







Yoo D, Kweon I S. Learning loss for active learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 93-102.
摘要
本文提出了一种简单但是与任务无关新型主动学习方法,并且能有效的应用到深度网络。
本文在目标网络中附加了一个损失预测模块,并且通过学习来预测未标记输入的目标损失,然后损失预测模块能够找出目标模块最有可能预测错误的数据。
这个方法之所以能够与任务无关是因为网络只是通过单独的损失来训练而与目标任务无关。
介绍
目前的深度学习还没有达到训练数据饱和的状态,半监督或者无监督学习的性能仍然很大程度上与前期监督学习的训练有关。
不同的目标任务所需要的标记成本不同;标记的预算也是有限的。
给定一个未标记的数据池,有三种方法进行选择:基于不确定性,基于多样性以及预期模型可变性。其中基于委员会的方法对于大型数据集来说过于昂贵;基于多样性的方法虽然是任务无关,只取决于数据分布的特征空间,但需要额外设计一个位置不变的特征空间来定位任务,并且对于深度网络也是不现实的。
本文通过图像分类,人体姿态估计以及目标检测来证明了所提方法的有效性。
本文贡献:
提出了一个简单但有效的带有损失预测函数的主动学习方法,这个方法可以通过深度网络应用于任何任务;
利用现有的网络体系结构,通过分类、回归和混合三个学习任务来评估所提出的方法。
算法分析
本文提出的学习损失函数的主动学习模型主要由两部分组成:目标模块和损失预测模块。其中目标模块的函数为:

x 表示输入样本数据。损失预测模块的预测函数为:
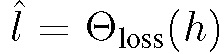
h 表示从目标模块的多个隐藏层中提取的样本数据 x 的特征集。
初始化已标注数据集后,通过学习得到初始化目标函数和损失预测函数。在主动学习过程中,利用学习后的损失预测模块对未标注池中的所有数据进行评估,得到数据损失对。之后人工标注 K 个损失最大的数据(Top-K),更新已标注数据集,重复循环,直到达到满意的性能。
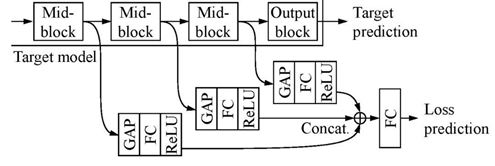
图 1 给出本文算法的处理过程。其中图 1(a)表示利用目标模块基于输入数据生成目标预测值,利用损失预测模块基于目标模块的隐藏层生成损失预测值。图 1(b)表示利用损失预测模块评估未标注数据集中的数据,找到 Top-K 预测损失值的数据,完成专家人工标注后将这些数据及类别信息添加到已标注的训练集中。

损失预测模块是本文算法的核心,其目标是最大限度地降低主动学习过程中针对不确定性的学习成本。损失预测模块的特点为(1)比目标模块小得多(2)与目标模块同时学习,无需增加额外学习过程。
损失预测模块的输入为目标模块的中间层提取的多层特征映射,这些多重连接的特征值使得损耗预测模块能够有效利用层间的有用信息进行损失预测。
首先,通过一个全局平均池(global average pooling, GAP)层和一个全连接层(full connected layer,FC),将每个输入特征映射简化为一个固定维度的特征向量。然后,连接所有特征并输入另一个全连接层,产生一个标量值作为预测损失。损失预测模块的结构见图 2。损失预测模块与目标模块的多个层次相连接,将多级特征融合并映射到一个标量值作为损失预测。
对于输入x,目标预测表示为![]() ,loss模块的输出为
,loss模块的输出为![]() ,而目标预测的loss可以表示为
,而目标预测的loss可以表示为![]() 来训练目标模块,y为目标真实值。这里又可以计算损失预测模块的loss(the loss for the loss prediction module)
来训练目标模块,y为目标真实值。这里又可以计算损失预测模块的loss(the loss for the loss prediction module) ![]() 。最终的联合的loss表达式为
。最终的联合的loss表达式为
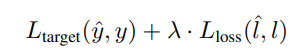
其中,λ为尺度的常量。整体过程如图:

本文没有直接使用均方误差(the mean square error,MSE) 定义损失函数,因为迭代过程中的损失值是一个变化的过程,这就会导致损失预测模型的训练过程中对应的数据的标签不一致,导致预测效果很差。而是进行样本数据对的比较。给定大小为 B 的小批量数据集,能够生成 B/2 个数据对,例如
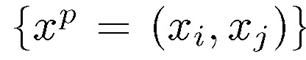
下标 P 表示一个数据对,B 应该是一个偶数。然后,通过考虑一对损失预测之间的差异来学习损失预测模块:
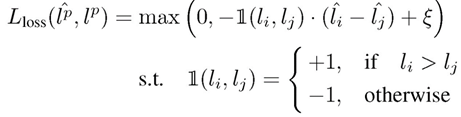
考虑第一种情况![]() 且模型预测的结果也满足
且模型预测的结果也满足![]() 那么损失值加上一个ξ后小于0,那么loss取0说明模型的预测关系是对的,不进行权重更新。如果
那么损失值加上一个ξ后小于0,那么loss取0说明模型的预测关系是对的,不进行权重更新。如果![]() 但模型的预测的结果
但模型的预测的结果![]() .则损失函数值大于0进行权重更新。这个损失函数则说明损失预测模型的实际目的是得到对应数据的损失值的大小关系而不是确定的损失值。
.则损失函数值大于0进行权重更新。这个损失函数则说明损失预测模型的实际目的是得到对应数据的损失值的大小关系而不是确定的损失值。
给定小批量 B,同时学习目标模块和损失预测模块的损失函数为:
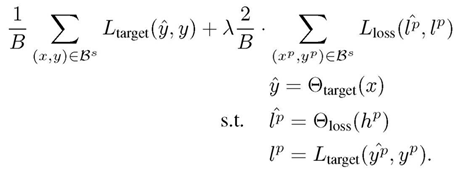
整体看是比较简单自然的方法,只是主模型和损失预测模型之间的关系论文没有做细致解释分析。二者联合训练时,后者的梯度会回传到主模型吗?如果回传是否会影响主模型的任务效果?是否回传的效果对比如何?
代码实现中是训练开始时二者是真的联合训练的,梯度都是回传的,经过一段训练之后损失预测模型的梯度不再回传给主模型。这样的处理应该是一种折中的方式,既兼顾了损失预测模型,又避免对主模型的效果有损伤。
实验验证
为了验证该方法的任务普适性,本文选择了三个目标任务进行实验,包括图像分类(分类任务),目标检测(分类和回归的混合任务),人体姿态估计(典型回归问题)。
图像分类:
本文选择 CIFAR-10 数据库,使用其中 50000 张图片作为训练集、10000 张图片作为测试集。由于训练集数据量非常大,本文在每个主动学习循环阶段选择一个随机子集(大小为 10000),从中选取 K 最不确定样本。以ResNet18作为目标模块。
损失预测模块,ResNet-18 由 4 个基本块组成 {convi_1; convi_2 j| i=2; 3; 4; 5},每个模块有两层。将损失预测模块连接到每个基本块,利用块中的 4 个特性来估计损失。
实验对比算法,随机抽样(random sampling),基于熵的采样(entropy-based sampling),芯组采样(core-set sampling)。

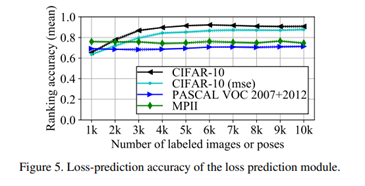
每个点均为使用不同的初始标记数据集进行 5 次实验的平均值。由实验结果可知,本文提出的算法在 CIFAR-10 库中的效果最好。
目标检测;
人体姿态估计。
总结与分析
本文提出了一种新的主动学习方法,适用于当前各类深度学习网络。本文通过三个主要的视觉识别任务和流行的网络结构验证了方法的有效性。虽然实验结果证明了该方法有效,但在该方法在抽样策略中并没有考虑数据的多样性或密度等特征。此外,在目标检测和姿态估计等复杂任务中,损失预测准确度相对较低,这些都将是后期的研究















 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









