







针对主动学习设计的学习损失,cvpr2019的文献,文献下载链接1905.03677.pdf (arxiv.org)
也是例会五分钟内介绍的文献,简单概括一下模型和核心内容。
文献主要设计了一个主动学习的方法,不针对具体的学习任务,可以加在主模型上。这里的主模型可以是分类模型或者检测模型等。

图a解释了这个模型:作者设计的主动学习模型是附加在主模型上的,它利用主模型特征层进行预测损失与训练。
图b则是一个主动学习的流程:从未标注数据池中选出一部分数据标注为模型进行初始化,主model对unlabeled进行预测,副model则预测数据的loss,从而将所有data的loss进行一个相对大小的排列,选出top-k加入到标注中去。这个过程其实是一个不确定度的度量方法,不过是根据输入预测loss,也就是作者认为loss大的数据标注后对网络更好。但是没有label的数据怎么求loss呢,这就是副model干得活了,它是设计了一个网络将loss未卜先知预测出来。
loss的计算用的不是梯度下降,原因是梯度的下降过程中loss也会下降,不稳定。所以作者用排序的loss作为损失函数,这样即使label的loss一直变化,但loss的相对大小没有变。
 用这个图简单介绍一下作者设计的求loss的过程,首先输入一张图产生两个输出,一个输出结果bounding box和类别,另一个输出是预测的loss。预测loss求法见上图:主模型对目标的预测与目标的ground truth求得目标损失,由副模型预测loss与目标损失求出 loss这两个损失进行训练。
用这个图简单介绍一下作者设计的求loss的过程,首先输入一张图产生两个输出,一个输出结果bounding box和类别,另一个输出是预测的loss。预测loss求法见上图:主模型对目标的预测与目标的ground truth求得目标损失,由副模型预测loss与目标损失求出 loss这两个损失进行训练。
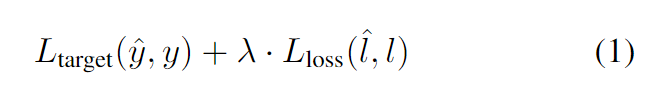
关于预测的loss求法,前面已经说过了这个求得是相对大小的loss,也就是说并不是求loss的确定值,而是求排列的顺序:

解释一下公式:下标i和j是对应组成一组图片对的两张图片(共B/2个图片对),如果>
,并且模型预测也满足Li>Lj,那么
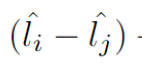 大于0,
大于0,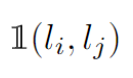 为正,括号内为负数,loss结果为0——模型预测正确,不进行权重更新。如果Li>Lj,但是模型预测为负,那么loss就大于0,需要进行权重更新。以这种方法就可以求出loss的相对大小啦。
为正,括号内为负数,loss结果为0——模型预测正确,不进行权重更新。如果Li>Lj,但是模型预测为负,那么loss就大于0,需要进行权重更新。以这种方法就可以求出loss的相对大小啦。
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









