









 本文介绍了如何在Linux上安装ffmpeg并将其路径添加到环境变量,然后使用Python的AudioSegment库将m4a音频转换为wav。此外,文中详细讲解了librosa库在音频处理中的应用,包括加载、时长计算、频谱图和梅尔频谱的生成,以及Python音频补齐技术。
本文介绍了如何在Linux上安装ffmpeg并将其路径添加到环境变量,然后使用Python的AudioSegment库将m4a音频转换为wav。此外,文中详细讲解了librosa库在音频处理中的应用,包括加载、时长计算、频谱图和梅尔频谱的生成,以及Python音频补齐技术。
- 需要在linux上安装ffmpeg
参考博客 Linux上安装ffmpeg - 修改环境变量【这一点很重要,自己因为没有添加环境变量,捣鼓了很长时间】
将ffmpeg的绝对路径添加到 PATH 环境变量中,以让系统能找到ffmpeg的安装路径。
# /home//project/ffmpeg-6.1-amd64-static 替换成ffmpeg和ffprobe所在的文件夹
export PATH="/home//project/ffmpeg-6.1-amd64-static:${PATH}"
- python代码将m4a类型的音频文件转换为wav类型
# "AudioSegment库能够将"m4a"【苹果音乐的格式】类型的音频文件转换为wav类型"
from pydub import AudioSegment
import librosa
w4a_audio = AudioSegment.from_file(path, format="m4a")
w4a_audio.export("audio_countdown.wav", format="wav")
- librosa库对wav类型的文件进行处理、可视化
# y:audio time series. 而 sr表示 sampling rate of y,默认是22050
y, sr = librosa.load("audio_countdown.wav")
import matplotlib.pyplot as plt
print(f'y: {y[:10]}')
print(f'shape y: {y.shape}')
print(f'sr: {sr}')
import pandas as pd
pd.Series(y).plot(figsize=(10, 5),
lw=1,
title='Raw Audio Example')
plt.show()
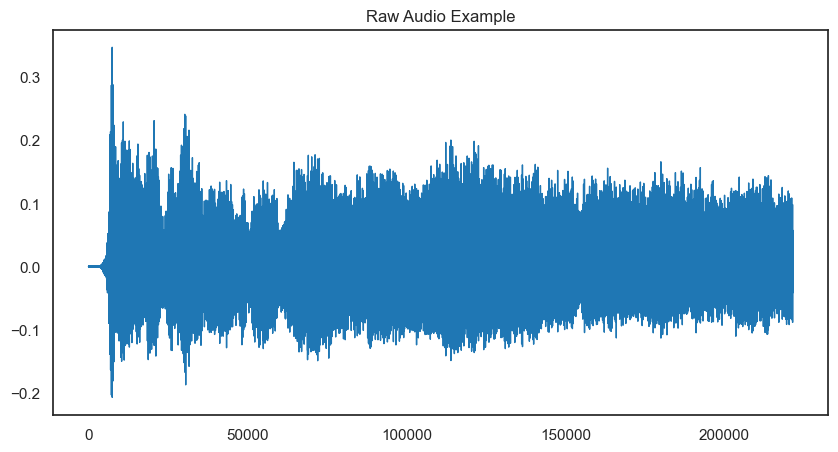
读取音频的时长
librosa.get_duration(y=None, sr=22050, S=None, n_fft=2048, hop_length=512, center=True, filename=None)
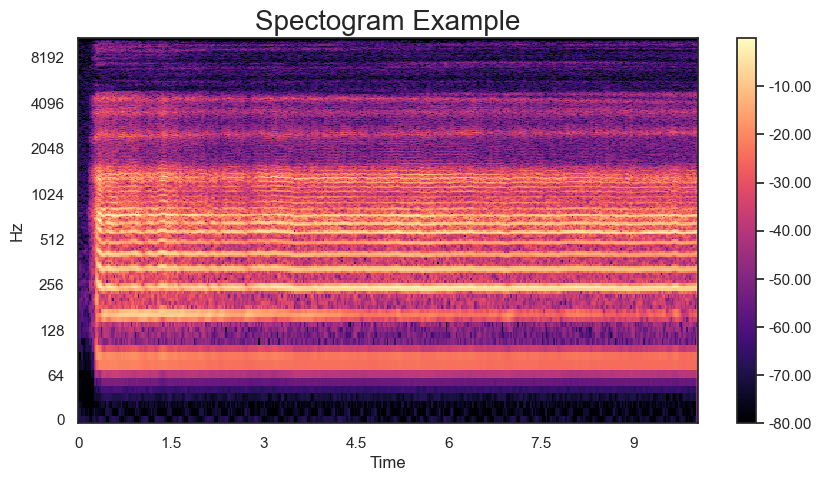
频谱图(Spectogram)是声音频率随时间变化的频谱的可视化表示,是给定音频信号的频率随时间变化的表示。‘.stft’ 将数据转换为短期傅里叶变换。 STFT转换信号,以便我们可以知道给定时间给定频率的幅度。 使用 STFT,我们可以确定音频信号在给定时间播放的各种频率的幅度。
短时傅里叶变换的计算公式
声音的频率可能会随着时间而变化,所以对长信号来说直接用FFT来分解整个信号会不妥, 所以用到短时傅里叶变换(short time
fourier transform), 只是把信号分成很多小段, 在每小段上进行FFT运算。
Spectrogram特征是目前在语音识别和环境声音识别中很常用的一个特征,由于CNN在处理图像上展现了强大的能力,使得音频信号的频谱图特征的使用愈加广泛,甚至比MFCC使用的更多。
import numpy as np
import matplotlib.pyplot as plt
# Short-time Fourier transform(stft)表示短期的傅里叶变换
D = librosa.stft(y)
# Convert an amplitude spectrogram to dB-scaled(dB 分贝) spectrogram.
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
S_db.shape
fig, ax = plt.subplots(figsize=(10, 5))
img = librosa.display.specshow(S_db,
x_axis='time',
y_axis='log',
ax=ax)
ax.set_title('Spectogram Example', fontsize=20)
fig.colorbar(img, ax=ax, format=f'%0.2f')
plt.show()
理解梅尔频谱(mel spectrogram)
Mel spectrogram和spectrogram的区别就是 mel spectrogram的频率是mel scale(mel滤波器)变换后的频率
介绍mel spectrogram和spectrogram的区别
方法一:使用时间序列求Mel频谱
y, sr = librosa.load('audio_audio.wav')
S=librosa.feature.melspectrogram(y=y, sr=sr)
方法二:使用stft频谱求Mel频谱
D = np.abs(librosa.stft(y))**2
S = librosa.feature.melspectrogram(S=D, sr=sr)
两种方法返回的矩阵相同,shape=(n_mels, t)
详细介绍了关于音频处理librosa库中大部分函数的含义
Python-音频补齐(即对不同长度的音频用数据零对齐补位)
音频补齐

















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









