








从公众号复制来的,排版可能不耐看,不要介意哈。
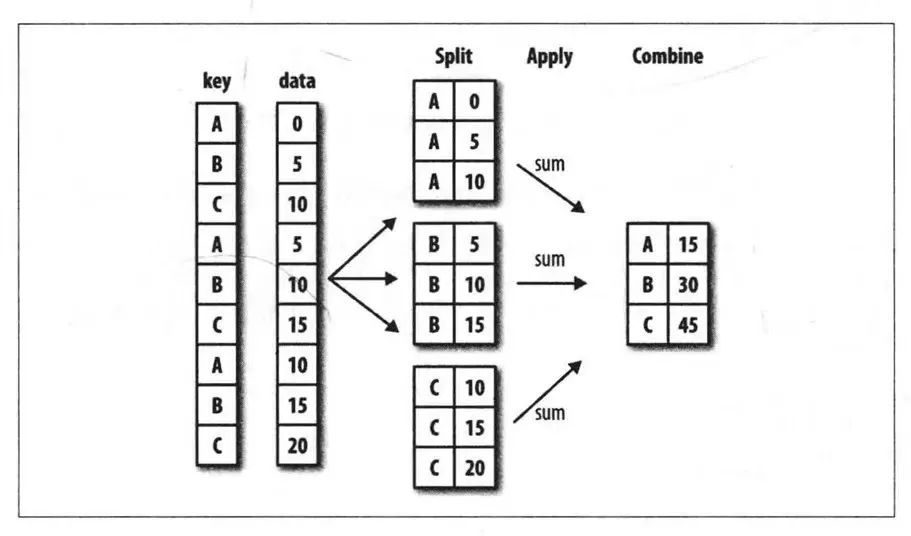
拆分-应用-联合
拆分
包含在Pandas对象中的数据可以是Series和DataFrame等数据结构,它能根据你提供的一个或多个键分离到各个组中,分离操作在特定轴上进行,行方向或者列方向的轴。
pandas提供的groupby方法实现拆分,具有如下参数:
-
keys 分组键,多个为列表
-
axis 指定轴
-
level 指定层级
-
as_index bool分组名称是否作为索引
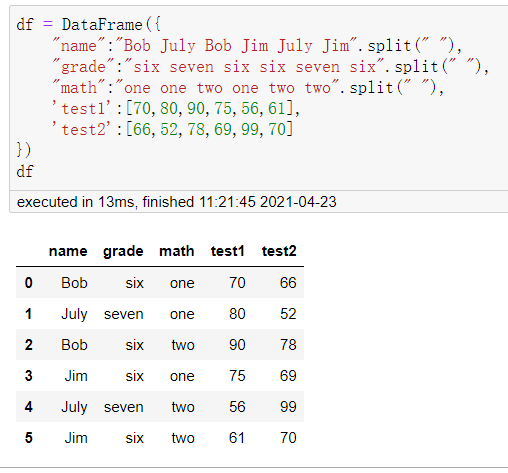
虚构一个dataFrame对象,包含姓名、年级、数学科目、测试1、测试2等列属性,可以看到姓名、年级和数学科目有相同元素,下面每一个同学(每一条记录对应一次考试)的考试记录按姓名分组。
df.groupby("name") #返回一个GruopBy对象
遍历
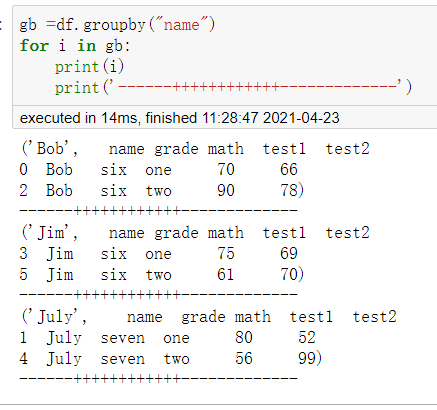
GruopBy对象可以遍历,它将返回一个元组,第一个元素是分组名称(如果分组键为多个,则为分组键集合),第二个值是分组数据。下边的分组中,姓名相同的分为一组。
数据聚合
所有根据数组产生标量值的数据转换过程。
前文曾经记录过一些pandas的基本统计函数,如下表所示。

下面对分组后的考生统计其成绩中位数,测试1和测试2下,三位同学的成绩中位数分别为:80.0、68.0、68.0以及72.0、69.5、75.5。

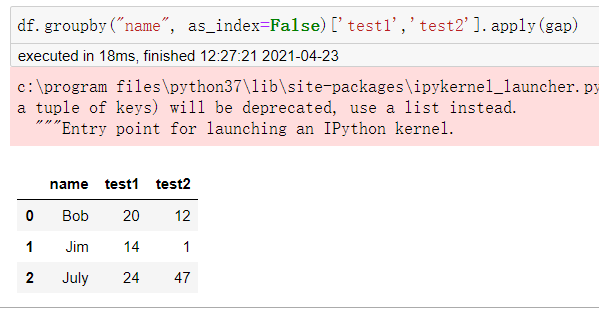
仅仅只是上述罗列的函数显然不能满足需要,可以自定义聚合函数,但是需要将自定义的函数作为参数传递给agg或者aggregate方法,下面自定义一个函数来求解每位同学两次考试的分差。

apply方法也可以实现上述功能,其参数如下:
-
func 作为参数传递的函数名
-
**args 该函数所需参数
在调用数据聚合函数过程中,到底发生了什么,它运行的原理是什么?
这里需要理解函数式编程,即函数作为一个对象,能作为参数传递也可以作为返回值(参考Python三大器中的装饰器)
-
gruopby方法将数据按键分组
-
apply和agg函数自动遍历每一列
-
遍历的每一列将作为参数传递给自定义函数,作相关运算后返回
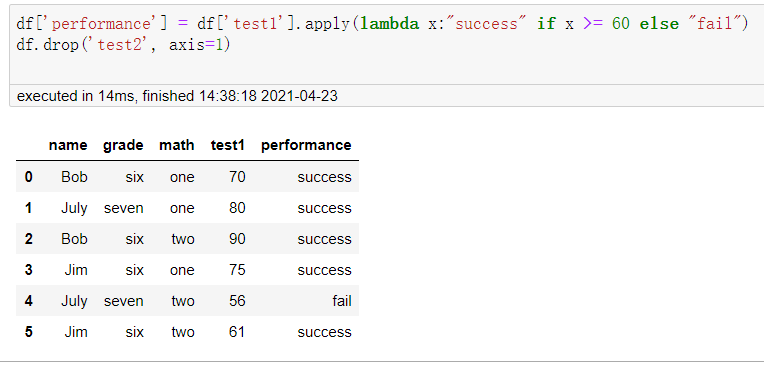
apply不仅可以遍历列,还可以遍历列元素,下述代码表示遍历测试1的每一个元素,aplly方法里面传入一个匿名函数,判断其值是否大于60,返回值将作为另一列对应位置的值,可以看到July没有通过考试。
透视表
一种在电子表格中常见的数据汇总工具,根据一个或多个键聚合成一张表的数据,将数据在矩阵中排列,一些是沿着行排列,另一些则是沿着列。
pandas的pivot_table函数可实现透视表功能,具有如下参数:
-
value 需要聚合的列名,默认全部
-
index 在表的行上进行分组的列名或者其他分组键
-
columns 在表的列上进行分组的列名或者其他分组键
-
fill_value 替换缺失值的值
-
dropna 布尔值 是否舍弃NA
-
margins 是否添加行/列小计和总计,默认True
-
aggfunc 聚合函数或函数列表,可以是groupby上下文中的任意函数,默认为“mean”
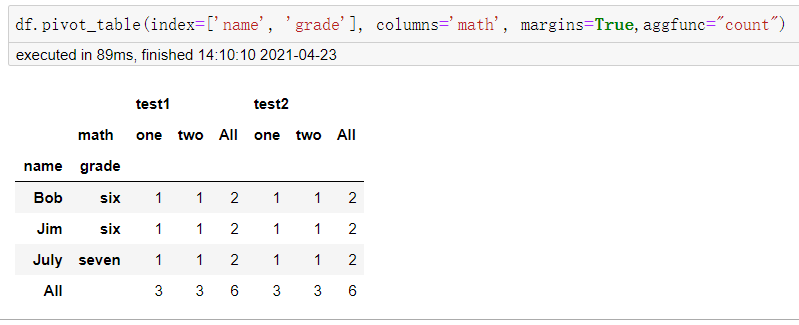
下图所示的透视表,每个学生参加测试的次数一目了然
交叉表
透视表的一种特殊情况,计算的是分组中的频率。
针对交叉表,pandas提供有crosstab方法,第一个参数为行方向的键,第二个为列方向的键。
虚构一个姓名-年级表格,然后做交叉表统计。


参考:
-
徐敬一.利用Pyhton进行数据分析[M].机械工业出版社.2018
-
小z.用实战玩转Pandas数据分析[D]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









