






【学习笔记】神经网络基础
前言
机器学习、深度学习、神经网络 这几个相似名词,可以浅浅辨析一波。
机器学习是一个广泛的概念,它包括了各种让计算机从数据中学习的技术和方法。
神经网络是机器学习中的一个特定领域,它使用类似于人脑神经元的节点和连接来模拟学习过程。
深度学习则是神经网络的一个子集,它利用多层神经网络结构来学习数据的深层表示,并在许多任务上取得了显著的性能提升。
简而言之,机器学习是一个大的领域,神经网络是机器学习的一个子集,而深度学习是神经网络的一个进阶方向。
一、神经网络架构
先粗略的了解以下神经网络的架构,网上使用最多的图基本都长这样:
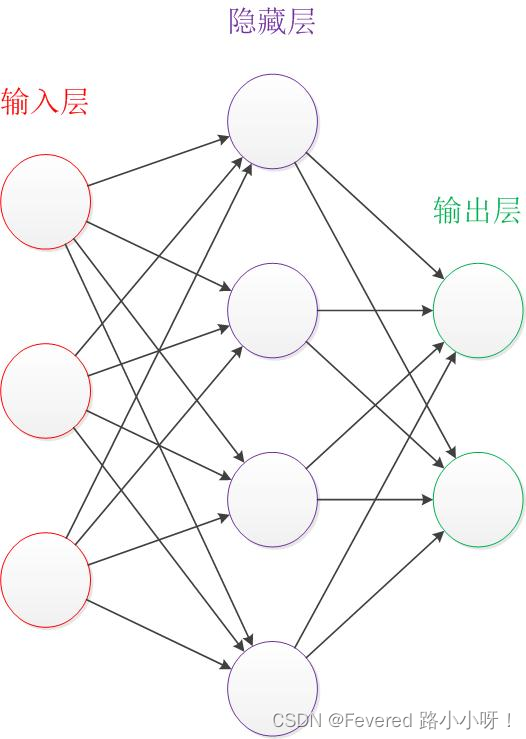
红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。其中隐藏层可以有多层,这里只是选择最简单的网络作为说明。
图中圆圈代表**“神经元**”,连线代表神经元之间的连接,其中每个连接线对应不同的权重。
前一层(输入层)根据权重计算得到输出,同时这个输出又作为后一层(中间层)的输入,同理,前一层的输出是后一层的输入,得到最终的输出。
注意,这个权重不是一直不变的,通过训练,不断调节权重参数(为什么要训练权重参数,这个与目标函数和损失函数相关)
从输入到输出这个过程是正向传播,计算完之后得到是值咱们一般喊他为预测值(计算机这个傻小子,通过权重学习计算出来的,就是计算机预测的)。既然是预测的那就与真实值存在差距,究竟差多少,一般用损失函数去衡量,损失函数越大,那就差的越多,损失函数越小,说明预测值和真实值越接近。
预测值和真实值有差距那就要修改权重,以损失函数和目标函数为引导,先计算关于输出层的梯度,然后逐层反向传递梯度,按照这个方向,层层更新连线上的权重,这个过程称之为反向传播。
简而言之,一个完成的神经网络架构:
- 输入层:接收原始数据或特征向量。
- 隐藏层:包含多个全连接层,每个全连接层中的神经元都通过激活函数与前一层中的所有神经元相连。隐藏层负责提取和学习数据的特征。
- 输出层:产生神经网络的最终输出。对于分类任务,输出层通常使用Softmax激活函数以产生概率分布;对于回归任务,输出层可能直接输出预测值。
在训练过程中,通过前向传播计算网络的输出,然后使用损失函数计算预测值与实际值之间的差异。接着使用反向传播算法根据损失函数的梯度更新网络参数,以优化网络性能。这个过程不断迭代,直到满足停止条件(如达到预设的迭代次数或损失值小于某个阈值)。
二、相关名词
以上提到了很多相关名词,那接下来一一解释一波。
1.神经元
-
联系生物学科中的神经元。
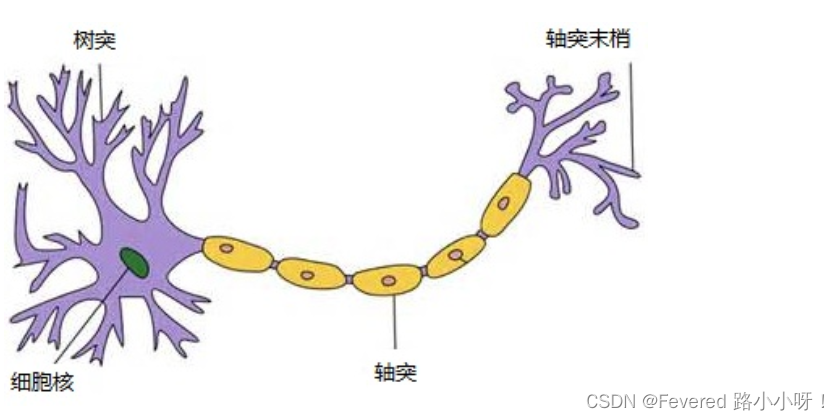
树突:接受传入信息
轴突:只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。
轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。 -
计算机神经网络中。
神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。
下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能。
注意中间的箭头线。这些线称为“连接”。每个上有一个“权值”。
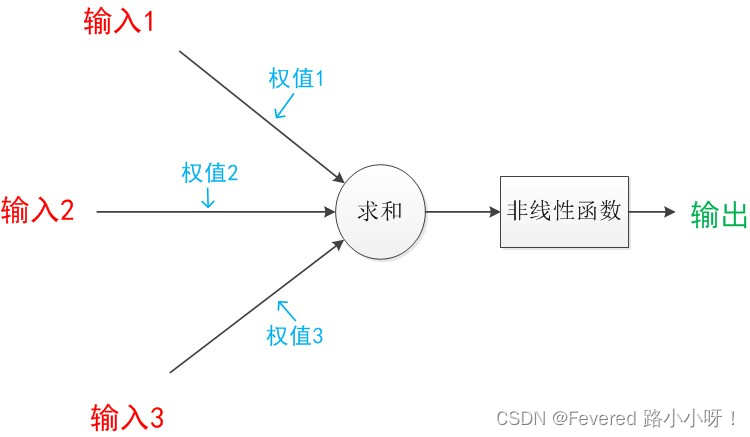
如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图。
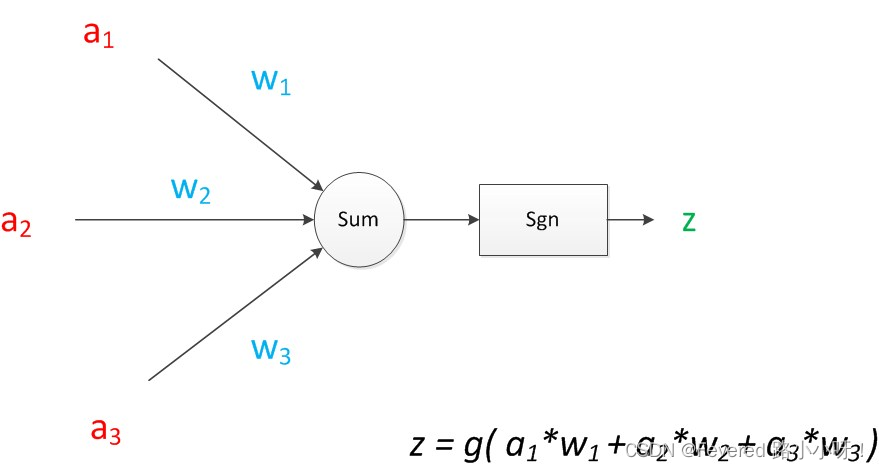
有点抽象,如果这是下图中的一环呢。
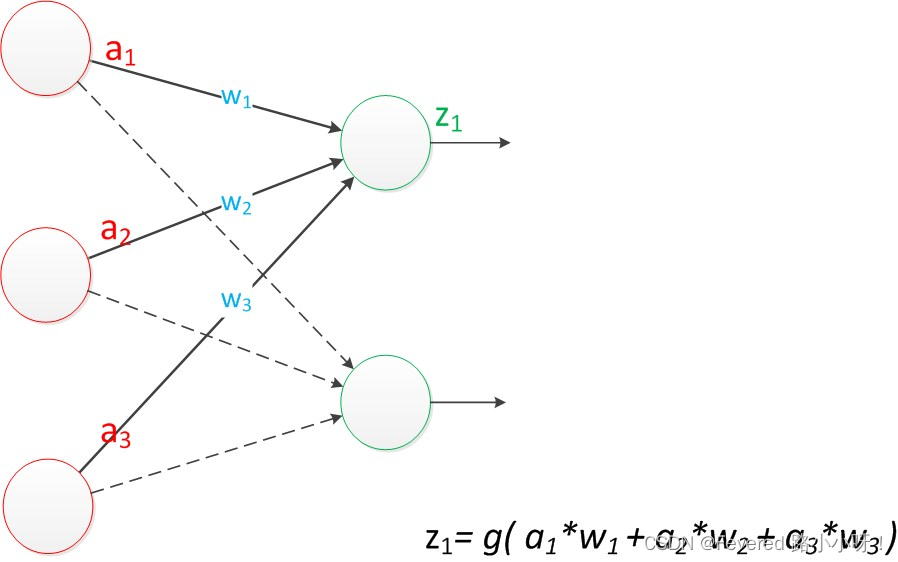
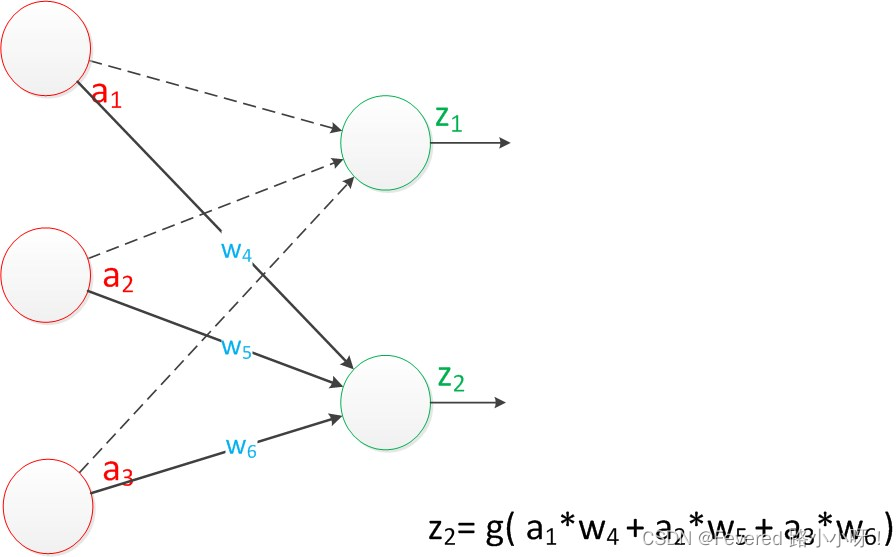
综上所述,神经元是神经网络的基本组成单元。它接收输入信号(来自其他神经元或外部数据),对这些信号进行加权求和,并应用一个激活函数来产生输出。
神经元的输出可以作为其他神经元的输入,从而构成神经网络的多层结构。
如果想看发展历程,可以移步到
神经网络——最易懂最清晰的一篇文章
2. 激活函数
首先通过上面可以知道,从输入到输出经过的是一个线性函数的计算。激活函数主要是引入非线性关系。没有激活函数的神经网络实际上只是一个线性回归模型,这限制了模型学习和表示复杂模式的能力。
这感觉就像一直线性生活寡淡无味,需要加点非同一般的元素,给计算机点刺激,这样才能更好的学习。
- 激活函数的作用
-
引入非线性
线性模型只能解决线性可分问题,而现实世界中的数据往往是非线性的。
激活函数能够给神经元引入非线性因素,使得神经网络可以学习和表示复杂的非线性函数。 -
增强模型的表达能力
通过堆叠多个非线性层,神经网络可以逼近任何复杂的连续函数。这使得神经网络能够解决各种复杂的问题,如图像识别、自然语言处理等。 -
实现特征空间的转换
激活函数可以将输入数据映射到新的特征空间,这使得神经网络可以学习输入数据中的隐藏特征或模式。这些隐藏特征可能对于解决特定任务至关重要。 -
防止梯度消失和梯度爆炸
某些激活函数(如ReLU及其变体)具有梯度饱和特性,这有助于防止梯度消失和梯度爆炸问题。这些问题在训练深度神经网络时很常见,因为它们可能导致模型无法正确更新权重。 -
使模型更容易训练
某些激活函数(如Sigmoid和Tanh)具有将输出限制在特定范围内的特性,这有助于稳定训练过程并防止权重更新过大。
- 常见的激活函数
- Sigmoid 函数
σ(x) = 1 / (1 + e^(-x))
将任意实数映射到0和1之间,常用于二分类问题的输出层。但由于其梯度在饱和区域接近于0,容易导致梯度消失问题,且其输出不是以0为中心的。
拿来直接用原则:

- ReLU函数
ReLU(x) = max(0, x)
当输入大于0时,梯度为1,不存在梯度消失问题;当输入小于等于0时,输出为0。这有助于网络实现稀疏性,并加速收敛。然而,当输入小于0时,ReLU的梯度为0,这可能导致神经元“死亡”。

- Softmax 函数
Softmax(x_i) = e^(x_i) / Σ_j e^(x_j),其中x是一个向量
Softmax函数通常用于多分类问题的输出层,它将一个向量映射为一个概率分布。
综上,激活函数作用于神经元的加权求和结果上,为神经网络引入非线性特性。
常用的激活函数包括Sigmoid、ReLU等,它们能够将神经元的输出限制在一定范围内,并增加网络的表达能力和灵活性。
详细激活函数,
常用的激活函数合集(详细版)
3 前向传播
在神经网络的前向传播过程中,输入数据从输入层开始,经过各个隐藏层(由神经元组成),逐层向前传递,直至达到输出层。每经过一个神经元,都会应用激活函数处理加权求和的结果。
pytorch中的forward例子:
首先会定一个类,pytorch中自定义的网络结构(block)都需要继承nn.Module类,这个类里面有self.forward()函数,forward中的就是前向传播干的啥活。
代码如下(示例):
class Conv1x1(nn.Module):
def __init__(self, inplanes, planes):
super(Conv1x1, self).__init__()
self.conv = nn.Conv2d(inplanes, planes, 1)
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
4. 损失函数
损失函数(或者代价函数)用于量化模型预测结果与真实结果之间的差异,从而指导模型的训练和优化。
- 损失函数功能
- 评估模型性能:损失函数提供了一个量化指标,用于评估模型在给定数据集上的性能。
- 指导模型训练:通过计算损失函数的梯度,并使用优化算法(如梯度下降)来更新模型参数,从而指导模型的训练过程。
- 常见的损失函数
-
交叉熵损失函数:
公式:CE = -Σ(y_i * log(p_i)),
其中y_i是真实标签的独热编码,p_i是模型预测的概率分布。
CE(Cross-Entropy Loss)是分类问题中最常用的损失函数之一,它基于信息熵理论来衡量预测结果与真实结果之间的差异度。交叉熵越小,表示模型的预测结果与真实结果越相似。 -
均方误差损失函数:
公式:MSE = 1/N * Σ(y_i - y_hat_i)^2
其中N是样本数量,y_i是真实值,y_hat_i是模型预测值。
MSE(Mean Squared Error)是回归问题中最常用的损失函数之一,它计算预测值与真实值之差的平方的平均值。MSE越小,表示模型的预测结果与真实结果越接近。 -
对数损失函数
公式:LogLoss = -1/N * Σ(y_i * log(p_i) + (1 - y_i) * log(1 - p_i)),
其中N是样本数量,y_i是真实标签(0或1),p_i是模型预测为正样本的概率。
LogLoss也是常用于分类问题的一种损失函数,它的计算方式是将预测值与真实值的对数差的平均值作为损失。对数损失函数越小,表示模型的预测结果越接近真实结果。
注意:公式可以不用记,随用随复制,torch包里都封装好了

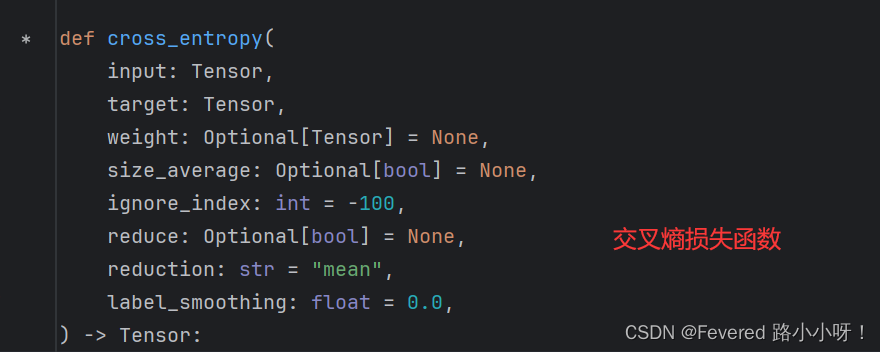
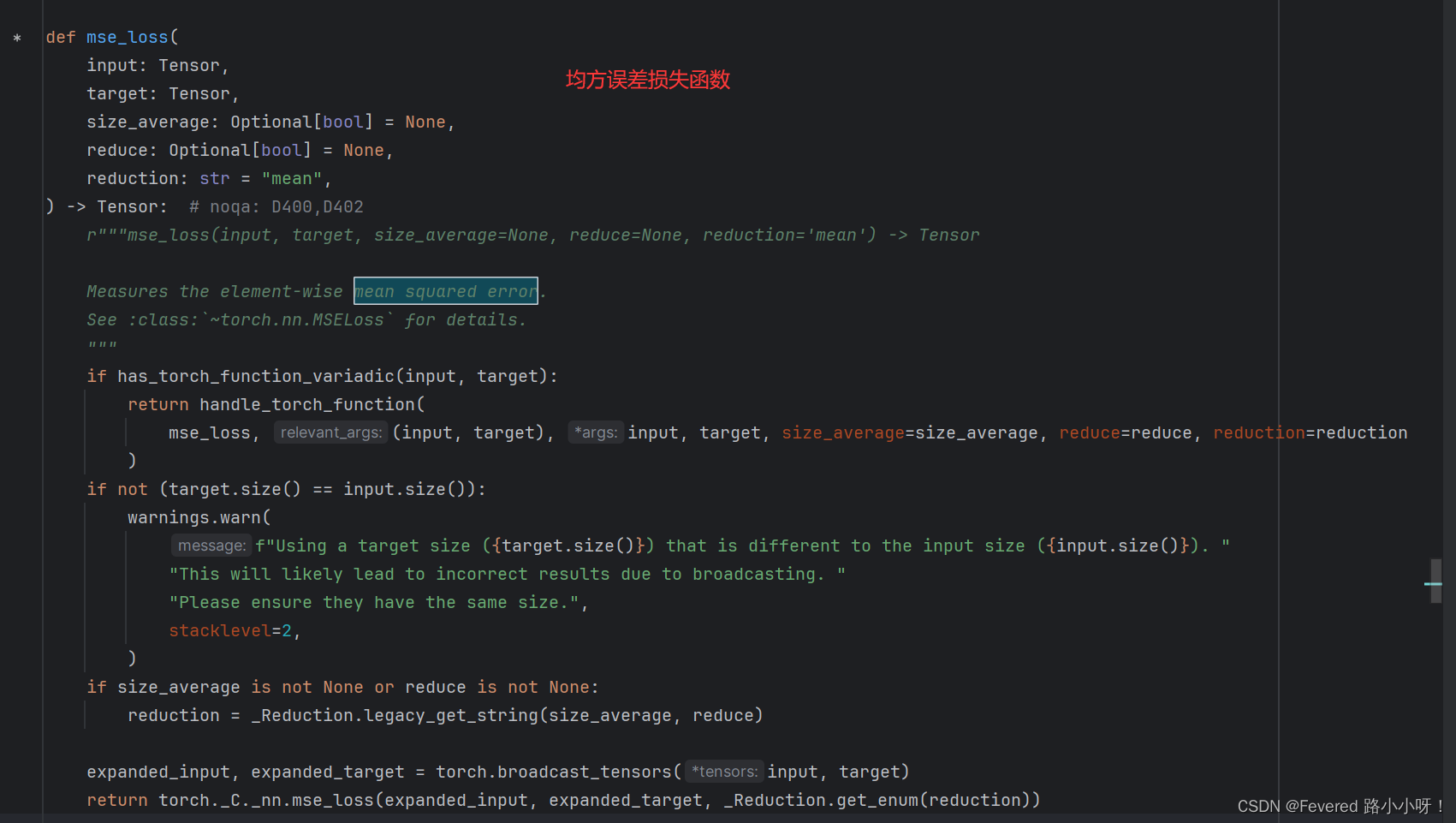
像这样直接使用:
更全的损失函数,
【深度学习】最全的十九种损失函数汇总
5 反向传播
反向传播算法是神经网络训练的关键过程。
当网络产生输出后,会与真实值或者标签进行比较,计算出损失函数的梯度。然后,这些梯度信息通过反向传播算法逐层反向传递,用于更新网络中的权重和偏置。
反向传播的关键是链式法则
举个例子
前向传播是输入通过运算得到输出的过程
一般来说不用手写bcakward,直接调用就行
pytorch中封装好的backward
def backward(
self, gradient=None, retain_graph=None, create_graph=False, inputs=None
):
if has_torch_function_unary(self):
return handle_torch_function(
Tensor.backward,
(self,),
self,
gradient=gradient,
retain_graph=retain_graph,
create_graph=create_graph,
inputs=inputs,
)
torch.autograd.backward(
self, gradient, retain_graph, create_graph, inputs=inputs
)
而且应用方法也比较简单
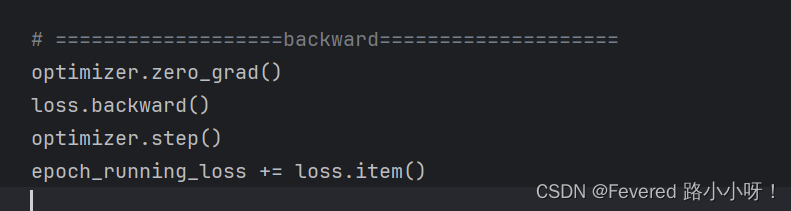
具体传播过程,
反向传播算法”过程及公式推导
三 举个例子
定义一个简单的卷积神经网络
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 假设输入图像的尺寸是28x28,有1个通道,并且我们有10个类别
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.maxpool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.maxpool(F.relu(self.conv1(x)))
x = self.dropout1(x)
x = self.maxpool(F.relu(self.conv2(x)))
x = self.dropout2(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# 实例化模型
model = SimpleCNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
损失函数在训练模型中定义好,再加上训练集就可以尝试运行了















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









