







一、文件IO_读写文件

1.文件来自哪里
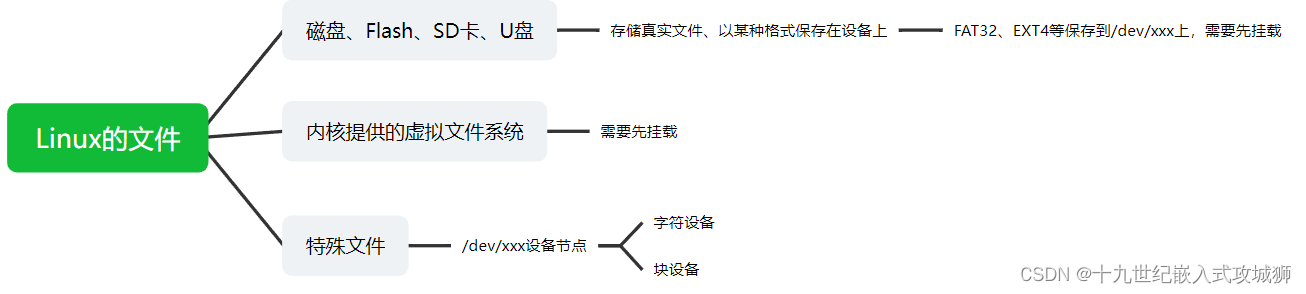
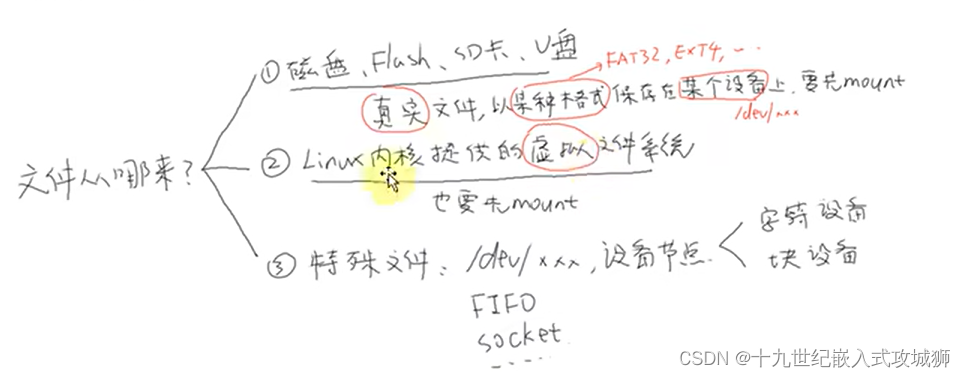
命令:cat /proc/mou (怎么知道是否自动挂载)

自动挂载的方法(将sda1挂载到mnt目录下):

注意:硬件上的设备需要进行挂载,然后才能访问。
2、虚拟文件系统(Linux内核)
查看虚拟文件命令:cat /proc/mounts
手工挂载命令:mount -t sysfs none /mnt (将虚拟文件挂载在mnt目录中,由于是虚拟的文件系统不需要正确的设备节点,所以用none)
3、特殊的设备节点(如/dev/xxx目录下的文件,)
open、write这些节点时,操作的是硬件,通过驱动程序去访问硬件。
例如:

2、怎么访问文件?

3、用法
可通过“main”命令进行查看(F往前翻、B往后翻、Q退出)。
在Linux中main函数一般是带参数的。
二、文件IO_内核接口

普通文件进入找“FS”,设备文件找驱动。
1、系统怎么调用内核态
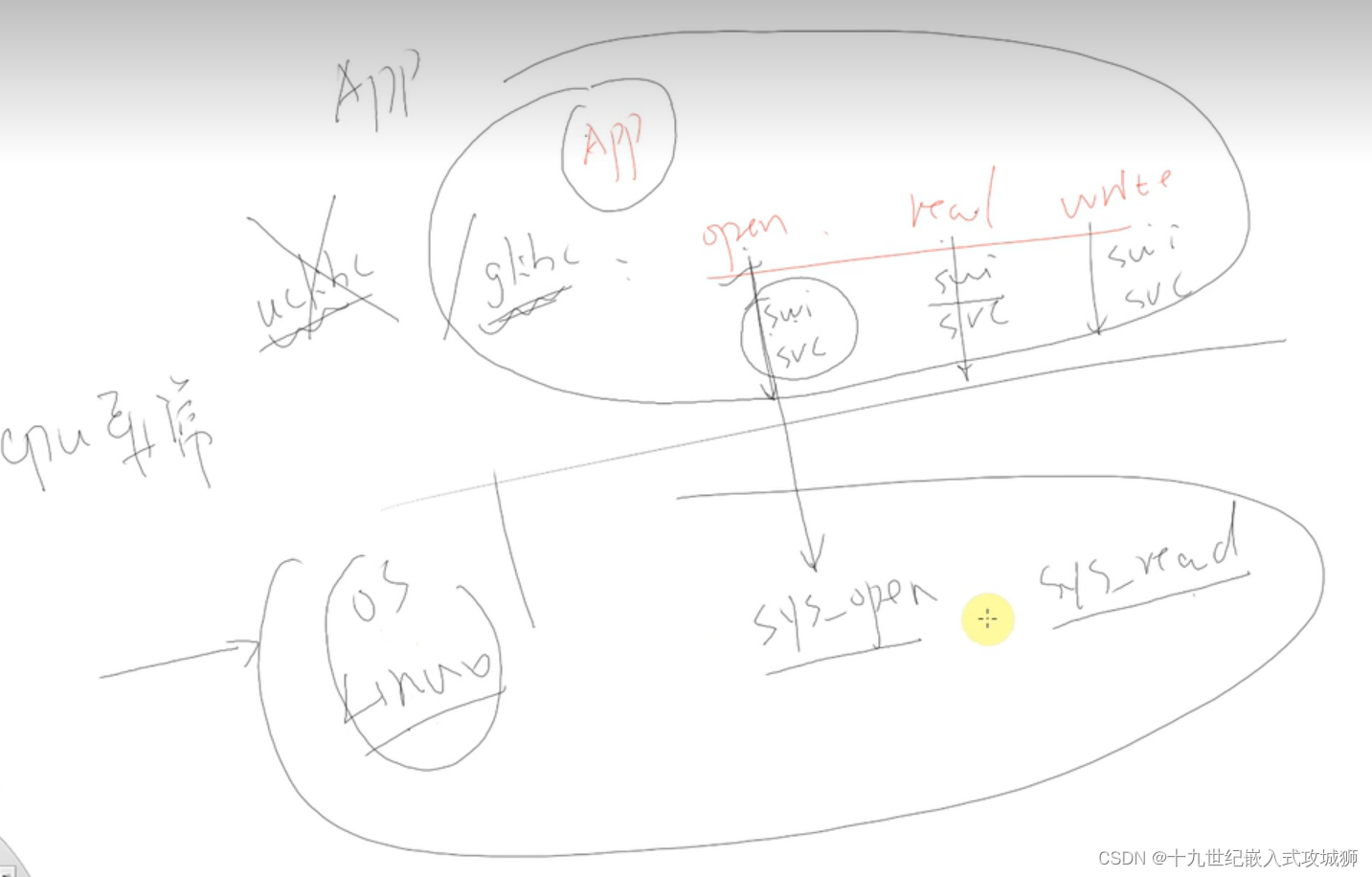
具体的:

内核里面sys_call、sys_open,要干的事

三、Framebuffer应用程序
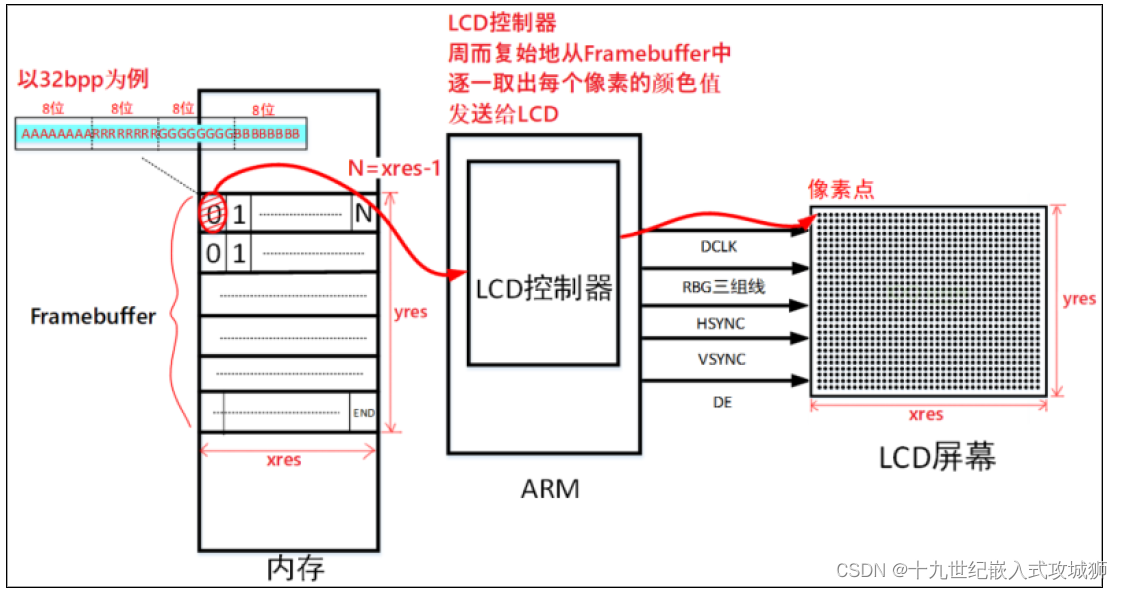
1、 frame(帧)、buffer(缓存)。在 Linux系统中通过 Framebuffer驱动程序来控制 LCD。这意味Framebuffer就是一块内存,里面保存着一帧图像。Framebuffer中保存着一帧图像的每一个像素颜色值,假设LCD的分辨率是1024x768,每一个像素的颜色用32位来表示,那Framebuffer的大小就是:1024x768x32/8=3145728字节。
BPP:bits per pixel(每个像素点用多少位表示)
工作原理如下图所示:
(1)、驱动程序设置好LCD 控制器:
根据LCD的参数设置 LCD控制器的时序、信号极性;
根据LCD分辨率、BPP分配Framebuffer(也就是说首先要知道屏幕的分辨率是多少,每个像素用多少位表示(BPP))。
为什么要知道分辨率是多少?比方说,你想修改点(x,y)对应的颜色时,用公式(y·xres + x)·bpp/8获得[offst]偏移地址,再加上Framebuffer中的首地址,就可以确定像素的地址在Framebuffer的哪里,在修改对应的数值即可。

(2)、APP 使用ioctl 获得 LCD 分辨率、BPP。
(3)、APP 通过mmap 映射 Framebuffer,在Framebuffer 中写入数据。
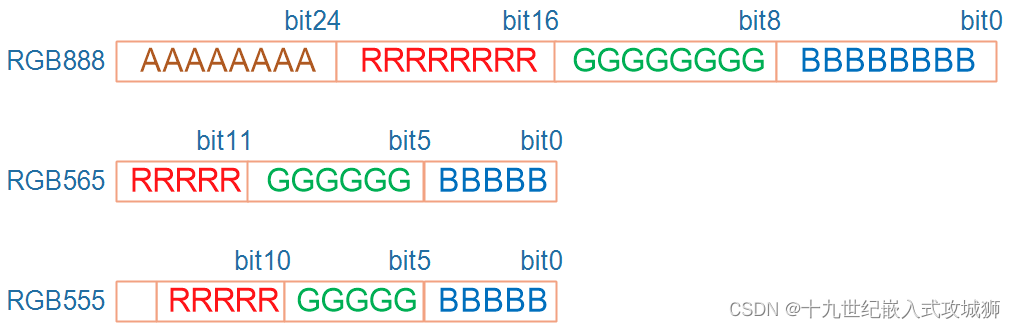
在不同的 BPP格式中,用不同的位来分别表示 R、G、B,如下图所示:
2、步骤
(1)、打开设备 函数:open
(2)、获取LCD参数,只需要关注可变的参数(var),分辨率、bpp(RGB)。

(3)映射Framebuffer

(4)描点函数
怎么将RGB888(32位)的颜色转换成RGB565(16位)的颜?红色可以取RGB888红色的高5位放入RGB565对应的位置,绿色可以取RGB888绿色的高5位放入RGB565对应的位置,蓝色可以取RGB888蓝色的高5位放入RGB565对应的位置。

四、字符的编码方式
1、对于字符显示,首先要显示哪些字符,其次字体显示什么形式。
对于第一个问题通过ASCLL来进行表示,而ASCLL又通过字节来进行表示,一个字节的7 位就 可以表示128 个数值,在ASCII 码中最高位(bit7)永远是0。

2、 对于超出128个数值以外的,通过ANSI(两个字节)来进行表示。ASNI 是ASCII 的扩展,向下包含ASCII。对于ASCII 字符仍以一个字节来表示,对于非ASCII 字符则使用2 字节来表示。并没有固定的ASNI 编码,它跟“本地化”(locale)密切相关。比如在中国大陆地区,ANSI 的默认编码是GB2312;在港澳台地区默认编码是BIG5。以数值“0xd0d6”为例,对于GB2312 编码它表示“中”;对于BIG5 编码它表示“笢”。所以对于ANSI 编码的TXT 文件,如果你打开它发现乱码,那么还得再次细分它的具体编码。
3、在ANSI 标准中,很多种文字都有自己的编码标准,汉字简体字有GB2312、繁体字有BIG5,这难免同一个数值对应不同字符。比如数值“0xd0d6”,对于GB2312 编码它表示“中”;对于BIG5 编码它表示“笢”。这造成了使用ANSI 编码保存的文件,不适合跨地区交流。UNICODE 编码就是解决这类问题:对于地球上任意一个字符,都给它一个唯一的数值。UNICODE 仍然向下兼容ASCII,但是对于其他字符会有对应的数值,比如对于“中”、“笢”,它们的数值分别是:0x4e2d、0x7b22UNICODE 中的数值范围是0x0000 至0x10FFFF,有1,114,111 即100 多万个数值,可以表示100 多万个字符,足够地球人使用了。4、UNICODE的编码实现
(1)、使用3 个字节表示一个UNICODE
(2)、UCS-2 Little endian/UTF-16 LE (表示小字节序),数值中权重低的字节放在前面
(3)、UCS-2 Big endian/UTF-16 BE(Big endian表示大字节序),数值中权重低的字节放在后面。
(4)、UTF8


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









