







learning loss for active learning 论文学习笔记
这是CVPR 2019上的一篇文章,作者是韩国人。
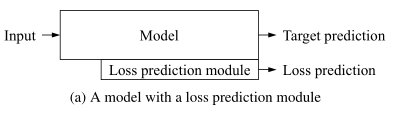
本文是设计了一个不针对具体任务的主动学习方法,在主model上附加了一个副model,主model可以是分类任务的model,也可以是检测任务的model;而副model是为了预测data的loss,从而将所有的data的loss排序选出topK个加入标签来进行主动学习训练。
作者提出,现有的主动学习方法总共分为三类:
- 基于uncertainty的(如找分类任务决策边界,二分类任务中分类概率0.5的,monte carlo dropout)
- 基于diversity(找到数据分布和whole dataset一致的small dataset)
- 基于expected model change(对网络的影响有多大)
副model利用主model里面的多个特征层来进行预测loss和训练,所以副model的结构比较简单,带来的负担也比较小。而且这个结构能够相对固定,面对不同的任务时都可以表现的比较好,因为本文主动学习的目的就是找到loss比较大的未标注数据,数据没有标注所以不能直接计算loss,需要将loss未卜先知预测出来,如何设计一个网络来学习预测未知数据的loss便是本文的主要目标。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 322
322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









