







前言:在自然语言研究领域,某些自然语言处理任务可以利用“预训练模型+任务描述”方式的无监督学习来解决。然而,已有的“预训练模型+任务描述”的无监督学习方法不如有监督学习方法效果好。此篇论文将二者的想法相结合,提出了一种基于模板(Pattern)的半监督小样本学习方法。论文的贡献主要有两个:1)提出基于模板的半监督训练方法(PET);2)提出通过模型融合与迭代(iPET)训练多个模型,然后用训练好的多个模型给无标签数据集打软标签(soft label),以扩充标注数据集。
论文下载链接:https://arxiv.org/pdf/2001.07676.pdf
1 引言
在工业界,真正有标签的数据并不多,一般需要经过人工预处理才能得到带标签的数据集,例如,人工标注、众包等。在做自然语言处理任务时,工程师们手上的有标签数据时常少的可怜,在这种情况下,用很少的带标数据进行有监督训练往往不会有好效果。于是论文作者提出了基于模板的小样本学习方法。对于小样本学习,论文作者的想法是:对于某个自然语言处理任务,例如分类任务,仅用两个独立的句子去预测第三个句子的类别,很不好预测,因为可能的答案较多。而如果加上一些任务描述信息,会使模型更容易理解要处理的任务。作者参考了其他研究人员提出的“预训练模型+任务描述”学习方法,提出了类似任务描述的PET学习方法。
2 方法
- 概述
PET(Pattern-Exploiting Training)的核心思想是用已标注数据构建模板(Pattern),下面用一个具体实例说明如何构建模板。
例如,有个情感分类任务,label=1表示好评,label=0表示差评,即={1, 0}。现在将“1”映射为“好”,“0”映射为“差”。用词转换器(verbalizer)来表述即:v(1)=好,v(0)=差。现用训练数据集中的两个样本来举例说明什么Pattern,
x1:收到后,包装完好,笔记本封条完好, 性价比很高。1
x2:感觉好像是文科生看一本《高等数学》的教材一样,流水账一般。 0
现在我们在句首加入“很好”或“很差”,即,
很好,收到后,包装完好,笔记本封条完好, 性价比很高。
很差,感觉好像是文科生看一本《高等数学》的教材一样,流水账一般。
将“好”、“差”用掩码替换,作为训练样本喂给模型。这里我用“__”表示掩码,即
P(S):很__,S
P(x1):很__,收到后,包装完好,笔记本封条完好, 性价比很高。
P(x2):很__,感觉好像是文科生看一本《高等数学》的教材一样,流水账一般。
其中P(S)就叫模板。当然,表述方式的不同或表述文字位置的不同都可以构建出不同的模板。论文中将这种由Pattern和Verbalizer构成的组合叫作PVP。
- PVP模型训练
模型训练过程中,将P(x)喂给模型,让模型给标签词打分(如公式3-1所示),例如,在上例中,让模型给标签词表中的{好,差}分别给出一个分值,然后对所有标签词的分値进行softmax操作(如公式3-2所示),得到一个概率分布。然后用交叉熵函数计算损失
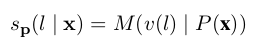
公式3-1
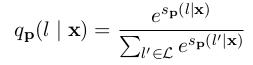
公式3-2
论文中提到可用语言模型来辅助训练,即同时也计算语言模型的损失,然后用公式3-3计算总的损失。
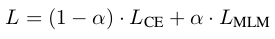
公式3-3
- 模型融合(Combining with PVPs)
在构建模板时,可以使用不同的表述,例如上例中,”很好“可改成”太棒了“,”很差“可改成”太差了“。当没有大样本验证集时,很难验证哪个模板效果好。为此,论文作者提出了模型融合的方法。具体做法如下。
1、用多套模板构建PVP,分别训练多个模型。例如,用”很好“、”很差“这套模板训练一个模型M1,用”太棒了“、”太差了“这套模板训练一个模型M2,还可能通过变换表述文字的位置构建不同的模板。以此类推,依次训练n模型。
2、然后,用训练好的n个模型给无标签数据打分,标签类别的最终得分
可以是各模型分数的加权平均,也可以直接取均值,如公式3-4所示。当
,即是取均值。
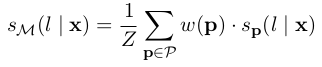
公式3-4
3、接着,将得分进行softmax得到标签类别的概率分布,最终得到打好软标签
的数据集
,也就是达到了扩充有标签数据集的目的.
4、最后,在数据集上微调(finetune)预训练语言模型PLM。
- PVPs迭代训练(iPET)
考虑到只经过一次训练,某类模板训练出的模型效果可能不好。虽然模型融合从总体上降低了因单个模型表现差而造成总体打标的错误率,但是受表现差模型的影响,依然会有不少错标样本。为此,作者提出了通过迭代训练的方法来提升总体性能。具体步骤如下。
1、在原始标注数据集上,用n种模板构建n个PVP训练样本集,在每个PVP样本集上分别训练n个模型
.
2、随机选择个模型为一组,
,对未标注数据集
进行模型融合打标,得到n个带标数据集
,数据集大小是前一轮次的
倍,且样本集保持标签均衡。然后将原始数据集
与
合并,得到
。按此法依次迭代
轮,得到迭代训练后的n个模型
.
3、用对未标注数据集
进行模型融合打标,得到
.再用
训练分类器
.
3 实验
在几个公开数据集上,论文作者用预训练模型RoBERTa做了实验,每个数据集使用多套模板进行训练。论文中显示,样本数量在0、10、50、100情况下,PET方法的效果大比分碾压supervised方法。
本人也在购物评论数据集上做了实验。该数据集有正负样本两类,分别为好评和差评。采用BERT预训练模型,训练参数:learning rate=1e-5,batch size=16。因为有些评论文字较多,所以设置序列最大长度为512。构建的模板格式如下,
很好,收到后,包装完好,笔记本封条完好, 性价比很高。
很差,感觉好像是文科生看一本《高等数学》的教材一样,流水账一般。
采用上述模板格式,从训练集中分别选取10、50、100、1000、2000个样本构建PET模板进行实验。没有采用模型融合,也没有采用iPET迭代模型。用包含2000个样本的测试集进行测试,测试结果如下表所示。
| 训练样本数 | 方法 | 分类精度(%) |
|---|---|---|
| 10 | supervised | 46.85 |
| PET | 82.71 | |
| 50 | supervised | 77.50 |
| PET | 85.08 | |
| 100 | supervised | 87.26 |
| PET | 86.74 | |
| 1000 | supervised | 90.43 |
| PET | 90.43 | |
| 2000 | supervised | 92.04 |
| PET | 90.86 |
从上表可以看出,PET方法在样本数为10和50时,分类精度大比分碾压普通的监督学习方法。但是,在样本数为100时,PET方法的精度虽然较50个样本有所提升,但提升不多。而且,较普通的监督学习方法精度略低一点。本人认为可能是我的模板不是很好。应该通过多套模板使用模型融合。从上表中还发现,样本数从1000增加至2000,PET方法效果的提升已经不太明显。这反映出PET方法在大训练集上没有优势。不过,要想得到更加肯定的结论,还需要在多个模板上进一步做实验。
4 消融实验分析
论文作者主要从以下几方面做了消融性实验分析。
1、单模型与多模型融合对比实验。论文作者通过实验发现,好模板与差模板的效果差别还是有点多。基于单模板训练的单模型明显没有基于多模板训练得到的多模型融合效果好。此外,多个模型打分是取平均值还是取加权平均,效果差别不大。
2、通过对比是否采用语言模型作为辅助训练,作者分析发现,在训练集只10个样本的情况下,用语言模型辅助训练可以获取更好的效果。随着样本数量的增加,效果逐渐下降,甚至起了反作用。
3、在iPET方面,论文作者分析了每一代模型的性能表现。作者发现性能表现逐代变好。作者还尝试减少两次迭代,直接扩充无标签样本数量让模型打标。结果发现这种做法效果并不好。作者猜想可能的原因是,让没能经过充分迭代的模型打标太多的样本,会产生大量的错误标注。
5 总结与思考
本篇论文主要提出了采用构建模板的方式进行小样本学习的方法。作者还提出采用模型融合和模型迭代训练来提升总体效果和稳定性。本人认为,采用论文提出的方法做项目,前期的主要顾虑可能是,构建模板时不确定当前模板是不是好模板。因为是人工构建模板,如果构建的模板不好,既浪费了时间又浪费了精力。此外,因为本文方法属于小样本学习,采用小样本去微调像GTP3那样巨大的模型,不知道是否可行。
[参考文献]
Schick T, Schütze H. Exploiting cloze questions for few shot text classification and natural language inference[J]. arXiv preprint arXiv:2001.07676, 2020.

















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











