通过Aware接口,前置后置处理一些接口完成初始化。
销毁:通过DisposableBean销毁。
Spring的循环依赖 介绍和解决
WHAT: 比如两个类,ClassA中有属性B,ClassB中有属性A,所以在创建A类到时候需要经过A的生命周期,属性b做赋值,但这时候B没有实例化,所以又会经过B的生命周期,当B走到为A赋值的这一步,A的生命周期还没完成,这样就导致A需要B,B需要A,也就是循环依赖。
HOW: 基于Java的引用传递,当获得对象的引用时,对象的属性是可以延后设置的。所以spring做了三级缓存。
A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
一级缓存为:singletonObjects;
二级缓存为:earlySingletonObjects;
三级缓存为:singletonFactories;
数据结构相关
List接口实现类:区别参考1 区别参考2
—— ArrayList(数组,随机查询快,中间插入需要移动所以消耗高,适合只在末尾插入的场景)
—— LinkedList(链表,除了首位的查询,中间查询相对会慢,添加快只需要修改指针)
—— Vector(数组,实现同步需要很高的花费,因此,访问它比访问ArrayList慢)
Map接口实现类:hashmap和hashtable区别
—— HashMap 线程不同步,value可以是null,key可以有一个null
—— Hashtable 线程同步,值不允许为空
—— TreeMap 底层红黑树,保证对象顺序,hashMap不能,需要保证统计性能或者需要对Key按照一定规则进行排序,那么使用TreeMap
Set中的HashSet,实现的是set接口,底层基于hashmap实现,只能存储单个不重复的元素,比较对象的时候通常配合重写equals和hashcode方法。
HashMap详解和三个问题 1.Java八股文 2.所以然
1.怎样解决哈希冲突
数组加链表中链表就是为了hash冲突后将元素添加在当前索引位置的连表上,还有在设计的时候数组默认容量是16,所以每次扩容都是2的n次方,为了方便在后面的与运算中计算的值更加均匀,减少hash冲突。
2.为什么用红黑树而不用别的树
在HashMap中,我们更关注插入和查找操作的性能,而不是绝对的平衡性。红黑树的查询性能只比相同内容的AVL树最多多一次比较,但是,红黑树在插入和删除上优于AVL树,AVL树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于AVL树为了维持平衡的开销要小得多。
3.HashMap为什么以2的n次方扩容**参考1 具体位与运算 参考2
在put(key,value) 时,putVal()方法中通过数组最大索引和插入key的hash值进行与运算【i = (n - 1) & hash】来计算key的散列地址,为了数据的的均匀分布,减少hash冲突。
4. k-v怎样保存 以及 get put判断流程

5.HashMap线程安全问题
jdk1.8中在put的时候有两个点:
1.计算(n-1)&hash判断数组下标之后如果A线程计算好,准备插入的时候时间片耗尽被挂起,B线程又走到这里,计算的数组下标也相同然后进行了插入。插入完成后当A线程拿到CPU继续执行时,也进行了插入,则导致B线程的值被覆盖。
2.put最后有个++size,如果A线程已经完成了++但是还未赋值时时间片耗尽被挂起,此时B线程走到这里执行了++size后A线程又执行了一遍。
6.对比Hashtable和ConcurrentHashMap
HashTable 只是单纯的在put()方法上加上synchronized。保证插入时阻塞其他线程的插入操作,性能太低。
ConcurrentHashMap对数组的每个位置使用独立的锁,CAS(Compare-and-Swap)算法、synchronized关键字以及volatile关键字确保并发性能。
具体的话,在put方法中。
首先判断容器是否初始化,在init方法中利用CAS操作保证只有一个线程正在初始化,其他线程会让出CPU资源进入就绪状态。
再判断该hash位置的节点是否为空,如果为空,则通过CAS操作进行插入。
如果该节点不为空,再判断容器是否在扩容中,如果在扩容,则帮助其扩容。
如果没有扩容,则进行最后一步,先加锁,然后找到hash值相同的那个节点(hash冲突),
循环判断这个节点上的链表,决定做覆盖操作还是插入操作。
循环结束,插入完毕。
设计模式
spring中使用的设计模式
1.策略模式,在resource接口那里,针对不同资源实现不同方式访问。平时还会考虑策略模式替代if-else
2.工厂模式,BeanFactory接口那里,通过重载getbean方法,还有其他抽象工厂的实现来管理bean的生命周期。
3.单例模式,在内存中只会创建一次对象的,需要调用的地方都共享这一单例对象,bean默认是单例模式。
4.代理模式,在AOP中选择动态代理方式(jdk还是cglib)的时候做了判断。
5.模版方法,在事务管理上,先是在接口里定义了commit和rollback方法,然后在抽象类中实现骨架,但是把docommit()和doRollback()延迟到子类。
6.适配器模式,在controller那里。
多线程
多线程基本解释
创建多线程方法
1.继承Thread类
2.实现Runnable接口
3.callable接口有返回值
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
2):可以避免java中的单继承的限制
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
4):线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类
java中ThreadPoolExecutor内置线程池 七个参数详解
public ThreadPoolExecutor(int corePoolSize, //核心线程数量
int maximumPoolSize,// 最大线程数
long keepAliveTime, // 最大空闲时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 饱和处理机制
)
重入锁
守护线程
多线程实战
workspace-home的demo中有示例
http://localhost:8080/user/export
多线程面试题集合
[interrupt()、interrupted()、isInterrupted()]
thread.stop()会立即停止,interrupt()不会立即停止,只是设置一个中断标志,
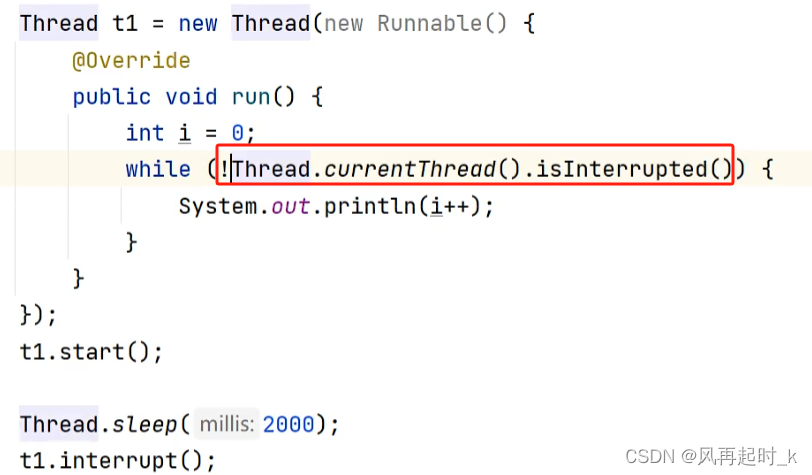
如果white中为true,即使打了中断标志也不会停止,可以用isInterrupted()判断。
interrupted()用于检测线程是否中断,以及清除中断标志位。当第二次调用这个方法的时候就会返回false。
isInterrupted()只是判断是否是中断状态。代码层面的话只是方法默认的参数里,是否需要清除标记为,上面是true它是false。
接口设计的时候你会考虑哪些问题
主要是安全和性能还有日志。
1.数据有效性,防止绕过前端校验,后端考虑添加合法性校验。
2.接口的幂等性,查询这些还好,主要是插入和修改这种需要考虑重复操作的影响。比如前端按钮重复点击,超时重试,MQ的重复消费都会造成。比如在医院项目中,插入票据信息,通过唯一的业务流水号来防止重复插入,以及退票操作等,多次退票只会成功一次,但开退票结果给到his的时候是幂等的。如果场景设计数量和金额加减这种,可以考虑对操作加锁,乐观的校验版本号字段,或者通过redis的setnx或者redisson框架的getlock、unlock做锁处理。
3.单一性和可扩展性,接口的功能尽量单一,比如针对不同票种开票逻辑不同设计业务流程改动较大,所以分别单独开设接口,这样方便后期维护。而不是类似支付方式,折扣方式这样,只影响局部策略选择,这种需要考虑可扩展,类似用策略模式替代if else来方便扩展但又不影响原代码。还有在医院打印票据的自助机服务中配置读取本地js文件的方式来做到匹配不同医院的卡号规则。
4.安全性的话,通常接口请求分为内层和外层报文,外层就是通用信息,内层是具体的业务报文,对内层通常会使用3DES,MD5加密,避免传输过程中的数据泄密。以及会有认证接口,给对接方提供帐号密码用于获取比如24小时有效的token,请求时候外层报文会有token字段,用于验证请求方是否可信。
5.接口日志尽可能详细,这也是日后维护排查的重要途径。
6.性能方面,sql的优化,索引使用,批量插入,避免大事务,使用中间件,接入redis做缓存减少数据库压力,用mq做流量控制。
springboot和springcloud的关系
一、SpringBoot是什么?
SpringBoot是一个快速开发的轻量级框架,帮助快速整合第三方常用框架,完全采用注解化(使用注解启动SpringMVC),简化XML配置,内置HTTP服务器(Tomcat、Jetty)。作用是简化Spring应用的初始搭建及开发,解决各种jar包版本冲突问题。
二、SpringCloud是什么?
SpringCloud是一系列框架的有序集合,是一个分布式服务治理的框架,本身不会提供具体功能性的操作,是一个为开发者提供快速构建分布式系统的工具。简化了分布式系统基础设施的开发,包括服务发现、服务注册、配置中心、消息总线、负载均衡、断路器、数据监控等。
三、区别和联系
1.SpringBoot专注于快速开发单个微服务,SpringCloud是将SpringBoot开发的一个个单体微服务整合并管理起来,它是关注全局的服务治理框架(RPC远程调用技术、服务治理等
2.SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系。
3.SpringBoot+SpringCloud实现微服务开发。具体就是,SpringCloud具备微服务开发的核心技术:RPC远程调用技术;SpringBoot的web组件默认集成了SpringMVC,可以实现HTTP+JSON(Restfull)的轻量级传输,编写微服务接口,所以SpringCloud是依赖SpringBoot框架实现微服务开发。
jdk8
集合之Stream流式操作
Optional类
Lambda表达式
elasticsearch
倒排索引:传统的数据索引都是id,或者序号,再到具体内容,倒排就是把关键字提取出来作为索引,通过关键字找到ID,再去找完整文章。
索引(目录)
文档(json,包含多个字段,类似一个对象)
字段(Field,好比关系型数据库中列的概念,一个document有一个或者多个field组成)
映射(字段的属性,比如具体类型,是否被索引等)
分片(类似分表,横向扩展内容,允许分布式的操作内容)
副本(类似备份,失败的情况提供高可用)
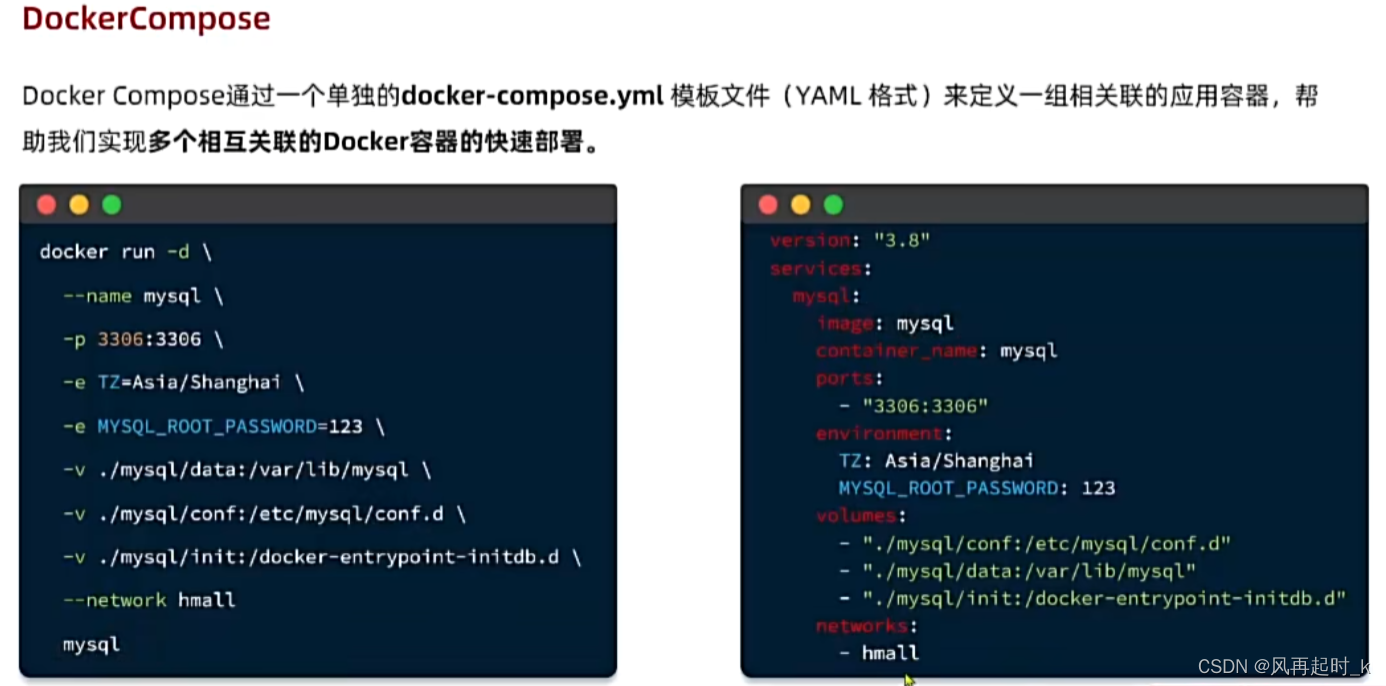
Docker

多态
多态情况下,子类和父类存在同名的成员变量时,访问的时父类的成员变量
多态情况下,子父类存在同名的非静态成员方法时,访问的是子类中重写的方法
多态情况下,子父类存在同名的静态成员变量成员方法时,访问的是父类的成员函数
多态情况下,不能访问子类独由的方法,可以向下转型再使用
变量:看左边
非静态方法:右边 子类重写的
静态同名方:左边父类的
子类独有的方法不能直接访问,可以向下转型















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









