






文章目录
论文题目
GS-Pose: Cascaded Framework for Generalizable
Segmentation-based 6D Object Pose Estimation
概况
- 类别:论文
- 标签:6-Dof、 Pose Estimation、novel、RGB
- 发表刊物 / 会议 时间:2024/3
背景 (说明所做的问题、解决该问题的意义、简述现有方法存在的问题)
1.问题
- novel物体姿态估计上现有工作大都依赖CAD,而获取CAD的成本是高昂的
- onepose系列通过用一系列RGB图重建点云来规避CAD,但由于通过2D-3D对应的方式(需要关键点)来估计位姿,对无纹理物体效果很差,且需要2D边框来做crop
- Gen6D为依赖RGB的novel估计工作提出框架:物体定位、初始姿态估计和姿态细化。然而,仅依赖于2D表示通常会导致次优性能
主要创新点(先一句话描述该文所做的事情,再分点讲创新点)
一句话:
将3D Gaussian Splatting应用在位姿估计中,提出仅基于RGB的novel物体姿态估计框架
创新点
- 新的多阶段框架用于物体定位和6D姿态估计。对于每个阶段,我们提出了从以前未见过的对象的一组姿态RGB图像中获得的优化表示。
- 提出了一个通用的共分割方法,用于从参考RGB图像中提取物体分割掩模。这些掩模可以进一步用于表示学习。
- 3D Gaussian Splatting用于refine
方法
对于一个novel物体的估计分为两个部分:
- 对于参考RGB图(有pose)建立起数据库:seg表示Fobj、旋转感知的嵌入向量V、高斯对象表示G
- 对于目标RGB进行推理:定位、位姿初始化(基于检索)、pose refine(render-compare)
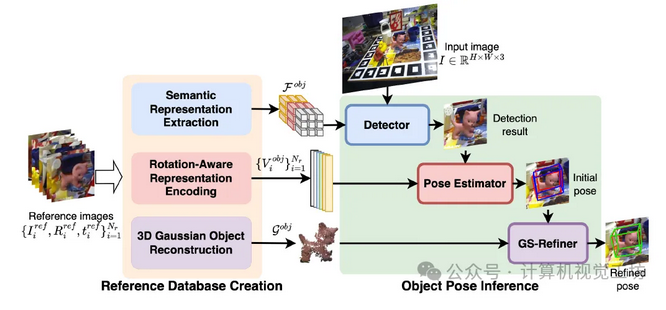
一、数据库建立(prompts)
分为三步进行
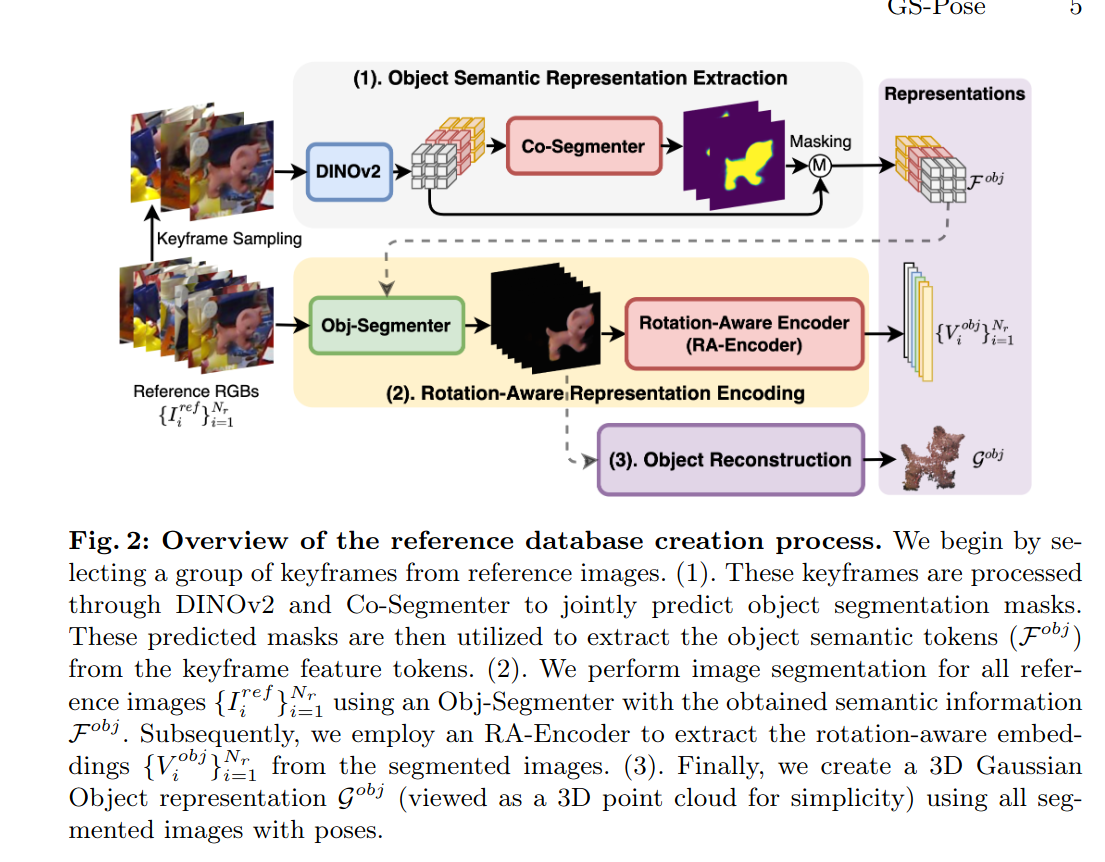
1.1 Semantic Representation Extraction.
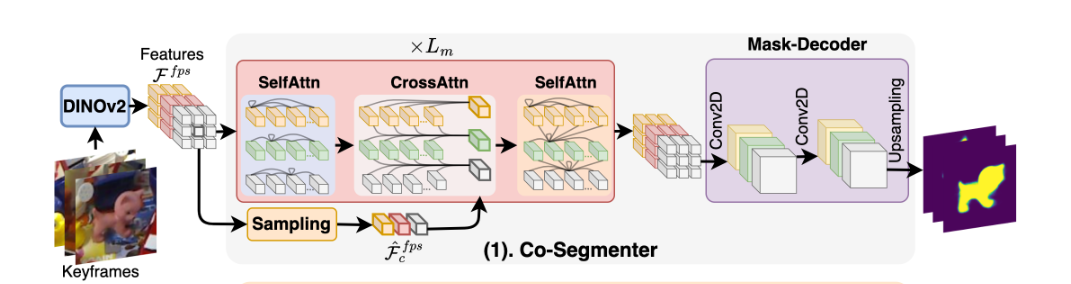
这一步的目标是获得 object semantic tokens(Fobj),用于指导分割
- 对参考图的pose label进行FPS采样得到关键帧
- 关键帧经过DINOv2提取特征Ffps
- co-seg的作用是将目标从背景中分离,这样就可以从Ffps中筛选出目标区域的特征
1.2 Rotation-Aware Representation Encoding.
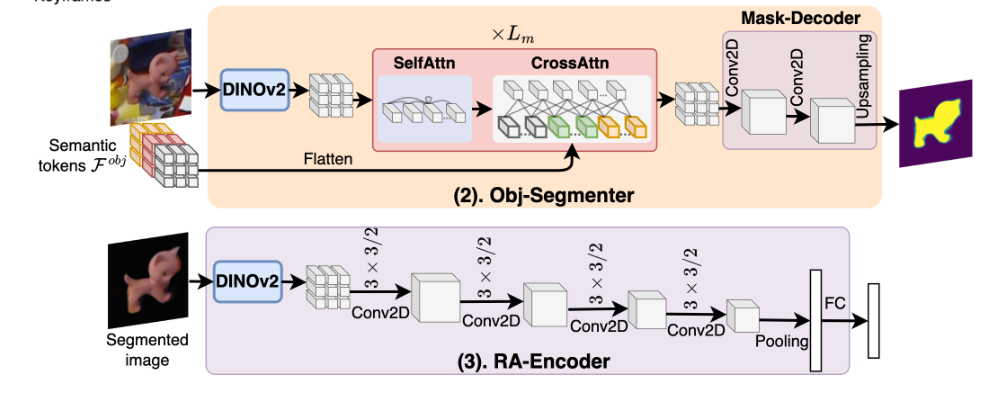
这一步是为了对参考图的pose进行编码,用于推理时直接检索一个作为初始位姿
- 每张参考图&token得到分割
- RA-Encoer编码pose
1.3 3D Gaussian Object Reconstruction.
这一步是将参考图重建为3D Gauss表示,用于pose refine
二、位姿推理
也是三步进行:定位、pose init、pose refine
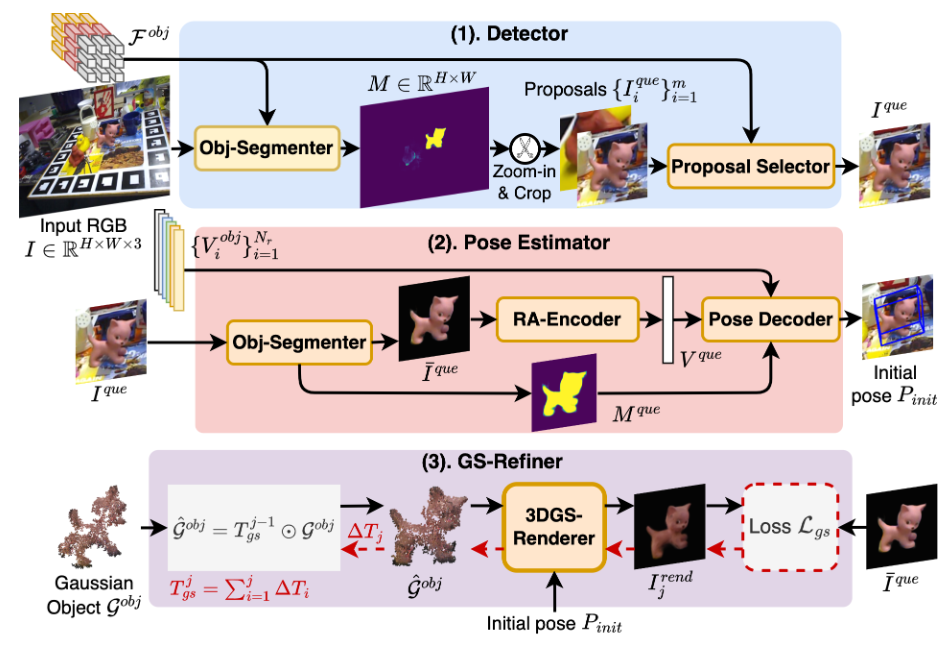
2.1 物体定位
目的是得到 crop(onepose系列必须有2d bbox)
2.2 Pose Estimator
本质是在数据库中找到一个最接近的pose作为初始化
- 输入crop到obj-seg中得到mask和去背景图I,I经过编码得到V
- 计算V与数据库中的v的相似分,分最高的参考rot为初始rot
- 分最高的参考与seg出的mask计算出初始T
2.3 GS-Refiner.
设delta P为Tgs,不断迭代,最终pose为PinitTgs
迭代公式为
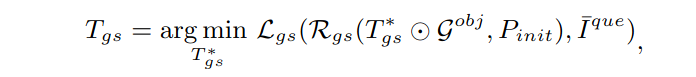
- 圈表示对重建G进行位姿变换
- T=【R,t】
- R(x,p)指对X按照P进行渲染
实验
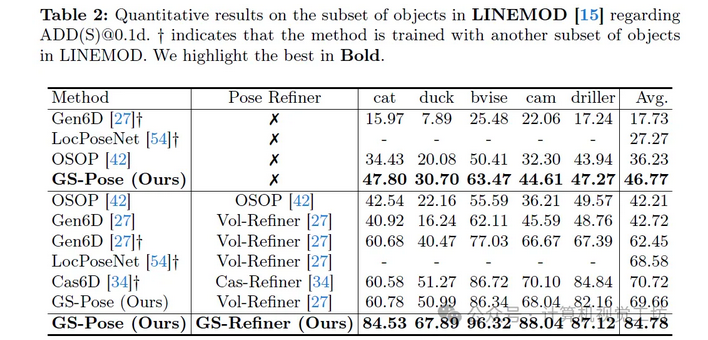
思考
- 只看pose推理,是init&redfine,且基于render-compare,其实和fdp比较类似















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









