






背景:
能够理解视觉场景是许多下游任务的先决条件,包括自动驾驶、机器人和其他基于视觉的方法。能够对视觉数据进行推理的一种常用方法是场景图生成(Scene Graph Generation, SGG)。然而,许多现有的方法都假设视觉不受干扰,即没有现实世界的干扰,如雾、雪、烟,以及太阳眩光或水滴等非均匀扰动。在这项工作中,我们提出了一种新的SGG基准,包含程序生成的天气损坏和视觉基因组数据集上的其他转换。此外,我们引入了一种相应的方法,层次知识增强鲁棒场景图生成(HiKER-SGG),为在这种具有挑战性的环境下生成场景图提供了一个强大的基线。在其核心,HiKER-SGG利用层次知识图,以便将其预测从粗略的初始估计细化到详细的预测。
论文地址: 点击这里
代码地址:点击这里
简述:
文章认为现有的场景图任务都是基于“干净”的图像,即默认场景图生成任务的输入都是无损,未受到干扰的图像。而针对现实世界,我们需要应对各个因素的干扰。作者认为应当贴近现实世界,面对更贴近真实的图像进行场景图生成任务,因此提出了HiKER-SGG,层次知识增强鲁棒场景图生成,针对这种具有挑战的环境下生成场景图。并针对这个挑战引入了基于Visual Genome的 Corrupted Visual Genome(VG-C)--它提供了20个程序生成的图像损坏,类似于普通变换和各种天气条件,其填补了该领域的一个重要空白。
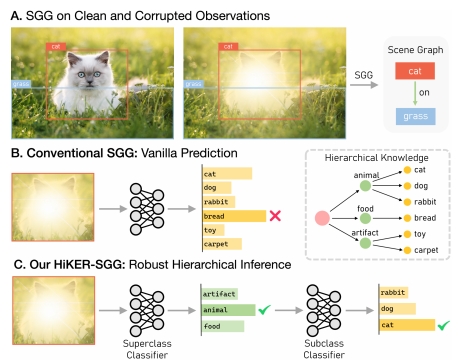
Figure1:本文引入一个新任务,现实存在的腐败(?)鲁棒场景图生成。以图1(A)所示,左图是无损的图像,而右图是受到光晕干扰的图像,我们需要针对右图的挑战下做出正确的场景图生成任务。以图1(B)所示,传统的SGG,是直接对图像中的目标进行预测。而本文提出的HiKER-SGG则是先进行粗粒度的预测,再进行细粒度的预测。如图1(C)所示,先对光晕遮挡的对象进行粗粒度的预测,预测其为animal,而后再对其进行细粒度的预测,预测其为cat。
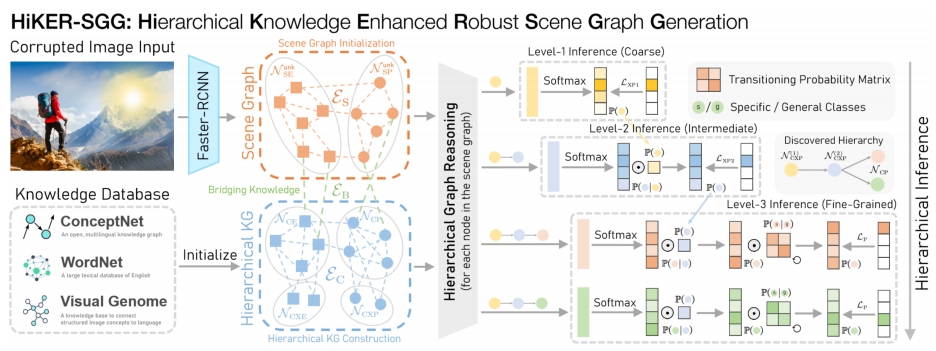
HiKER-SGG:
1、符号定义:
给定数据集图像记作 I,SGG的目标是生成一个有向场景图 G={N,E},其中场景图的每个节点Ni ∈ N 表示为一个具有边界框Bi 和对象类 的对象,每条边 Ei ∈ E表示为两个对象之间的谓词类
。一个良好的场景图G包含一个视觉关系三元组 <subject-predicate-object>的集合,用于全面描述图像 I。
2、两阶段范式:
HiKER-SGG遵循两阶段范式,先使用现成的对象检测网络(例如:Faster-RCNN)和特征提取网络(例如:ResNet),从两个实体之间的联合框中提取特征表示其关联谓词。
3、层次结构
我们可以手动设置类的层次关系,但是手动设置层次结构会引入主观性,将会影响到在生成无偏场景图任务的能力,为了解决这个问题,本文采用了分层聚类方法,该算法能够基于相似度度量揭示多级聚类,以发现实体和谓词类的分层结构。层次聚类中使用的相似度函数是以下两个相似度的加权和:
(1)语义相似度:使用GloVe词嵌入 计算每对实体和和谓词之间的余弦相似度
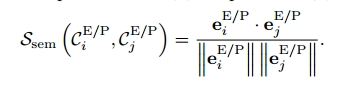
(2)模式相似度:使用MotifNet在VG数据集上为实体和谓词生成混淆矩阵,每个矩阵条目
表示实际类为i而预测类为j的可能性(在0到1之间)。 认识到相似的类通常具有可能混淆我们模型的相似模式,我们基于基线方法在实体和谓词对之间错误分类的概率来计算相似度,表示为
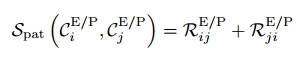
4、层次知识构建
常识知识图谱:构建了一个不分层的常识性知识图,它的边缘充当了与物体相关的一般知识的信息库,例如:猫是动物,人穿衬衫。我们将这个常识图定义为一个包含常识性实体(CE)节点的set以及一个包含常识性谓词(CP)节点
的set。常识图
存储了两个set中每对节点之间的关系。
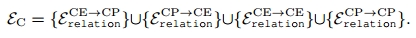
我们利用它们的词嵌入的线性投影初始化和
的节点特征
和
。
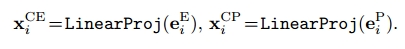
层次常识知识图谱:在常识图中引入 “超类” 代表一组节点的总体类别。常识超类实体记作,常识超类谓词记作
。这些超类节点的初始表示是通过与其相关联的
个子类节点的平均表示建立的。

此外还建立了超类之间以及超类和普通类之间的连接,这些边能够便于消息传递还支持超类节点的更新,因此常识图的边最终可以表示为。

5、场景图构建
(1)一个场景实体节点和一个边界框相关联
(2)一个场景谓词节点和一对场景实体节点相关联
因此场景图中的有向边可以定义为
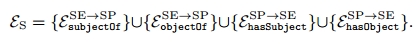
但是我们的预测任务,并不清楚实体的类别和谓词的类别 因此我们将场景图实体表示为,场景图谓词表示为
。 unk表示未知。
(3)初始化场景图节点特征: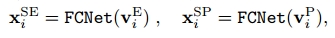 实体节点使用ROIAlign特征进行初始化,谓词节点使用联合区域ROIAlign特征进行初始化。(这两个FCNet的权重不共享)
实体节点使用ROIAlign特征进行初始化,谓词节点使用联合区域ROIAlign特征进行初始化。(这两个FCNet的权重不共享)
6、建立分层知识和SGG的桥梁

将场景图中的实体和谓词连接到常识图中相应的标签,以方便训练过程中相互信息流动。
首先将每个SE节点连接到多个CE节点,并根据Faster-RCNN预测的标签分配权重,SP节点和CP节点之间的边开始是个空集,在消息传播期间更新。 使用变种的GGNN来更新节点表示,并使用GRU更新规则在节点之间传播消息

Φ ∈ {SE,SP,CE,CP,CXE,CXP}.
每次消息传播迭代后,计算每个SE/SP节点与所有CE/CP节点的相似度:
两两相似度量化了场景节点和常识节点之间的连接,用于在每次迭代后更新桥边的权重。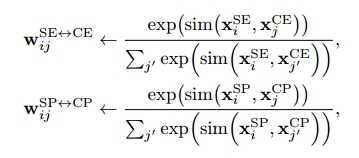
和
分别表示SE/SP 和 CE/CP 节点对的双向桥边的共享权值,在消息传播迭代t次后,可以利用图中的节点来判断SE/SP节点的类别。
7、分层推理
利用两个图中更新的节点表示,我们提出通过分层推理过程确定每个未知SE/SP节点的类别。这里,我们只介绍谓词分类的推理过程。同样的范例也适用于实体节点。
此处用三级结构层次来作例,这个层次数是可以改变的,以适应更加复杂或更加简单的情况:在三级层次结构的情况下,CXP节点可以分为两组最高级节点用表示,第二级用
表示,子类节点用
,它们之间的关系是
。对应的谓词类由高到低分类顺序是
.
具体来说,我们首先计算每个SP节点的节点表示与层次知识图中更高级的CXP节点之间的相似度以确定第一级超类概率,表示为: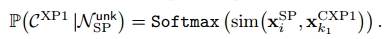
k1表示第一级超类,表示为一级超类节点的节点表示。
一旦确定SP节点的一级超类,则计算其与对应一级超类下的二级超类谓词概率。 符号表示同上
符号表示同上
最终计算SP节点的子类谓词的概率:
一般情况下,给定一个未知的谓词节点,每个谓词类别的预测概率可以通过将上面导出的三个概率相乘来计算: 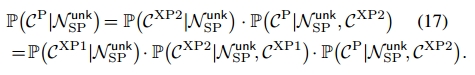
8、自适应细分
我们将自适应细化机制集成到我们的模型中,以减轻谓词类中的偏差。这种增强的目的是预测更具体和信息丰富的谓词(例如,standing on, sitting on),而不是一般的谓词(例如,on)。从本质上讲,我们的目标是找到可以将一般预测转换为谓词类的更具体预测的转换概率。具体来说我们采用基于MotifNet生成的谓词混淆矩阵,然后,我们通过对角增广混淆矩阵的行归一化来创建一个转移概率矩阵: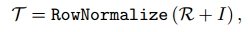 其中I表示与混淆矩阵R大小相同的单位矩阵,转移概率
其中I表示与混淆矩阵R大小相同的单位矩阵,转移概率可以用一个特定的条目
表示。因此将17式改写为:
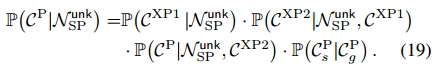
在训练阶段,我们的目标是揭示谓词类之间更深层次的相关性,促进更细粒度的预测。因此,我们建议在每个训练轮次之后在训练数据集上重新评估我们的SGG模型,以获得如下式(18)的新T m。然后,我们使用加权线性组合将该矩阵与前一epoch的矩阵混合: 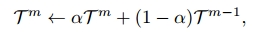
其中m表示当前epoch索引,α是控制更新速率的超参数。更新后的矩阵将在下一个训练历元中用于谓词分类。
在训练阶段,我们使用以下损失项更新参数。用于更新超类和子类的预测: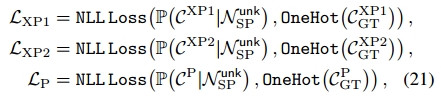
其中和
分别表示超类和子类谓词的真值标签。
实验:
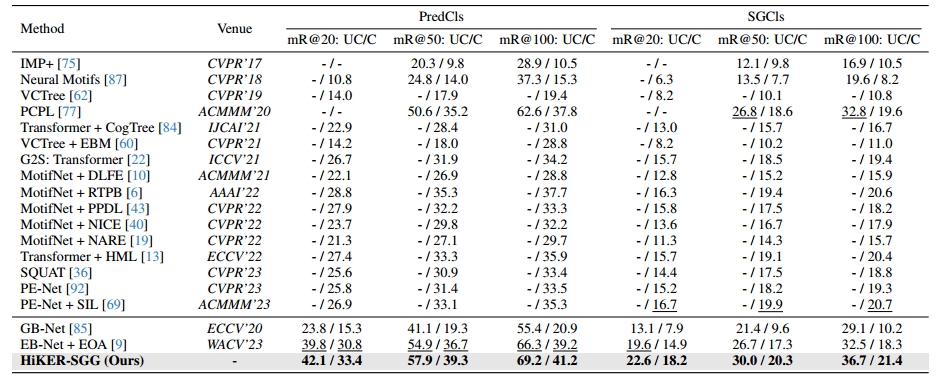
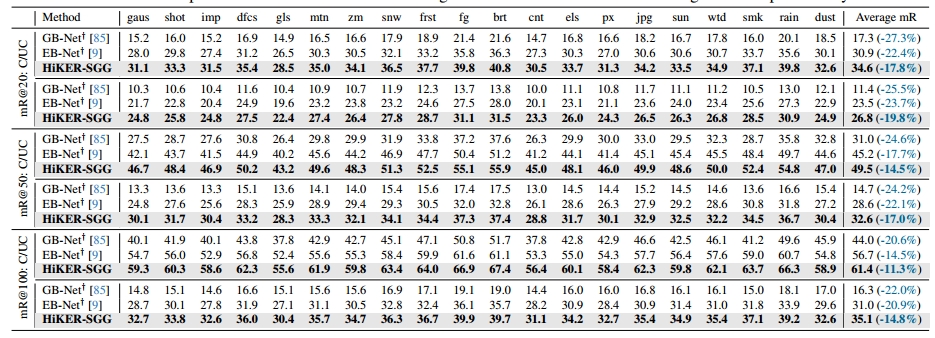
在VG数据集上进行训练















 2072
2072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









