






BERT |(3)BERT模型的使用--pytorch的代码解释_郭畅小渣渣的博客-CSDN博客_bert模型的使用
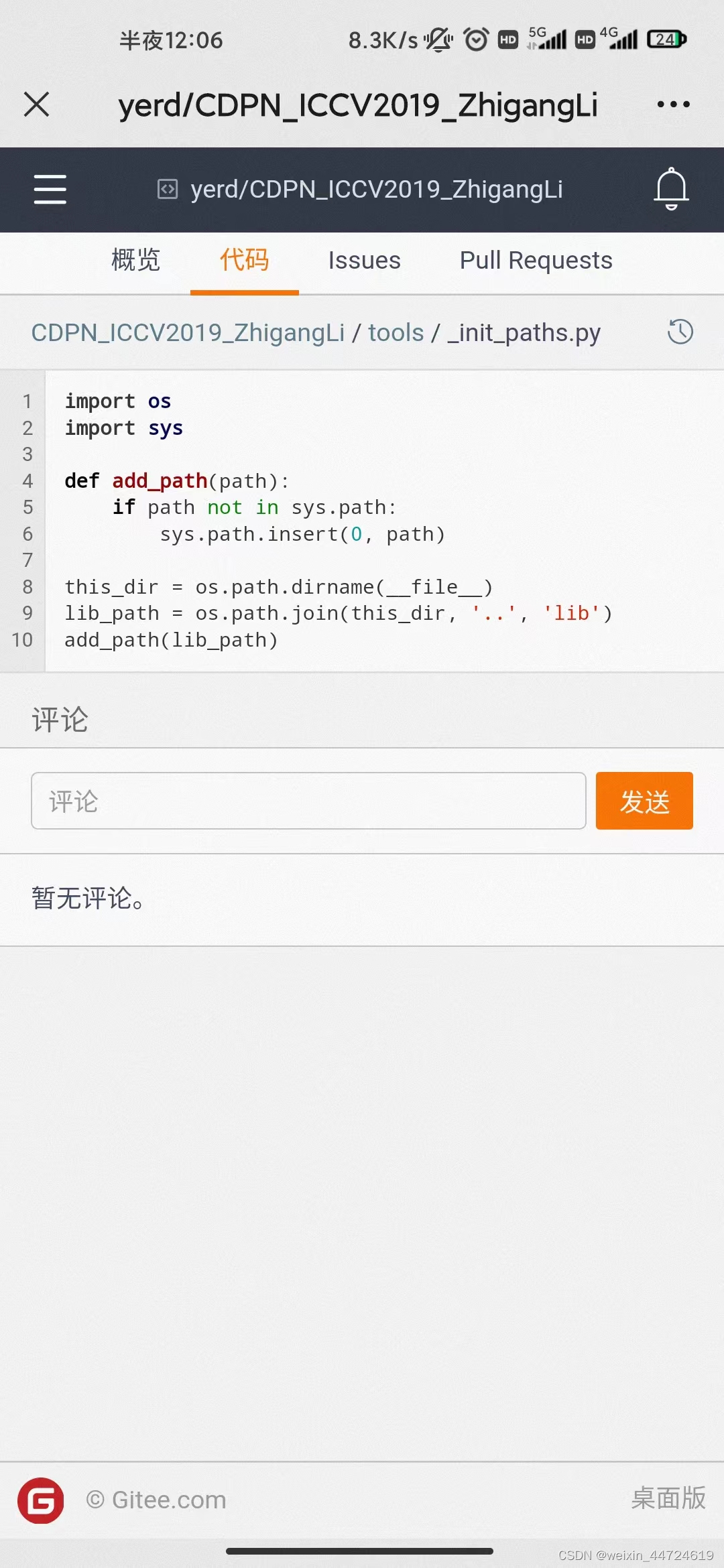
路径问题:
F1值等指标
class ClassificationReport(Callback):
def __init__(self, train_data=(), validation_data=()):
super(Callback, self).__init__()
self.X_train, self.y_train = train_data
self.train_precision_scores = []
self.train_recall_scores = []
self.train_f1_scores = []
self.X_val, self.y_val = validation_data
self.val_precision_scores = []
self.val_recall_scores = []
self.val_f1_scores = []
def on_epoch_end(self, epoch, logs={}):
train_predictions = np.round(self.model.predict(self.X_train, verbose=0))
train_precision = precision_score(self.y_train, train_predictions, average='macro')
train_recall = recall_score(self.y_train, train_predictions, average='macro')
train_f1 = f1_score(self.y_train, train_predictions, average='macro')
self.train_precision_scores.append(train_precision)
self.train_recall_scores.append(train_recall)
self.train_f1_scores.append(train_f1)
val_predictions = np.round(self.model.predict(self.X_val, verbose=0))
val_precision = precision_score(self.y_val, val_predictions, average='macro')
val_recall = recall_score(self.y_val, val_predictions, average='macro')
val_f1 = f1_score(self.y_val, val_predictions, average='macro')
self.val_precision_scores.append(val_precision)
self.val_recall_scores.append(val_recall)
self.val_f1_scores.append(val_f1)
print('\nEpoch: {} - Training Precision: {:.6} - Training Recall: {:.6} - Training F1: {:.6}'.format(epoch + 1, train_precision, train_recall, train_f1))
print('Epoch: {} - Validation Precision: {:.6} - Validation Recall: {:.6} - Validation F1: {:.6}'.format(epoch + 1, val_precision, val_recall, val_f1))
class DisasterDetector:
def __init__(self, bert_layer, max_seq_length=128, lr=0.0001, epochs=15, batch_size=32):
# BERT and Tokenization params
self.bert_layer = bert_layer
self.max_seq_length = max_seq_length
vocab_file = self.bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = self.bert_layer.resolved_object.do_lower_case.numpy()
self.tokenizer = tokenization.FullTokenizer(vocab_file, do_lower_case)
# Learning control params
self.lr = lr
self.epochs = epochs
self.batch_size = batch_size
self.models = []
self.scores = {}
def encode(self, texts):
all_tokens = []
all_masks = []
all_segments = []
for text in texts:
text = tokenize(text)
text = text[:self.max_seq_length - 2]
input_sequence = ['[CLS]'] + text + ['[SEP]']
pad_len = self.max_seq_length - len(input_sequence)
tokens = self.tokenizer.convert_tokens_to_ids(input_sequence)
tokens += [0] * pad_len
pad_masks = [1] * len(input_sequence) + [0] * pad_len
segment_ids = [0] * self.max_seq_length
all_tokens.append(tokens)
all_masks.append(pad_masks)
all_segments.append(segment_ids)
return np.array(all_tokens), np.array(all_masks), np.array(all_segments)
def build_model(self):
input_word_ids = Input(shape=(self.max_seq_length,), dtype=tf.int32, name='input_word_ids')
input_mask = Input(shape=(self.max_seq_length,), dtype=tf.int32, name='input_mask')
segment_ids = Input(shape=(self.max_seq_length,), dtype=tf.int32, name='segment_ids')
pooled_output, sequence_output = self.bert_layer([input_word_ids, input_mask, segment_ids])
clf_output = sequence_output[:, 0, :]
out = Dense(1, activation='sigmoid')(clf_output)
model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=out)
optimizer = SGD(learning_rate=self.lr, momentum=0.8)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
def train(self, X):
for fold, (trn_idx, val_idx) in enumerate(skf.split(X['text_cleaned'], X['keyword'])):
print('\nFold {}\n'.format(fold))
X_trn_encoded = self.encode(X.loc[trn_idx, 'text_cleaned'].str.lower())
y_trn = X.loc[trn_idx, 'target_relabeled']
X_val_encoded = self.encode(X.loc[val_idx, 'text_cleaned'].str.lower())
y_val = X.loc[val_idx, 'target_relabeled']
# Callbacks
metrics = ClassificationReport(train_data=(X_trn_encoded, y_trn), validation_data=(X_val_encoded, y_val))
# Model
model = self.build_model()
model.fit(X_trn_encoded, y_trn, validation_data=(X_val_encoded, y_val), callbacks=[metrics], epochs=self.epochs, batch_size=self.batch_size)
self.models.append(model)
self.scores[fold] = {
'train': {
'precision': metrics.train_precision_scores,
'recall': metrics.train_recall_scores,
'f1': metrics.train_f1_scores
},
'validation': {
'precision': metrics.val_precision_scores,
'recall': metrics.val_recall_scores,
'f1': metrics.val_f1_scores
}
}
def plot_learning_curve(self):
fig, axes = plt.subplots(nrows=K, ncols=2, figsize=(20, K * 6), dpi=100)
for i in range(K):
# Classification Report curve
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.models[i].history.history['val_accuracy'], ax=axes[i][0], label='val_accuracy')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.scores[i]['validation']['precision'], ax=axes[i][0], label='val_precision')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.scores[i]['validation']['recall'], ax=axes[i][0], label='val_recall')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.scores[i]['validation']['f1'], ax=axes[i][0], label='val_f1')
axes[i][0].legend()
axes[i][0].set_title('Fold {} Validation Classification Report'.format(i), fontsize=14)
# Loss curve
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.models[0].history.history['loss'], ax=axes[i][1], label='train_loss')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.models[0].history.history['val_loss'], ax=axes[i][1], label='val_loss')
axes[i][1].legend()
axes[i][1].set_title('Fold {} Train / Validation Loss'.format(i), fontsize=14)
for j in range(2):
axes[i][j].set_xlabel('Epoch', size=12)
axes[i][j].tick_params(axis='x', labelsize=12)
axes[i][j].tick_params(axis='y', labelsize=12)
plt.show()
def predict(self, X):
X_test_encoded = self.encode(X['text_cleaned'].str.lower())
y_pred = np.zeros((X_test_encoded[0].shape[0], 1))
for model in self.models:
y_pred += model.predict(X_test_encoded) / len(self.models)
return y_pred
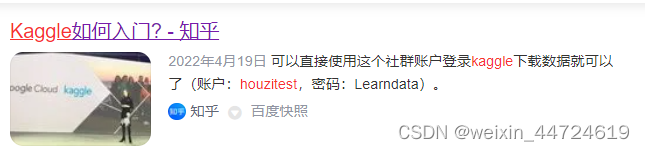
kaggle的好心人账号:















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









