







 本文介绍了如何使用Python和Scikit-learn库中的SVM对鸢尾花数据集进行分类,包括数据预处理、训练线性SVC和非线性SVC模型,以及评估模型性能。强调了在实际应用中避免过度调整超参数以防止过拟合的重要性。
本文介绍了如何使用Python和Scikit-learn库中的SVM对鸢尾花数据集进行分类,包括数据预处理、训练线性SVC和非线性SVC模型,以及评估模型性能。强调了在实际应用中避免过度调整超参数以防止过拟合的重要性。
机器学习-支持向量机SVM -分类
前言
本实验将使用鸢尾花数据集。该数据集包含3个物种。这些物种就是我们所指的类别/类。特征是萼片长度、萼片宽度、花瓣长度、花瓣宽度。所有特征均以厘米(cm)为单位测量。每个物种有50个样本,所以所有物种有150个样本。



1.导入模块
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn
import matplotlib.pyplot as plt
%matplotlib inline
2.加载数据
我们将从Sklearn数据集中获取iris数据。将as_frame参数设置为True将返回数据作为Pandas Dataframe。
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True, as_frame=True)
#划分数据集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2,random_state=20)
#查看X_train的直方图效果
X_train.hist(bins=30, figsize=(20,15))
plt.show()
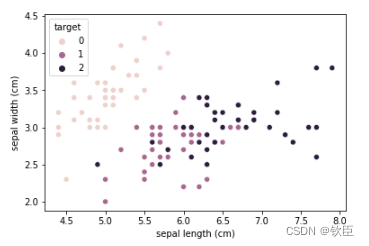
绘制特征的散点图
sns.scatterplot(data=X_train, x='sepal length (cm)', y='sepal width (cm)', hue=y_train)
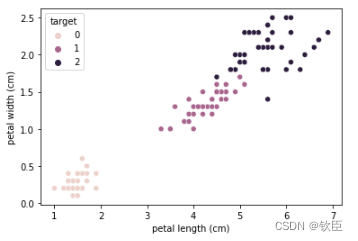
sns.scatterplot(data=X_train, x='petal length (cm)', y='petal width (cm)', hue=y_train)
这些特征已经有了很小的值,再把它们缩放到0到1之间。支持向量机可以很好地处理缩放值。这里将建立一个Pipeline来处理它。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
scale_pipe = Pipeline([ ('scaler', MinMaxScaler())])
X_train_scaled = scale_pipe.fit_transform(X_train)
3.训练支持向量分类器
我们将训练两个分类器:线性SVC和SVC,我们可以使用不同的核。SVM支持“线性”、“多项式”、“sigmoid”和“rbf”核。
from sklearn.svm import LinearSVC, SVC
#线性svc
lin_svc = LinearSVC()
lin_svc.fit(X_train_scaled, y_train)
#非线性svc
poly_svc = SVC(kernel='poly')
poly_svc.fit(X_train_scaled, y_train)
4.评价支持向量分类器
先来检查一下训练的准确性。对于这一步,只努力寻找模型来进一步改进,所以我们还没有触及测试集。
from sklearn.metrics import accuracy_score
lin_pred = lin_svc.predict(X_train_scaled)
accuracy_score(y_train, lin_pred) #0.9833333333333333
还可以显示具有多项式核的SVC上的混淆矩阵和分类报告。分类报告超越了准确性,包括召回率、精确度和F1分数。
from sklearn.metrics import confusion_matrix, classification_report
confusion_matrix(y_train, poly_pred)
print(classification_report(y_train, poly_pred))
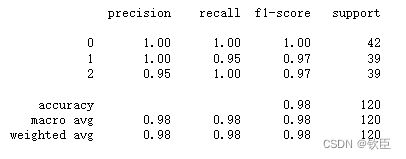
这里不需要调整任何超参数,结果就相当好了。但在现实生活中,模型一开始不太可能工作得很好。还需要调整超参数。
有两种常用的超参数搜索技术。它们是随机搜索和网格搜索。
5.改进的支持向量分类器(这里是反例,实际上不用再改进)
目的是告诉大家,不要一味的追求模型高的评估分数,否则会导致过拟合。
from sklearn.model_selection import GridSearchCV
params_grid = {'C':[0.001,10,100,1000],
'gamma':[1,0.1,0.01,0.001],
'degree':[2,3,4,5],
'coef0':[0,1,2,4]
}
grid_search = GridSearchCV(SVC('poly'), params_grid, verbose=2)
grid_search.fit(X_train_scaled, y_train)
#在上面的网格搜索定义中,如果已经将参数re_fit设置为True,则不必运行紧接的这一句
poly_best = grid_search.best_estimator_.fit(X_train_scaled, y_train)
grid_pred = poly_best.predict(X_train_scaled)
accuracy_score(y_train, grid_pred) #0.9833333333333333
print(classification_report(y_train, grid_pred))
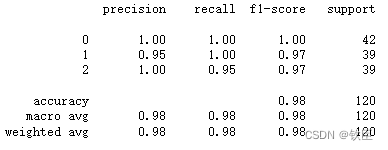
这里可以看出该实验已经不再需要调整超参数。如果在超参数搜索之前,评估第一个模型就已经取得了良好的效果,就不必再改进模型,否则会导致过拟合的,导致模型不能很好地泛化新数据。
最后做出测试集评估:
test_pred_poly = poly_svc.predict(test_scaled)
accuracy_score(y_test, test_pred_poly) #0.9666666666666667
总结
这是关于使用支持向量机进行分类任务的实验的结束。SVM是一个健壮的算法,因为它支持不同的核。这些核使得它既适用于线性问题也适用于非线性问题。在现实世界中,许多数据集都不是线性的。所以当你不能用线性模型得到好的结果时,试试用多项式核的SVM。

















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









