







回归问题评价指标
1、MAE——平均绝对误差
绝对误差的平均值,能反映预测值误差的实际情况。取值越小,模型准确度度越高。
公式:
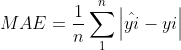
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true, y_pred) # y_true为真实值,y_pred为预测值
2、MSE——均方误差
预测值与实际值之差平方的期望值。取值越小,模型准确度越高。
公式:
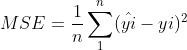
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred) # y_true为真实值,y_pred为预测值
3、RMSE——均方根误差
又叫标准误差,是均方误差的算术平方根,该结果与实际数据的数量级一样。取值越小,模型准确度越高。
公式:
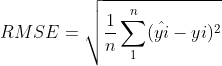
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred) # y_true为真实值,y_pred为预测值
rmse = Sqrt(mse)
4、MAPE——平均绝对百分比误差
是 MAE 的变形,它是一个百分比值。取值越小,模型准确度越高。
公式:
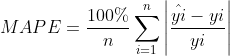
MAPE = np.mean(np.abs((y_test - y_pred)/y_test))
5、 R 2 R^2 R2
将预测值跟只使用均值的情况下相比。取值范围一般[0,1],结果越靠近 1 模型准确度度越高,结果越靠近 0 直接瞎猜准确度更高,结果为 负数 直接平均值乘以2倍准确度更高。
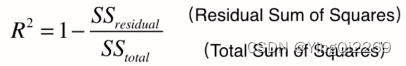
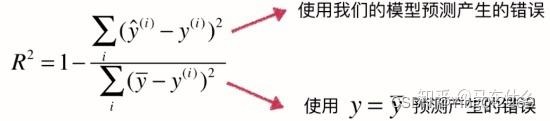
from sklearn.metrics import r2_score
r2 = r2_score(y_true, y_pred) # y_true为真实值,y_pred为预测值
分类问题评价指标
分类问题中,又可以分为二分类和多分类问题:
二分类问题:accuracy、precision、recall、F1-score、AUC、ROC曲线
多分类问题:accuracy、宏平均、微平均、F1-score
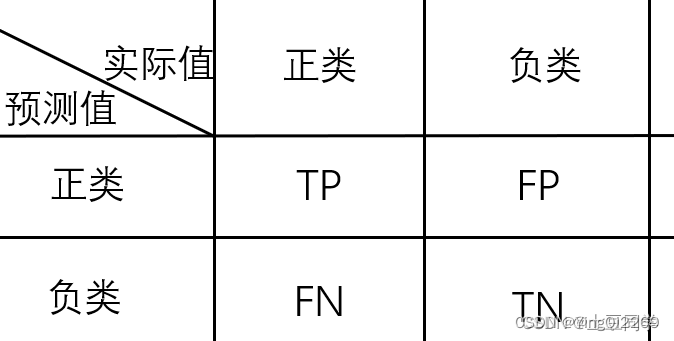
TP 表示将实际标签为正的样本判断为正的样本数量或者比例;
FP 表示将实际标签为负的样本判断为正的样本数量或者比例;
FN 表示将实际标签为正的样本判断为负的样本数量或者比例;
TN 表示将实际标签为负的样本判断为负的样本数量或者比例。
1、准确率Accuracy
表示所有的预测样本中,预测正确的比例,计算方法如下:

2、精确率Precision
表示预测为正样本的样本中,实际为正样本的比例。精确率考虑的是正样本被预测正确的比例。计算方法如下:

3、召回率Recall
表示实际为正样本的样本中,预测为正样本的比例。召回率考虑的是正样本的召回的比例。计算方法如下:

4、F1-socre
其实精确率和召回率之间是存在矛盾的,很多场景下,模型最终结果往往实在精确率和召回率之间找到平衡点。F1-socre是兼顾精确率和召回率的参数,之所以使用调和平均而不是算术平均,是因为在算术平均中,任何一方对数值增长的贡献相当,任何一方对数值下降的责任也相当;而调和平均在增长的时候会偏袒较小值,也会惩罚精确率和召回率相差巨大的极端情况,很好地兼顾了精确率和召回率。F1-socre计算方法如下:

5、AUC值及ROC曲线
AUC(Area Under ROC Curve)值为ROC 曲线下面积,表示模型或预测结果的可靠性,越接近1,可靠性越高。
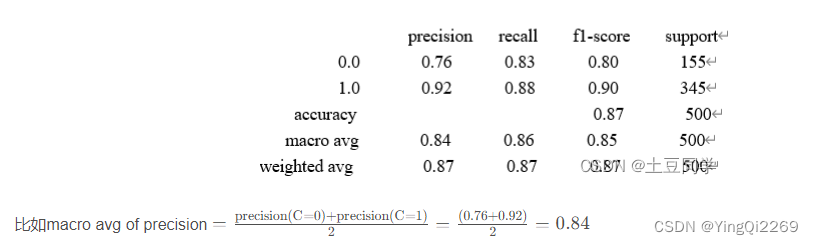
6、Macro avg(宏平均)
Macro avg(宏平均)在为每一指标计算时,会对每一类别赋予相同的权重,即每个类别的指标的算术平均值。可能理解起来比较抽象,看以下例子:
7、Micro avg(微平均)
Micro avg(微平均)为所有类别的准确率,即所有预测正确的样本数量的比例:
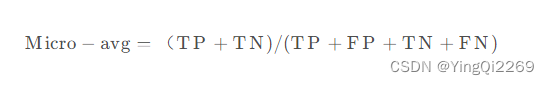
TP实际标签为正的样本判断为正的样本数量;TN 表示将实际标签为负的样本判断为负的样本数量
TP + FP + TN + FN表示所有样本数量
8、weighted-avg(权重平均)
weighted-avg(权重平均)是因为宏平均在计算的时候,每个类别赋予的权重相同,但如果存在样本不平衡的情况,那这种方法就不太公平,所以权重平均便根据每个类别的样本数量,赋予不同的权重。权重平均其实就是所有类别的f1加权平均,主要针对F1值,计算方式如下:
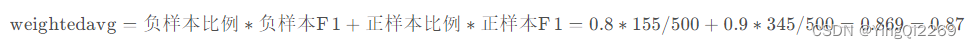
图像质量的客观评估指标
1、结构相似性指数(structural similarity index,SSIM)
结构相似性指数(structural similarity index,SSIM)是一种用于量化两幅图像间的结构相似性的指标。与L2损失函数不同,SSIM仿照人类的视觉系统(Human Visual System,HVS)实现了结构相似性的有关理论,对图像的局部结构变化的感知敏感。SSIM从亮度、对比度以及结构量化图像的属性,用均值估计亮度,方差估计对比度,协方差估计结构相似程度。SSIM值的范围为0至1,越大代表图像越相似。如果两张图片完全一样时,SSIM值为1。
给定x,y两张图片,两者之间的照明度(luminance)、对比度 (contrast) 和结构 (structure)分别如下公式所示:
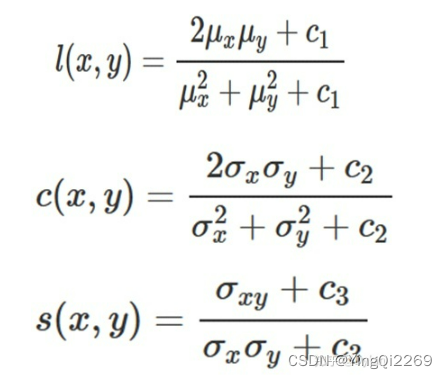
定义:
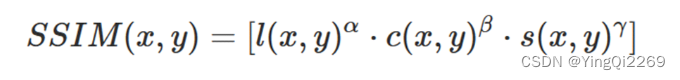
令α,β,γ均为1因此,SSIM的表达式为:
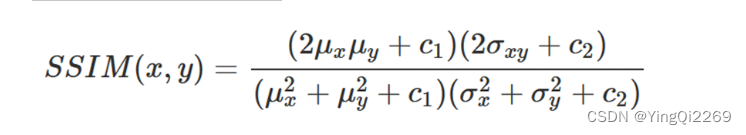

from skimage.metrics import structural_similarity as ssim
from PIL import Image
import numpy as np
def calc_ssim(img1_path, img2_path):
'''
Parameters
----------
img1_path : str
图像1的路径.
img2_path : str
图像2的路径.
Returns
-------
ssim_score : numpy.float64
结构相似性指数(structural similarity index,SSIM).
References
-------
https://scikit-image.org/docs/dev/auto_examples/transform/plot_ssim.html
'''
img1 = Image.open(img1_path).convert('L')
img2 = Image.open(img2_path).convert('L')
img2 = img2.resize(img1.size)
img1, img2 = np.array(img1), np.array(img2)
# 此处因为转换为灰度值之后的图像范围是0-255,所以data_range为255,如果转化为浮点数,且是0-1的范围,则data_range应为1
ssim_score = ssim(img1, img2, data_range=255)
return ssim_score
2、峰值信噪比(Peak Signal to Noise Ratio, PSNR)
峰值信噪比(Peak Signal to Noise Ratio, PSNR)是一种评价图像质量的度量标准。因为PSNR值具有局限性,所以它只是衡量最大值信号和背景噪音之间的图像质量参考值。PSNR的单位为dB,其值越大,图像失真越少。一般来说,PSNR高于40dB说明图像质量几乎与原图一样好;在30-40dB之间通常表示图像质量的失真损失在可接受范围内;在20-30dB之间说明图像质量比较差;PSNR低于20dB说明图像失真严重。
给定一个大小为m×n的灰度图 I 和噪声图 K,均方误差(MSE, Mean Square Error)公式如下:
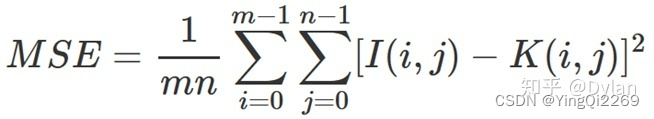
定义:
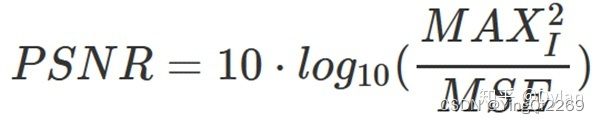

from skimage.metrics import peak_signal_noise_ratio as psnr
from PIL import Image
import numpy as np
def calc_psnr(img1_path, img2_path):
'''
Parameters
----------
img1_path : str
图像1的路径.
img2_path : str
图像2的路径.
Returns
-------
psnr_score : numpy.float64
峰值信噪比(Peak Signal to Noise Ratio, PSNR).
References
-------
https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
'''
img1 = Image.open(img1_path)
img2 = Image.open(img2_path)
img2 = img2.resize(img1.size)
img1, img2 = np.array(img1), np.array(img2)
# 此处的第一张图片为真实图像,第二张图片为测试图片
# 此处因为图像范围是0-255,所以data_range为255,如果转化为浮点数,且是0-1的范围,则data_range应为1
psnr_score = psnr(img1, img2, data_range=255)
return psnr_score
3、学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)
学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)也称为“感知损失”(perceptual loss),用于度量两张图像之间的差别。来源于CVPR2018的一篇论文《The Unreasonable Effectiveness of Deep Features as a Perceptual Metric》,该度量标准学习生成图像到Ground Truth的反向映射强制生成器学习从假图像中重构真实图像的反向映射,并优先处理它们之间的感知相似度。LPIPS 比传统方法(比如L2/PSNR, SSIM, FSIM)更符合人类的感知情况。LPIPS的值越低表示两张图像越相似,反之,则差异越大。
给定Ground Truth图像参照块x和含噪声图像失真块x0,感知相似度度量公式如下: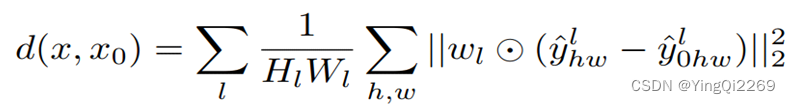

···
import lpips
class util_of_lpips():
def __init__(self, net, use_gpu=False):
'''
Parameters
----------
net: str
抽取特征的网络,['alex', 'vgg']
use_gpu: bool
是否使用GPU,默认不使用
Returns
-------
References
-------
https://github.com/richzhang/PerceptualSimilarity/blob/master/lpips_2imgs.py
'''
## Initializing the model
self.loss_fn = lpips.LPIPS(net=net)
self.use_gpu = use_gpu
if use_gpu:
self.loss_fn.cuda()
def calc_lpips(self, img1_path, img2_path):
'''
Parameters
----------
img1_path : str
图像1的路径.
img2_path : str
图像2的路径.
Returns
-------
dist01 : torch.Tensor
学习的感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS).
References
-------
https://github.com/richzhang/PerceptualSimilarity/blob/master/lpips_2imgs.py
'''
# Load images
img0 = lpips.im2tensor(lpips.load_image(img1_path)) # RGB image from [-1,1]
img1 = lpips.im2tensor(lpips.load_image(img2_path))
if self.use_gpu:
img0 = img0.cuda()
img1 = img1.cuda()
dist01 = self.loss_fn.forward(img0, img1)
return dist01
补充
1、平均精度(average precision, AP)

2、平均精度均值(mean average precision,mAP)
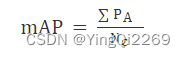
3、帧率(Frames Per Second,FPS)
检测速度一般用FPS(Frames Per Second)来衡量,其表示目标检测网络每秒能处理图片的数量,FPS值越大网络模型处理图像的速度越快。
参考:
https://zhuanlan.zhihu.com/p/309892873
https://blog.csdn.net/qq_43403025/article/details/125340891
https://blog.csdn.net/SpinMeRound/article/details/120369773
















 2052
2052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









