







Pandas 学习笔记
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据)
一、Pandas 数据结构 – Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
实例:
1.用列表实例
import pandas as pd
a=[1,2,3]
myvar=pd.Series(a)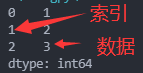
print(myvar) #如果没有指定索引,索引值就从0开始
print(myvar[1]) #也可以指定索引值,根据索引值读取数据 输出为:2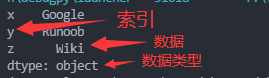
a=["Google","Runoob","Wiki"]
myvar=pd.Series(a,index=["x","y","z"])
print(myvar)
print(myvar["y"]) #输出为:Runoob2. 使用 key/value 对象,字典来创建 Series:
sites={1:"Google",2:"Runoob",3:"Wiki"}
myvar=pd.Series(sites)
print(myvar)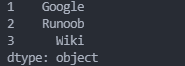
字典的 key 变成了索引值,如果只需要字典中的一部分数据,只需要指定需要数据的索引即可
sites={1:"Google",2:"Runoob",3:"Wiki"}
myvar=pd.Series(sites,index=[1,2])![]()
#设置 Series 名称参数:
sites={1:"Google",2:"Runoob",3:"Wiki"}
myvar=pd.Series(sites,index=[1,2],name="RUNOOB-Series-TEST")

二.、Pandas 数据结构 – DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。Pandas DataFrame 是一个二维的数组结构,类似二维数组。
图示说明:
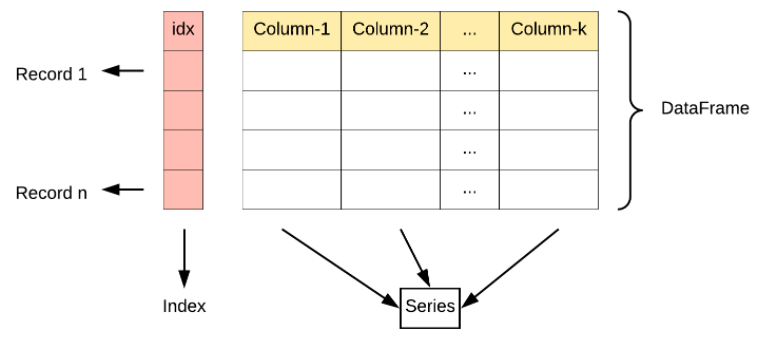
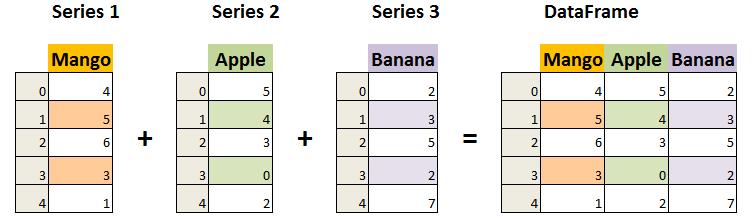
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
实例:
1.用列表创建
data=[['Google',10],['Runoob',12],['Wiki',13]]
df=pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)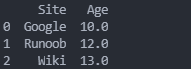
2.用ndarrays创建
ndarray 的长度必须相同, 如果传递了index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
data={'Site':['Google','Runoob','Wiki'],'Age':[10,12,13]}
df=pd.DataFrame(data)
print(df)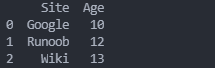
3.用字典(key/value),其中字典的 key 为列名创建, 没有对应的部分数据为 NaN。
data=[{'a':1,'b':2},{'a':5,'b':10,'c':20}]
df=pd.DataFrame(data)
print(df)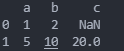
# 可以使用loc属性返回指定行的数据,如果没有设置索引,第一行索引为0,第二行索引为1,以此类推:
data={
"calories":[420,380,390],
"duration":[50,40,45]
}
# 数据载入到 DataFrame 对象
df=pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])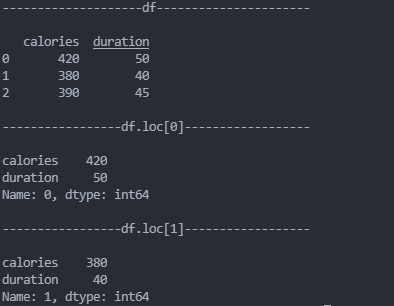
注意:返回结果其实就是一个 Pandas Series 数据。
# 也可以返回多行数据,使用[[ ... ]]格式,...为各行的索引,以逗号隔开:
print(df.loc[[0,1]])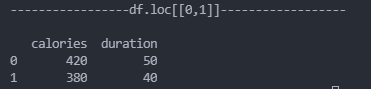
# 可以指定索引值
data={
"calories":[420,380,390],
"duration":[50,40,45]
}
df=pd.DataFrame(data,index=["day1","day2","day3"])
# 指定索引
print(df.loc["day2"])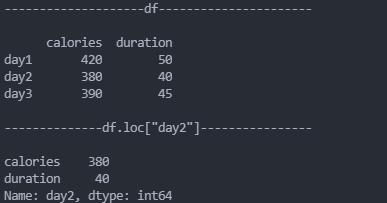
# 获取 dataframe 中其中几列
data = {
"mango": [420, 380, 390],
"apple": [50, 40, 45],
"pear": [1, 2, 3],
"banana": [23, 45,56]
}
df = pd.DataFrame(data)
print(df[["apple","banana"]])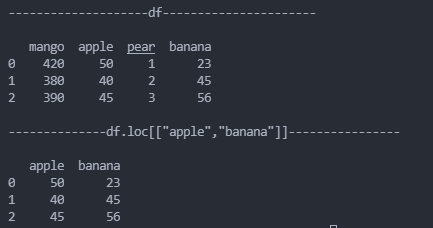
#利用append()命令,以Series格式向DataFrame中添加一行
data = {
"mango": [420, 380, 390],
"apple": [50, 40, 45],
"pear": [1, 2, 3],
"banana": [23, 45,56]
}
df = pd.DataFrame(data)
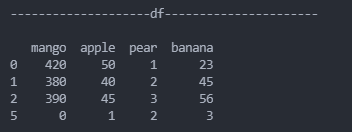
df = df.append(
pd.Series(
[0,1,2,3], # 对应DataFrame中的data
index=["mango","apple","pear","banana"],# 对应DataFrame中的columns
name=5, # 对应DataFrame中的index
)
)
其他函数:
idxmax()函数:获取pandas中series最大值对应的索引
data = {
"mango": [420, 380, 390],
"apple": [50, 40, 45],
"pear": [1, 2, 3],
"banana": [23, 45,56]
}
df = pd.DataFrame(data)
df = df.append(
pd.Series([0,1,2,3], # 对应DataFrame中的data
index=["mango","apple","pear","banana"], #对应DataFrame中的columns
name=5, #对应DataFrame中的index
)
)
print("\n--------------------df----------------------\n")
print(df)
# 指定索引
print('\n--------------df.loc[0,:]----------------\n')
m =df.loc[0,:]
print(m)
m = m.reindex(np.random.permutation(m.index))#打乱顺序,避免每次选择的动作都为序号偏前的动作
c = m.idxmax()
print("\n--------------------idxmax()----------------------\n")
print(c)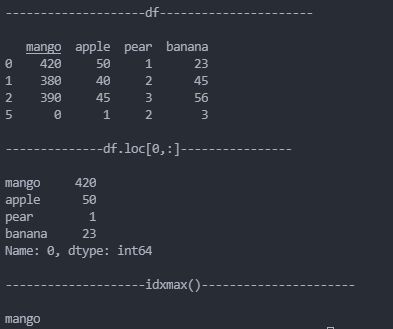
三、Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
(1)读CSV文件
import pandas as pd
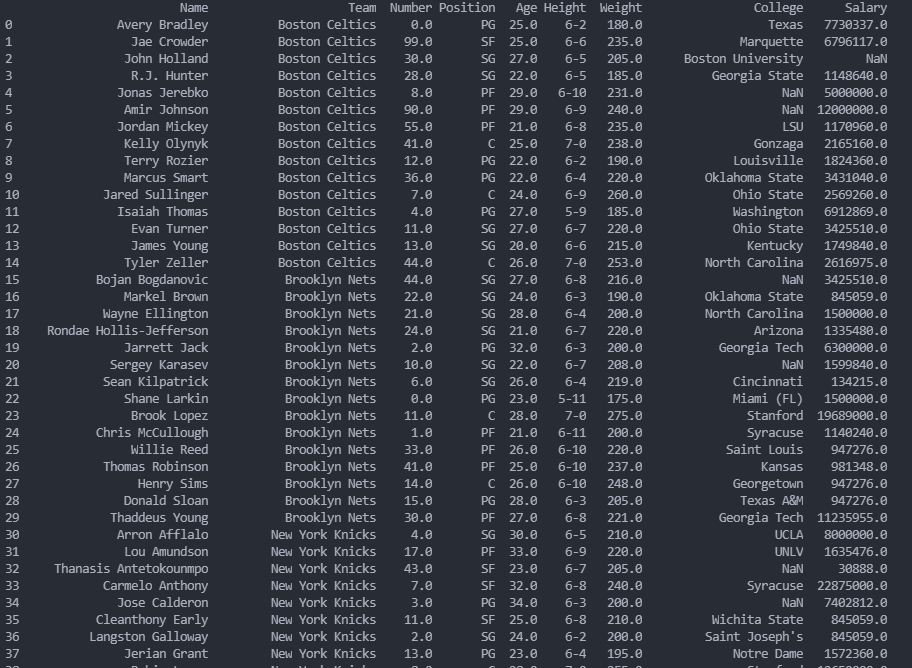
df = pd.read_csv('nba.csv')
print(df.to_string())to_string()用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以...代替。
(2)写CSV文件
我们也可以使用to_csv()方法将 DataFrame 存储为 csv 文件:
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')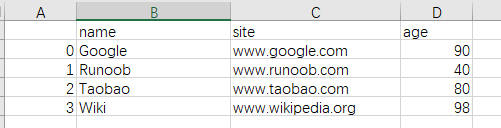
(3)数据处理
head(n)方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())tail(n)方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回NaN

import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
info() 方法返回表格的一些基本信息:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())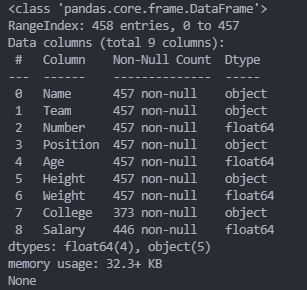















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









