







介绍自然语言处理(NLP)中的文本处理—TensorFlow
前言
智能机器不仅能看到世界,还能理解我们并与我们交谈。
这一点也不夸张,其中虚拟助手互动,比如Siri、亚马逊Alexa和谷歌助手。在许多软件应用程序和网站上,我们与成千上万的聊天机器人进行互动。
自然语言处理是一个跨学科的领域。它是计算机科学、机器学习和计算语言学的一个分支,涉及赋予计算机理解文本和人类语言的能力。
NLP中常见的任务
下面是一些可以用NLP完成的常见任务。
- 文本分类
- 情绪分析
- 文本生成
- 机器翻译
- 语音识别
- 文本到语音的转换
- 光学字符识别
- 自然语言处理的应用实例
- 垃圾邮件检测
- 问题回答
- 语言到语言的翻译(机器翻译)
- 语法错误纠正(如Grammarly)
经典的NLP工具之一有NLTK。自然语言工具包或NLTK为处理文本提供了不同的功能,它是常用的。
在本实验和以后的实验中,将使用Keras和TensorFlow文本函数。
还有一套TensorFlow库用于文本处理,如TensorFlow text。
1.介绍文本处理与TensorFlow
大多数机器学习模型(包括深度学习模型)不能处理文本数据。它们必须被转换成数字。本质上,这就是文本编码的含义:它将文本转换为数字表示。
有4种主要的文本编码技术:
- 字符编码(Character encoding)
- 基于词的编码(Words based encoding)
- One hot 编码
- 词嵌入(Word embeddings)
基于字符的编码
在这种类型的编码技术中,单词中的每个字符都由唯一的数字表示。
传统的字符编码技术之一是ASCII(美国标准代码信息交换)。使用ASCII,我们几乎可以将任何字符转换为数字,这是非常标准的,但缺点之一是反图(具有不同顺序的相同字母的单词)可以具有相同的编码,这可能会损害机器学习模型。
反义词的例子包括United和United, Silent和Listen。
字符编码并没有被广泛使用,而且与其他后来的技术相比,它的效率较低。
基于词的编码
在基于单词的编码中,我们不是取单词中的单个字符,而是用数字表示所有的单个单词。
在大多数情况下,单词编码比字符编码效果好。
One hot 编码
One hot 码以编码分类特征而闻名。虽然它不是有效的,但它也可以用于文本编码,其思想是将句子中的每个单词转换为一个hot 向量,其中该单词在该特定向量中为1(hot ),而所有其他单词为0(cold)。举个例子,I love this course可以在这样的句子中取单词[I, love, this, course],然后创建一个长度为4的零向量,然后在每个单词对应的索引上取1,如下所示。
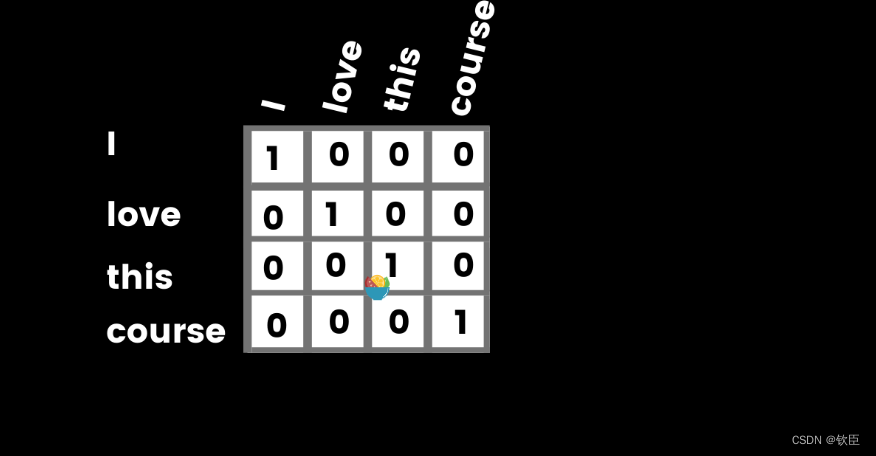
One hot 编码并不是表示文本的更好方法,因为大多数索引都是零,当您有很多单词时,它变得更加困难。它将占用大量内存空间。
到目前为止,所有编码技术(字符编码、单词编码和One hot )中,单词编码是表示文本的好方法。但是有一种更好的方法叫做词嵌入。
词嵌入是另一种表示文本的方法,其中每个词被转换成特征向量,具有相同语义的词的向量在高维空间中具有相同的方向。词嵌入是一系列自然语言处理技术,旨在将语义映射到几何空间中。通过将数字向量与字典中的每个单词相关联来完成的,这样任何两个向量之间的距离将捕获两个关联单词之间的部分语义关系。由这些向量形成的几何空间称为嵌入空间。最著名的词嵌入技术是 Word2Vec 和 GloVe。
实际上,将每个单词投影到一个连续的向量空间中,该向量空间由专用的神经网络层产生。神经网络层学习关联每个单词的向量表示,这对它的整体任务是有益的,例如,对周围单词的预测。
2.使用Keras标记器进行文本编码
Tokenizer是一个Keras文本预处理函数,它可以很容易地将原始文本转换为令牌或整数序列。
可以使用Tokenizer在字符或单词级别对文本进行编码。大多数情况下,会选择单词编码而不是字符编码,以避免反字母词(具有相同字符但顺序不同的单词,例如:united & unided, listen & silent, restful & fluster)可能引起的问题。
导入TensorFlow和Tokenizer,开始对文本进行标记。
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
在开始将文本转换为Token之前,让我们看看Tokenizer中可用的所有可能性。
Tokenizer参数
- num_words:输入文本中保留的最大字数。在你不确定的情况下,设置一个高的数字总是好的。如果您设置的数字少于文本中的单词,则不会对其余部分进行标记。
- filters(过滤器):默认情况下,所有标点和标签将被删除。如果你想改变这个,你可以提供你想要保留的标点符号。
- lower:为真或为假。默认情况下,它为True,这意味着所有文本都将转换为小写。
- Split:分隔字的分隔符。默认的分隔符是一个空格(" ")。如果在你的文本中,单词被其他东西分割了,一定要在那里提到。
- char_level:如果为True,每个字符都将被视为标记。默认为False。
- oov_token:这表示要添加到word_index中的内容,以替换输入文本中不可用的单词。
最后要注意的是,Token从1开始。这里使用一个简单的句子来探索Keras的Tokenizer。稍后,将在真实世界的数据集上练习这些技能。
# 例句
sentences = ['TensorFlow is a Machine Learning framework',
'Keras is a well designed deep learning API',
'TensorFlow and Keras make a great machine learning ecosystem'
]
开始Tokenizer,假设单词的数量是1000。
通过将char_level设置为true,将把每个字符转换为一个Token。
tokenizer = Tokenizer(num_words=1000, char_level=True)
# 对句子进行Tokenizer拟合
tokenizer.fit_on_texts(sentences)
#获取字符索引,将每个字符映射到其Token的字典。
char_index = tokenizer.word_index
print(char_index)

在现实数据集中,不必这样做。这里再将char_level设置为False。
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)

可以看到,比起字符符号,单词符号更有意义。
此外,还可以得到每个单词在句子/文档中出现的次数。
word_counts = tokenizer.word_counts
word_counts

3.将文本转换为符号序列
还可以更进一步:将句子转换为符号序列。这很重要,因为它保留了句子中单词的顺序。
from tensorflow.keras.preprocessing.text import Tokenizer
#定义新的句子
sentences = ['TensorFlow is a Machine Learning framework',
'Keras is a well designed deep learning API',
'TensorFlow and Keras make a great machine learning ecosystem!',
'TensorFlow is built on top of Keras',
'TensorFlow revolves around tensors!'
]
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
# 将文本转换为序列
text_sequences = tokenizer.texts_to_sequences(sentences)
print(f'Words with tokens: {word_index}')
print(f'Sequence of tokens: {text_sequences}')
 从上面的words-tokens字典和序列列表中,序列中的第一个列表是[1,2,3,6,4,7]。它应该代表输入句子中的第一个句子(TensorFlow是一个机器学习框架)。可以使用单词index来验证这一点。
从上面的words-tokens字典和序列列表中,序列中的第一个列表是[1,2,3,6,4,7]。它应该代表输入句子中的第一个句子(TensorFlow是一个机器学习框架)。可以使用单词index来验证这一点。
最好使用oov_token创建初始化tokenizer ,以便标记这些新单词,并用oov token替换在文本排序过程中超出词汇表的单词。
tokenizer = Tokenizer(num_words=1000, oov_token='Word Out of Vocab')
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
#oov_token接受words-token字典中的第一个索引。
text_sequences = tokenizer.texts_to_sequences(sentences)
print(f'Words with tokens: {word_index}')
print(f'Sequence of tokens: {text_sequences}')

new_sentences = ['I like TensorFlow', # like is a new word
'Keras is a superb deep learning API' # superb is a new word
]
sequences_on_newtexts = tokenizer.texts_to_sequences(new_sentences)
print(f'Sequence of tokens: {sequences_on_newtexts}')
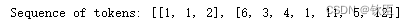
查看上面的序列,可以看到oov_token(在word字典中索引为1)已经替换了所有新单词(I, like, superb)。
4.填充序列使其具有相同的长度
几乎所有的机器学习模型都要求输入样本具有相同的长度/大小。举个例子:在使用卷积神经网络的计算机视觉中,总是需要调整所有图像的大小以使其具有相同的大小。
这不是一个可选的步骤。下面是在Keras中填充序列时可用的不同选项。
tf.keras.preprocessing.sequence.pad_sequences (maxlen=None, dtype=“int32”, padding=“pre”, truncating=“pre”, value=0.0)
关于参数的说明:
- sequence:这是一个整数形式的序列列表(标记文本)。
- maxlen:所有序列的最大长度。如果没有提供,序列将被填充到所提供序列中最长序列的长度。
- padding:‘pre’或’ post '。选择“pre”在序列之前填充,或选择“post”在序列之后填充。缺省情况下,序列是预先填充的。
- truncating:“pre”或“post”。从大于maxlen的序列中删除开头或结尾的值。
- value:用作填充值的浮点数或字符串。默认情况下,序列用0填充。
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Padding text_sequences
padded_sequences = pad_sequences(text_sequences, maxlen=10)
print('WORD INDEX')
print(f'Words with tokens: {word_index}')
print("---------")
print('SEQUENCES')
print(f'Words with tokens: {text_sequences}')
print("---------")
print('PADDED SEQUENCES')
print(f'Sequence of tokens: {padded_sequences}')

5.使用TextVectorization(文本矢量化)层对文本进行预处理
TextVectorization层是一个Keras预处理,用于将字符串转换为tokens列表。
这一层将做3件主要的事情:
- 标准化文本样本(删除标点符号并降低文本大小写)
- 将一个句子分割成单独的单词,并将它们转换为符号
- 并将这些符号转换成可以输入模型的数字。
简而言之,TextVectorization从文本中删除标点符号并降低大小写(标准化),对句子进行标记,并对标记进行矢量化。
tf.keras.layers.experimental.preprocessing.TextVectorization(
max_tokens=None,
standardize=“lower_and_strip_punctuation”,
split=“whitespace”,
ngrams=None,
output_mode=“int”,
output_sequence_length=None,
pad_to_max_tokens=False,
vocabulary=None
)
- max_tokens:最大词汇表大小。词汇是一个句子中单个或唯一单词的列表。
- standardize:表示将应用于输入数据的标准化细节。默认情况下,它是’lower_and_strip_punctuation’,意思是降低大小写并删除标点符号。
- split:表示在分割输入文本时将考虑的内容。默认情况下,它是’ whitespace ',但如果你的文本不同,你可以在这里提到它。
- output_mode:指定层的输出类型。默认情况下,它是’int’,这意味着层输出将是整数索引。
- vocabulary:字符串的数组或(list, set, tuple)或文本文件的路径。
import tensorflow as tf
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
sentences = [
'TensorFlow is a deep learning library!',
'Is TensorFlow powered by Keras API?']
max_features = 1000
text_vect_layer = tf.keras.layers.TextVectorization(
max_tokens=max_features,
output_mode='int',
output_sequence_length=10)
text_vect_layer.adapt(sentences)
sample_sentence = 'Tensorflow is a machine learning framework!'
vectorized_sentence = text_vect_layer([sample_sentence])
print(f'Orginal sentence: \n {sample_sentence}')
print(f'Vectorized sentence: \n {vectorized_sentence}')

这次学习可以使你有一个接受输入文本的模型,对其进行转换,并对其建模…
6.总结
NLP是一个处理文本的机器学习领域。
本次学习了如何将文本表示为数字,因为大多数机器学习模型的输入数据必须是向量或数字数组,看到了如何对单词进行标记、将标记转换为序列以及添加序列,还了解到如何将文本转换为矢量或数字与文本矢量化层。
在下一个实验中,将学习一种有用的文本表示技术——词嵌入。














 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









