






文章目录
论文题目
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
概况
- 类别:论文
- 标签:重建、 Pose Estimation、novel、RGB
- 发表刊物 / 会议 时间:2024/5
背景 (说明所做的问题、解决该问题的意义、简述现有方法存在的问题)
需要注意
- 新的虚拟相机系统,始终指向物体中心—可简化位姿估计?需要注意虚拟相机与真实相机的gap
- 用sdf做对象表示—使用NeuS和MLP提取
1.问题
- 现有的重建方法大多依赖SFM,但基于SFM的方法要求相机/物体一方静态,不适合手交互移动,且对于无纹理的效果不好
- 一些方法不用sfm,而是将序列分段处理联合优化,容易陷入局部最优
主要创新点(先一句话描述该文所做的事情,再分点讲创新点)
一句话:
提出了一种物体重建和位姿估计联合建模的框架,且对于输入的RGB,没有任何先验要求(相机和物体都可以任意移动)也不知道pose
创新点
- 研究了现有方法在从RGB单目视频重建自由运动物体中的问题。
- 提出了一种简单但有效的虚拟摄像机系统策略,该策略简化了目标轨迹,并显著减少了优化的搜索空间。
- 在使用固定或以自我为中心的相机的数据集上证明了我们的方法的有效性
方法
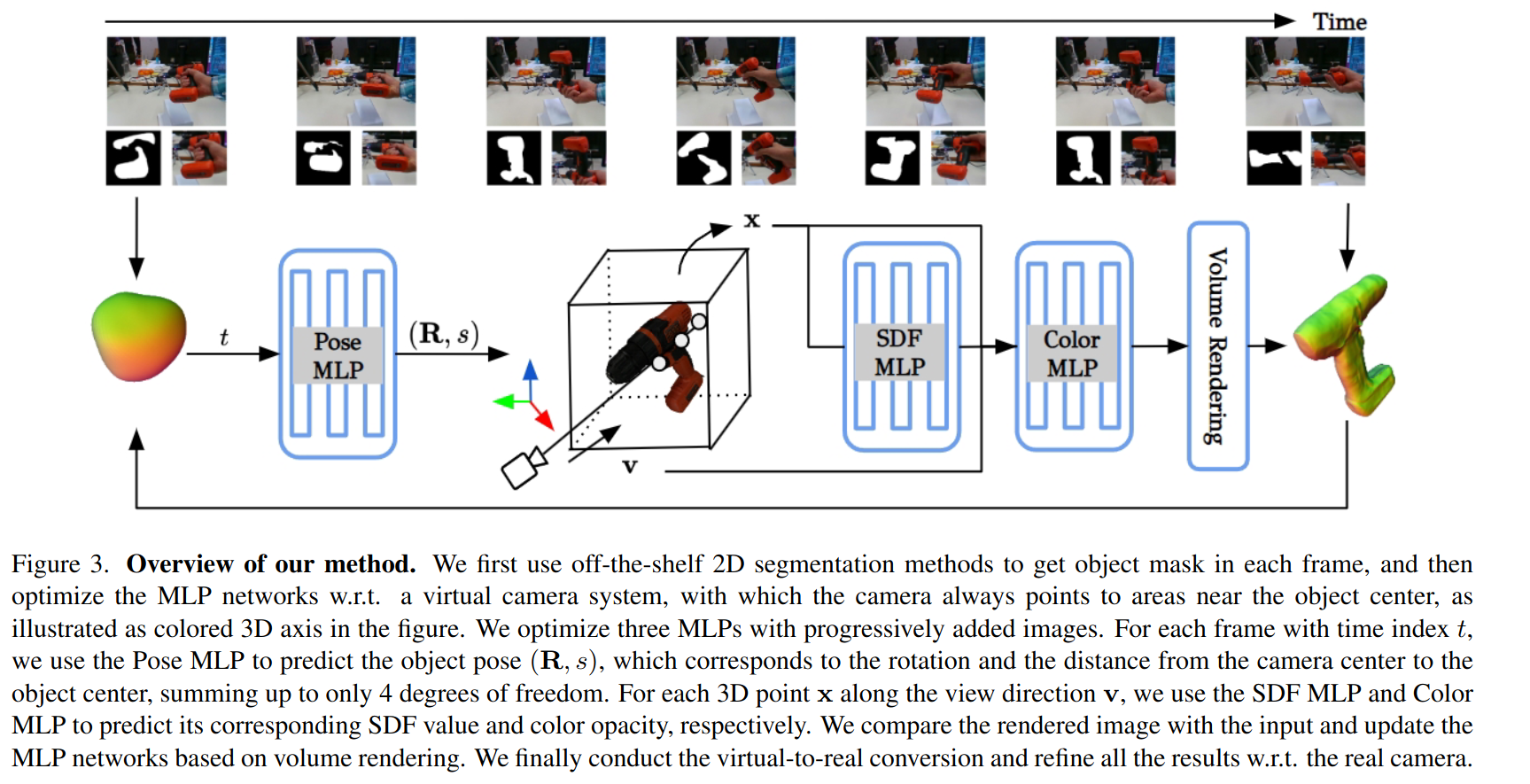 pose和重建联合建模,不断refine的过程
pose和重建联合建模,不断refine的过程
- crop通过PoseMLP预测虚拟相机下的位姿R,s
- sdf重建
- 位姿转换到真实相机,refine的过程
3.1 数据及表示
- 对于输入数据只要求在视角内,不需要任何信息,包括pose和2D bbox(用分割方法获得mask)
- 使用SDF进行对象表示, NeuS预测sdf距离d,MLP预测color c
3.2 虚拟相机系统
-
针对问题:传统的相机姿态和辐射场的点优化只能处理前向场景,如果图像覆盖了更大的视点范围或连续图像之间存在一些较大的姿态变化,则无法收敛,如图
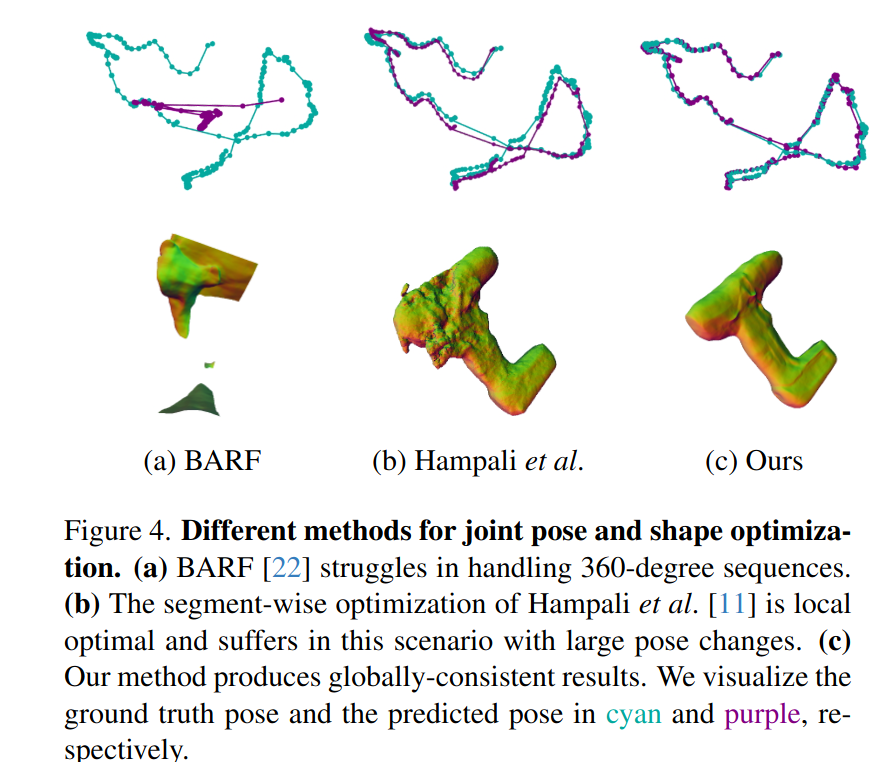
-
相机定义:假设已知真实相机内参K,则有
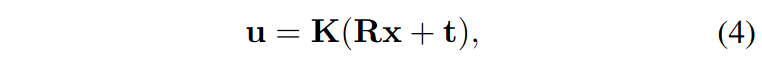
在对图像u做crop时,相当于用操作矩阵M。设虚拟相机参数为Kv,则有
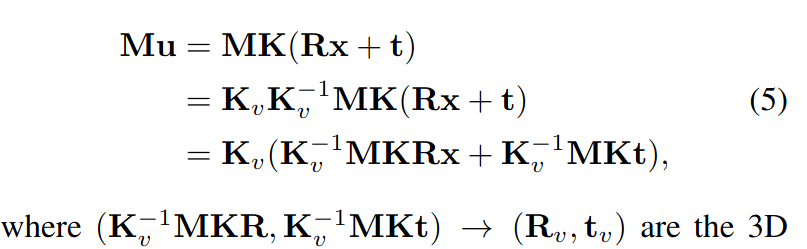
所以对于crop,在虚拟相机下,直接预测**Rv、tv**即可 -
意义:虚拟相机始终是朝向物体中心的,真实相机下预测位姿是6D的,而虚拟相机只有4D(3维旋转和1维distance)
如图,只需要1维distance是因为虚拟相机系统下,正对中心,相当于冲着y轴,不需要x、z轴信息

3.3 Refinement with Real Camera
此前预测的Rv、tv在虚拟相机下,与目标不符合,这里采用PnP将Rv、tv转换为RT
- 从重建点云中采样一组点,用Rv、tv将其映射到虚拟相机系下的2D图像MU中
- 乘M-1得到U
- U与重建点云做PnP
既然是PnP为什么不直接用采集的U和重建点云做?---->3.2提到的,传统方案只应对前向场景


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









