






 本文详细介绍如何利用Python爬虫技术从StockSnap.io网站抓取免费高质量图片,包括获取图片URL、解析JSON数据及下载图片至本地文件夹的完整过程。
本文详细介绍如何利用Python爬虫技术从StockSnap.io网站抓取免费高质量图片,包括获取图片URL、解析JSON数据及下载图片至本地文件夹的完整过程。
一.寻求网址:网站:https://stocksnap.io/
这个网站质量还是杠杠的!还是免费的
二. url的获取(假如你会查看请求,请忽略该部分内容)
分两步:
1.0 获取图片的url
2.0 获取 (存储图片url的) json的url
1.1来到网页上:把鼠标放在图片下,右键最后一个选项检查(inspect)
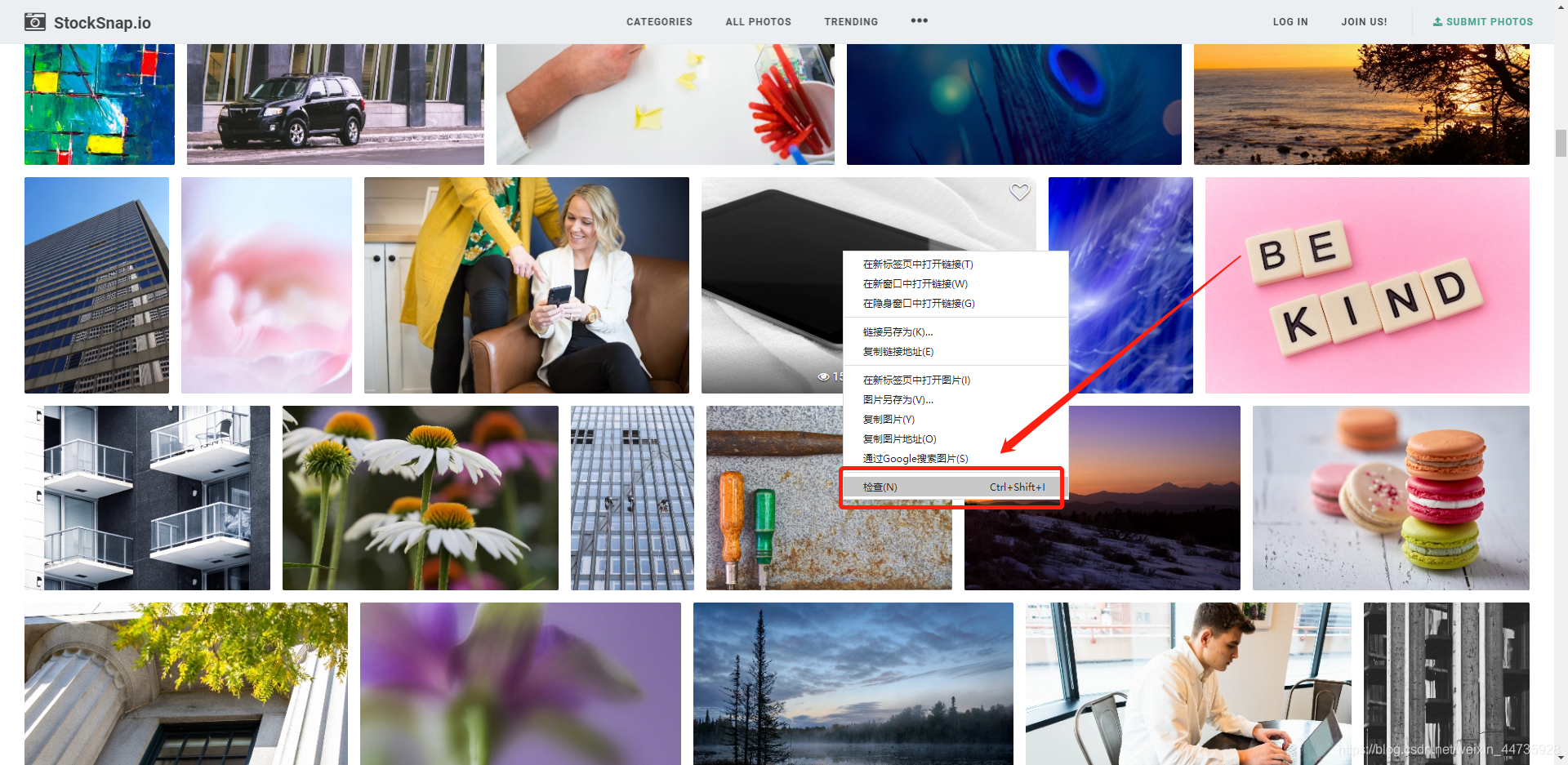
1.2 找到图片的url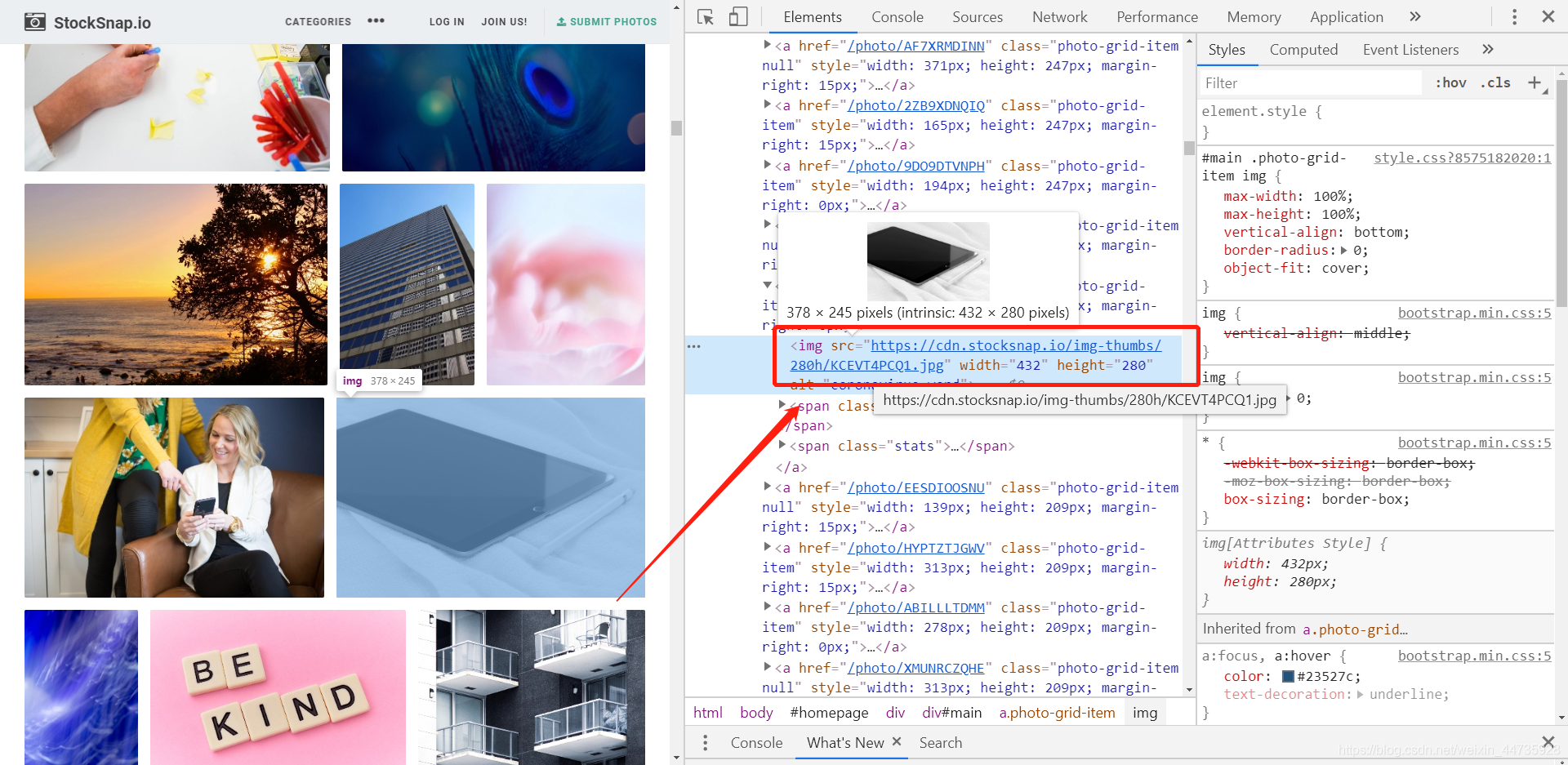
1.3 复制粘贴url,链接到图片的地址(出现图片,证明第一步成功了)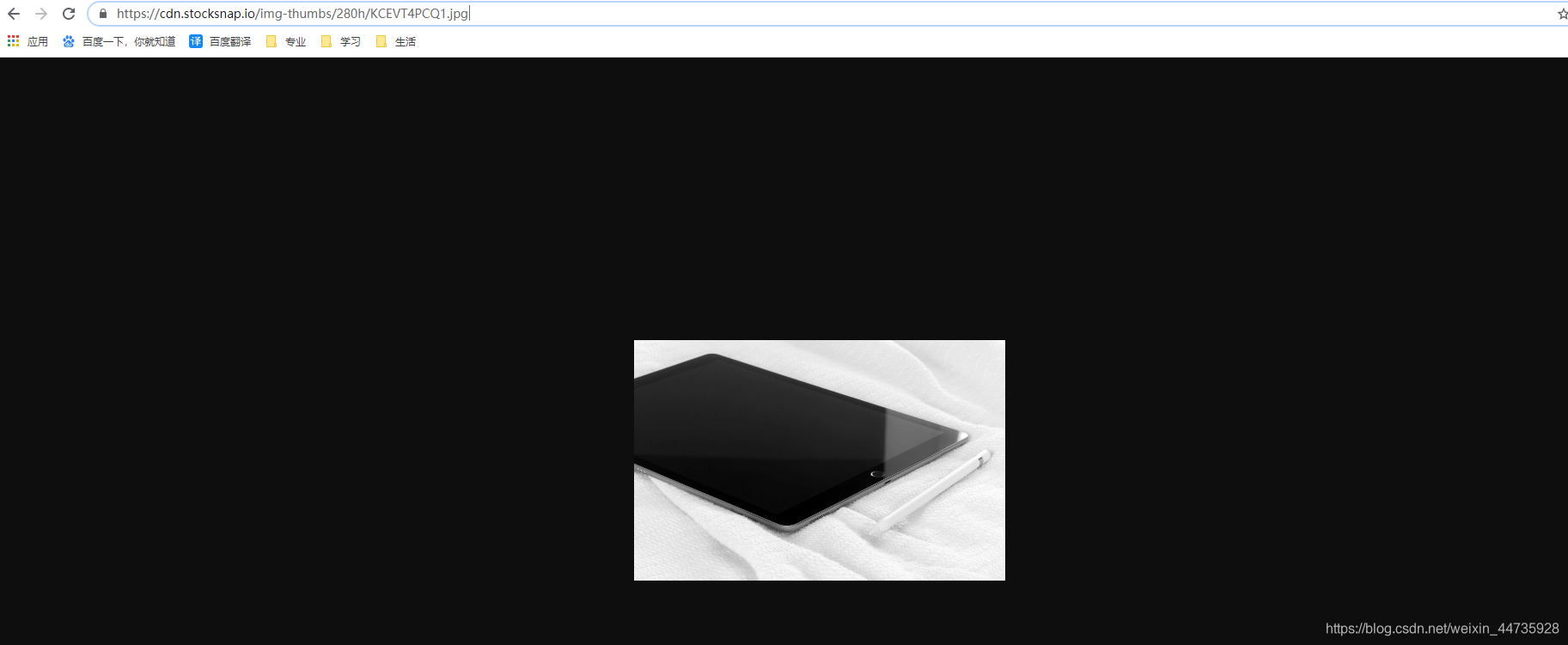
2.1 (右键点击:检查)来到这个请求页面,
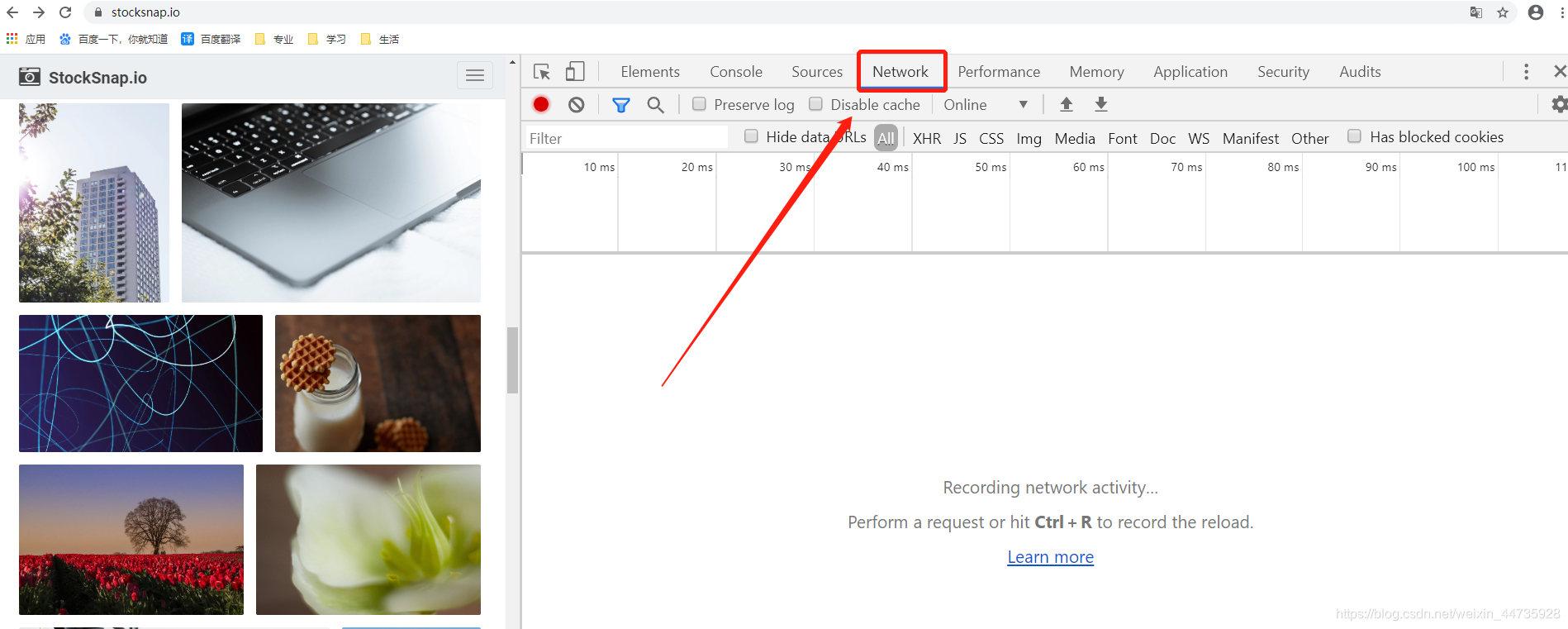
2.2 按下F5或(箭头指示:刷新图标)
2.3就可以看到各式各样的请求
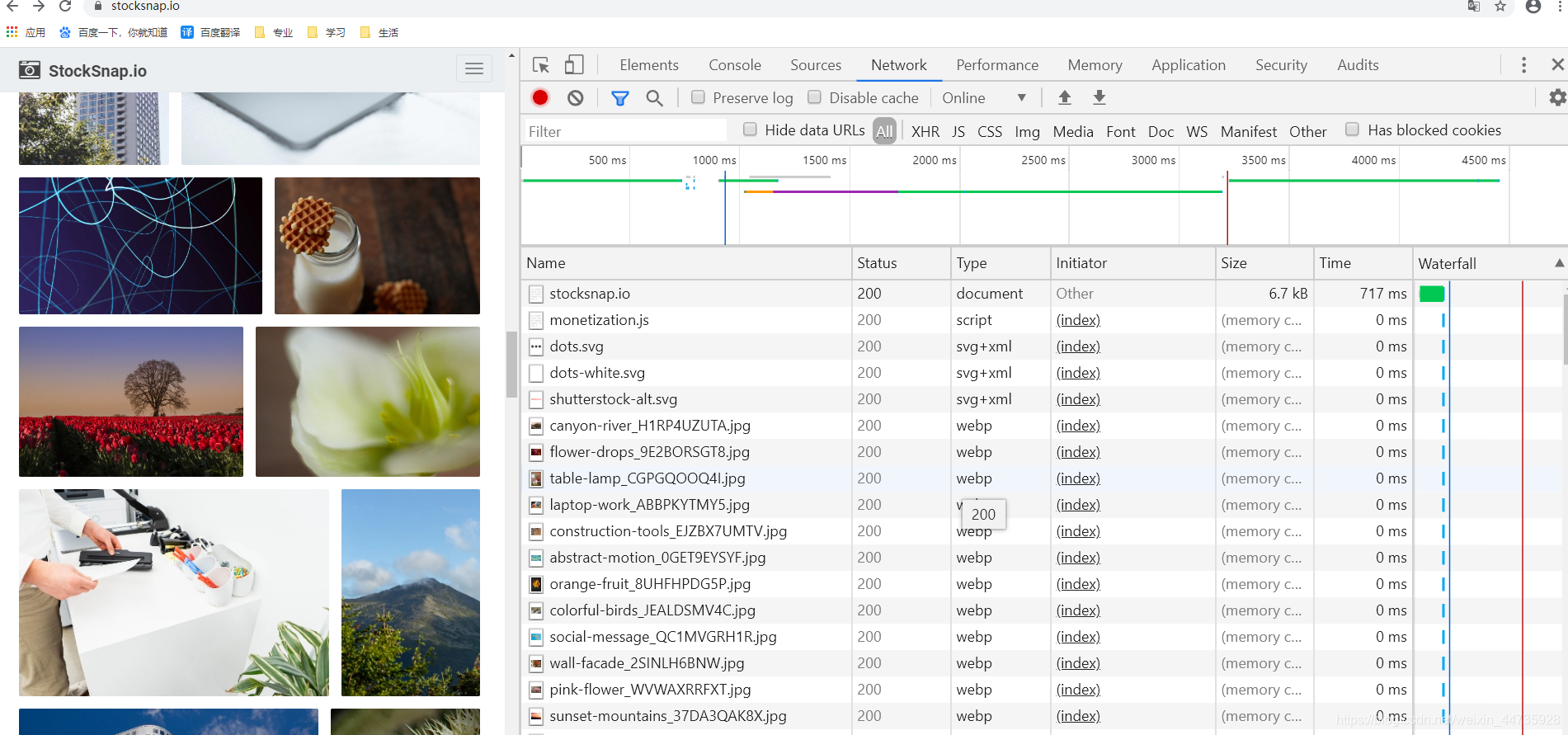
2.4查看Ajax 内容!!!由于该网站使用是Ajax存储json,所以我们需要看Ajax部分的请求(tips:当你不断往下拉,页面不断的出现新内容,一直拉不到页面的尽头,这个就是应用Ajax)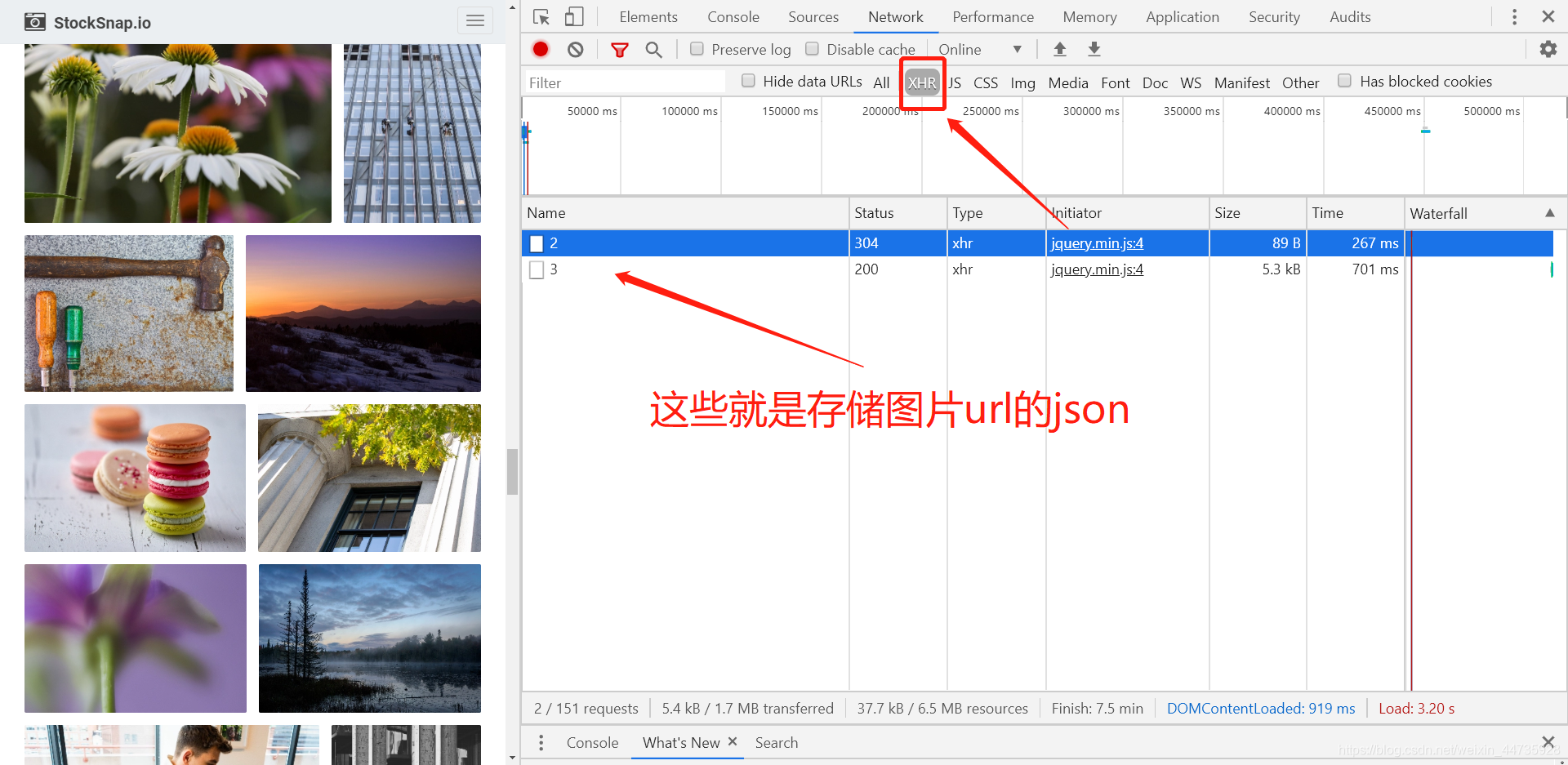
2.5 双击json文件,就会跳到json的url上

2.6出现,成功!!
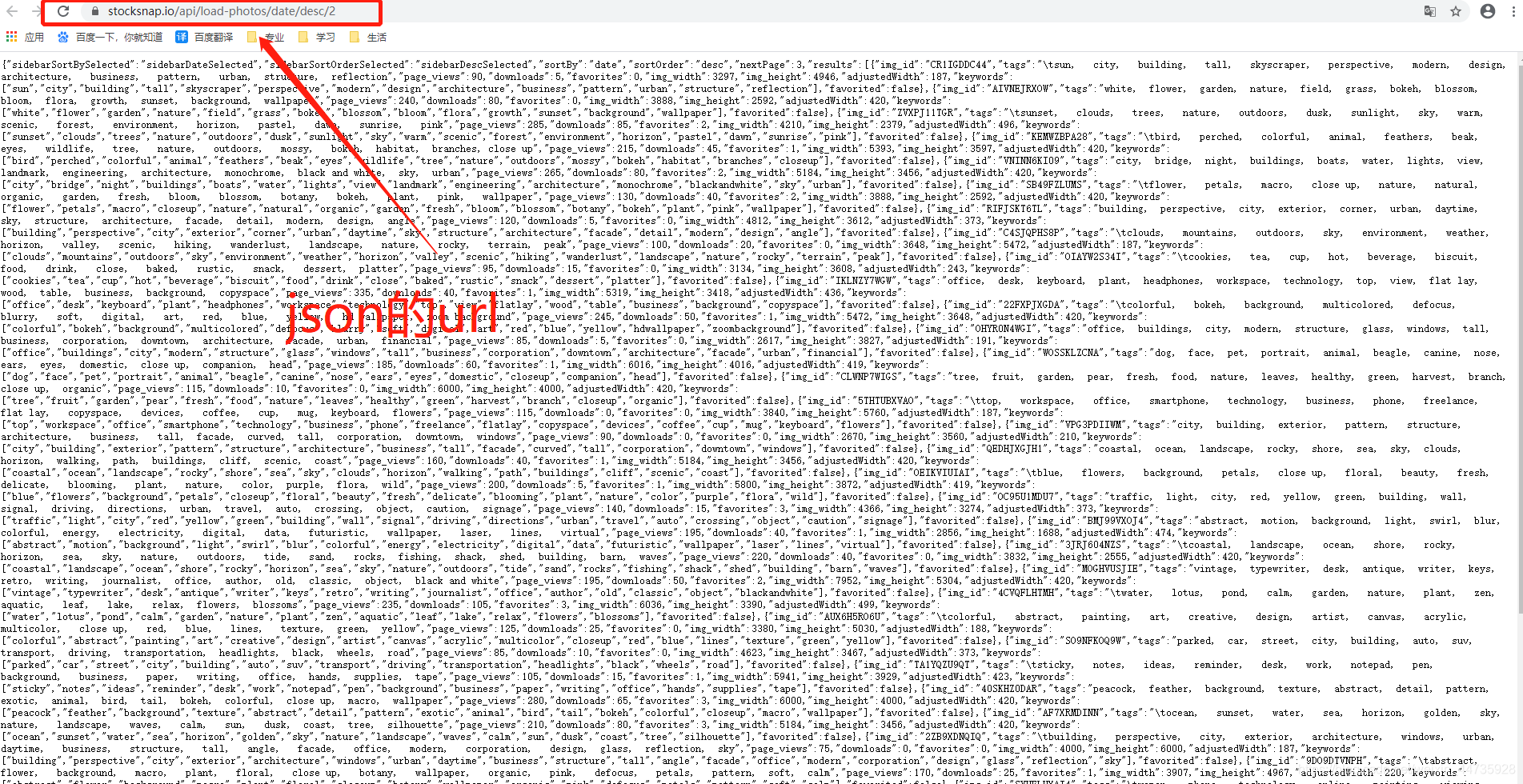
三.json 的 url 分析
1.0 分析并获取url
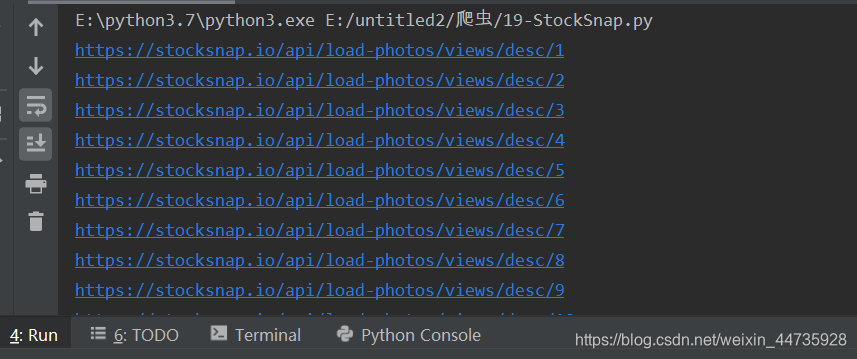
第二页的url 是:https://stocksnap.io/api/load-photos/date/desc/2
第三页的url 是:https://stocksnap.io/api/load-photos/date/desc/3
第四页的url 是:https://stocksnap.io/api/load-photos/date/desc/4


那么可以推断url的变化是"后面的页数"
调试代码
def get_url_list(url):
# 设置页数,如果需要下载更多的图片,只需要加大页数即可!!
page = 10
for i in range(page):
detailed_url = url.format(i + 1)
print(detailed_url)
if __name__ == '__main__':
# 由于有多页 ,所以用format函数,循环页数
# 把变化的页数用 {} 括起来
url = 'https://stocksnap.io/api/load-photos/views/desc/{}'
get_url_list(url)
输出结果(现在已经得到了json的url)
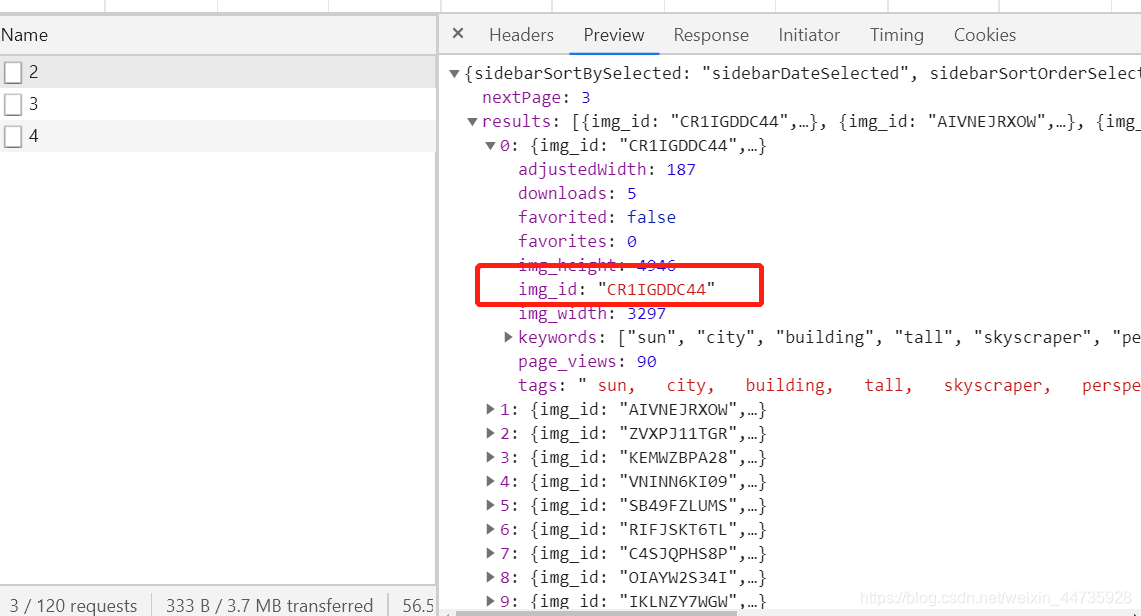
1.1 从获取的json文件 中取出图片的url
图片的url的变化只有id部分
调试代码
import requests
import json
import os
def get_url_list(url):
# 网站地址url = 'https://stocksnap.io/'
page = 10
for i in range(page):
detailed_url = url.format(i + 1)
# 这里把print 改为调用下一个方法,这样就会把获得url传过去
get_image_url_list(detailed_url)
def get_image_url_list(url):
# 通过json的模块获取具体的信息
# 通过调用 url 响应返回文本
response = requests.get(url)
# 把响应的文本加载成json 文件
res_dict = json.loads(response.text)
# 根据键值对 取出 图片的url
results = res_dict['results']
for result in results:
img_id = result['img_id']
# 这里需要拼凑 url
src = 'https://cdn.stocksnap.io/img-thumbs/280h/'
img_url = src + img_id + '.jpg'
print(img_url)
if __name__ == '__main__':
# Ajax_url = 'https://stocksnap.io/api/search-photos/nature/relevance/desc/1'
# 由于有多页的Ajax ,所以用format函数,循环页数
url = 'https://stocksnap.io/api/load-photos/views/desc/{}'
get_url_list(url)
输出结果(获取所有的图片的url)
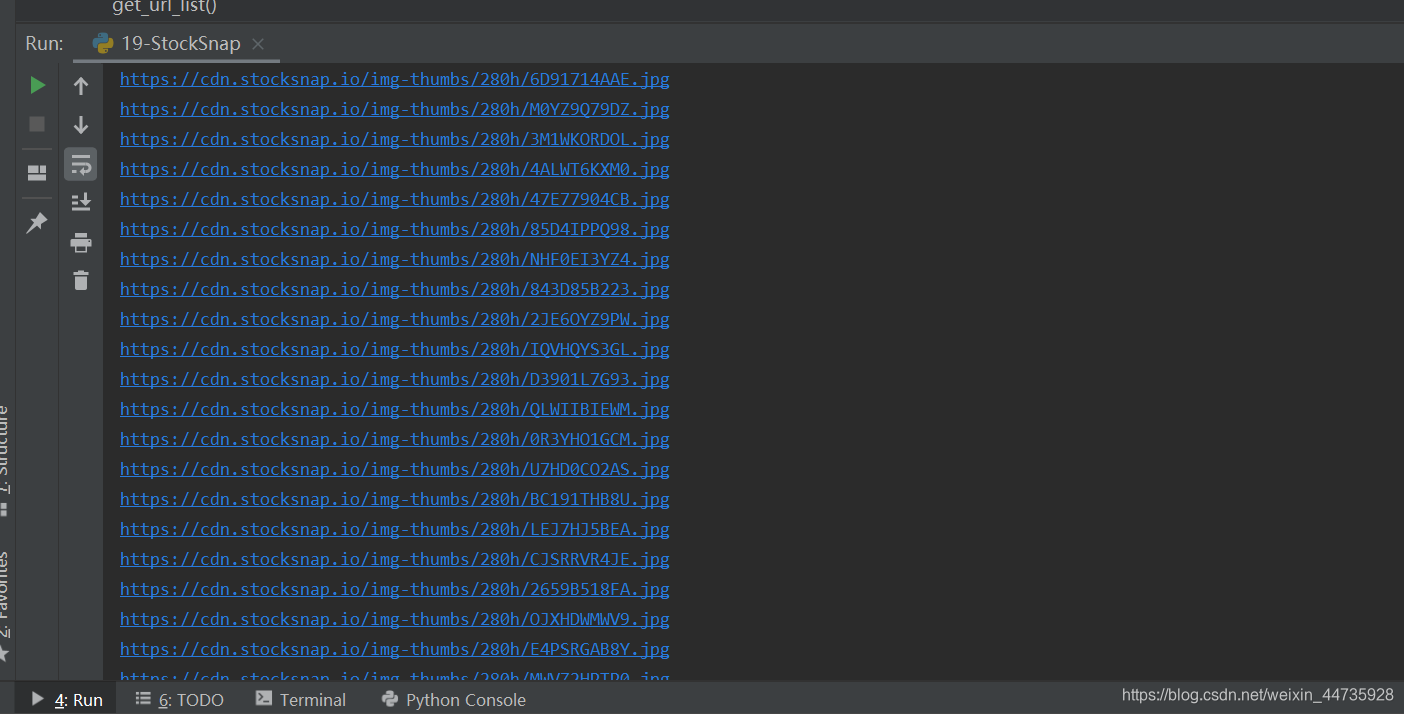
四.通过图片的url 下载图片到文件夹中
调试代码
import requests
import json
import os
def download_image(url):
print('正在下载...' + url)
# 命名一个文件夹
downloaddir = 'StockSnap'
# 若 该文件夹不存在 ,则创建文件夹
if not os.path.exists(downloaddir):
os.mkdir(downloaddir)
# 添加头部信息,
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url, headers=headers)
# 文件名 + / : 就代表文件放在该文件夹下 ,截取后面的id作为图片名
filename = downloaddir + '/' + url.split('/')[-1] # 截取/后面的文件名
# 最后,写入
with open(filename, 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
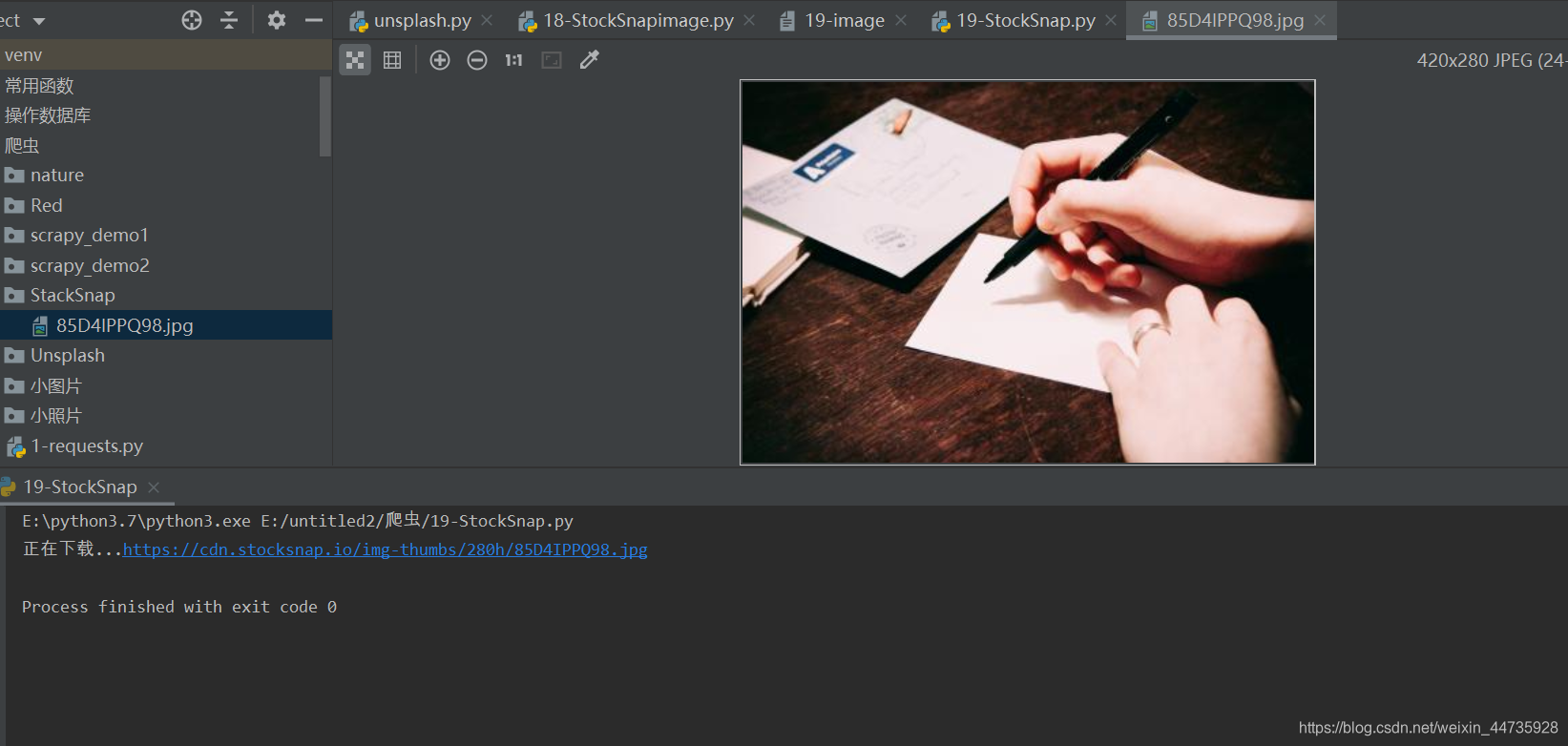
url = 'https://cdn.stocksnap.io/img-thumbs/280h/85D4IPPQ98.jpg'
download_image()
下载成功
四. 实现全部功能代码(若要下载更多图片,修改 " page = ‘数量’ ")
import requests
import json
import os
def get_url_list(url):
# 网站地址url = 'https://stocksnap.io/'
page = 10
for i in range(page):
detailed_url = url.format(i + 1)
get_image_url_list(detailed_url)
def get_image_url_list(url):
# 通过json的模块获取具体的信息
response = requests.get(url)
res_dict = json.loads(response.text)
results = res_dict['results']
for result in results:
img_id = result['img_id']
src = 'https://cdn.stocksnap.io/img-thumbs/280h/'
img_url = src + img_id + '.jpg'
download_image(img_url)
def download_image(url):
print('正在下载...' + url)
downloaddir = 'StackSnap'
if not os.path.exists(downloaddir):
os.mkdir(downloaddir) # 创建文件夹
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url, headers=headers)
filename = downloaddir + '/' + url.split('/')[-1] # 截取/后面的文件名
with open(filename, 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
# 由于有多页的Ajax ,所以用format函数,循环页数
url = 'https://stocksnap.io/api/load-photos/views/desc/{}'
get_url_list(url)
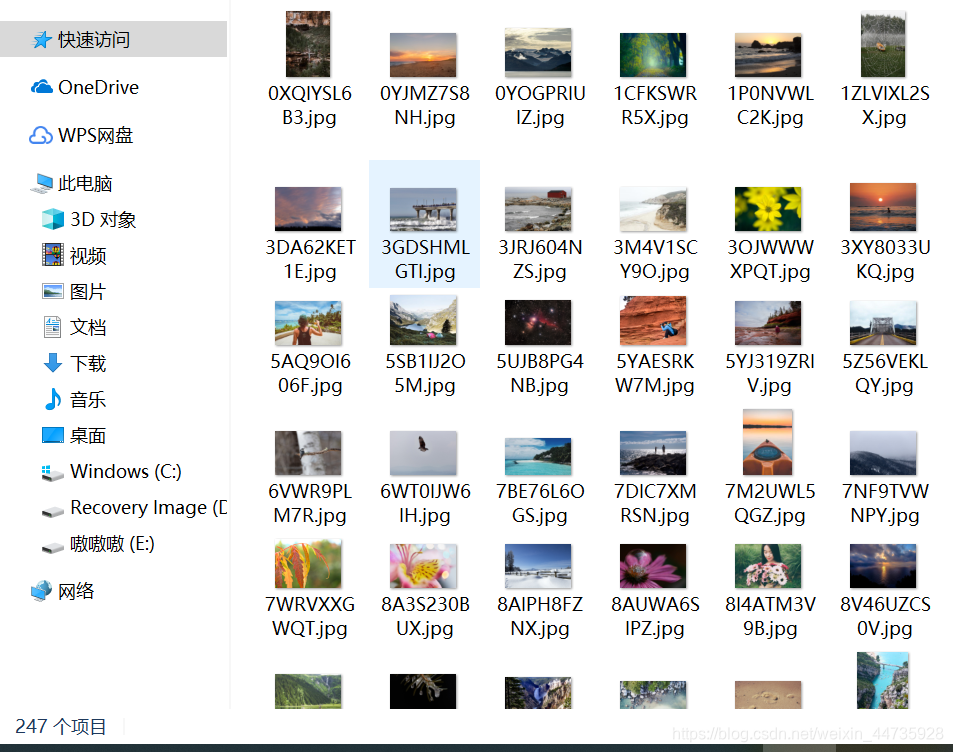
爬取到的图片

















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









