










🚩 目的:将文档转换中的pdf样张导出成图像,然后通过图像分类模型识别出样张所属的类型(e.g.: 论文,书籍,简历,账单 …)
网络模型(算法的应用和集成)
样本数据
ImageNet起源:
WordNet: WordNet 是用于名词、动词、形容词和副词之间语义关系的词汇自然语言处理 (NLP) 数据库。它有 155,327 个词,组织在 175,979 个同义词组中,称为同义词组(有些词只有一个同义词组,有些词有几个同义词组)
ImageNet在 WordNet 中将图像附加到单词上
WordNet -> ImageNet
预训练模型
LeNet-5 (1989):经典的 CNN 框架
LeNet-5 是最早的卷积神经网络。 该框架很简单,因此许多类将其用作引入 CNN 的第一个模型。
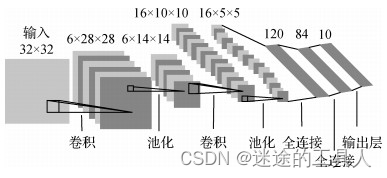
AlexNet (2012)
AlexNet 在 2012 年 ImageNet 挑战赛中上台,因为它以非常大的优势获胜。 它实现了 17% 的top5错误率,而第二名的错误率为 26%。 它的架构与 LeNet-5 非常相似。 它由 Alex Krizhevsky ,Ilya Sutskever ,以及Krizhevsky 的博士导师 Geoffrey Hinton 合作设计。 该模型有 6000 万个参数和 500,000 个神经元。可以将他看作是一个大号的LeNet。
GoogLeNet (2014)
它是由 Christian Szegedy 等人开发的。 来自谷歌研究。 这个模型的参数比 AlexNet 少 10 倍,大约 600 万。
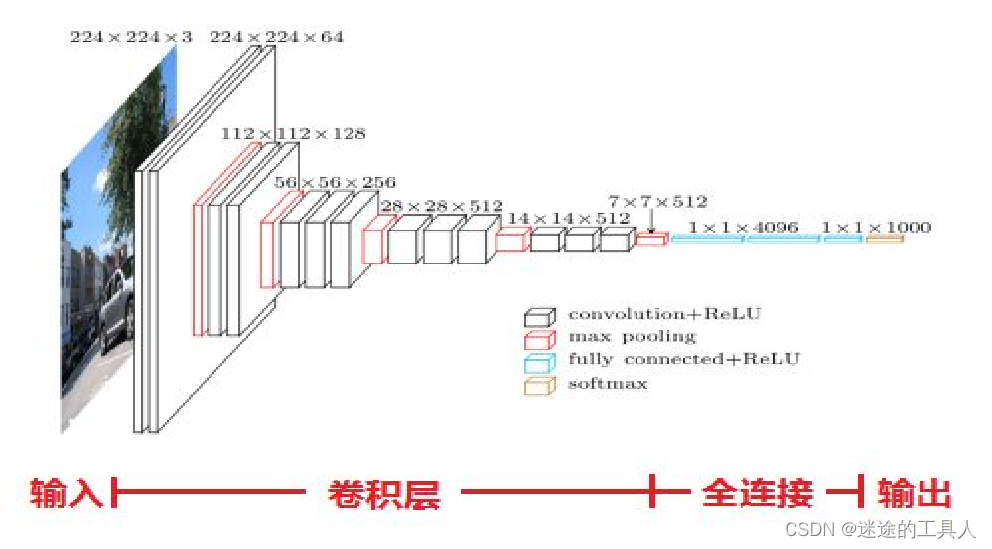
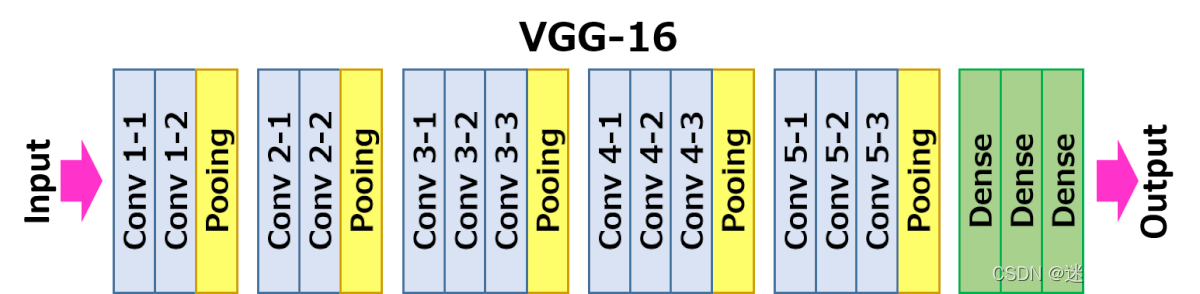
VGG-16 和 VGG-19 (2014)
在牛津大学的 K. Simonyan 和 A. Zisserman 的带领下,VGG-16 模型在他们的论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出。 他们使用非常小的 (3x3) 卷积滤波器将深度增加到 16 层和 19 层。 这种架构显示出显着的改进。 VGG-16 名称中的“16”指的是 CNN 的“16”层。 它有大约 1.38 亿个参数。 显然 VGG-19 比 VGG-16 大。 VGG-19 只提供比 VGG-16 稍微好一些的精度,所以很多人使用 VGG-16。
ResNet-50 (2015)
深度神经网络的层通常旨在学习尽可能多的特征。 Kaiming He、Xiangyu Zhang、Shaoqing Ren、Jian Sun 在他们的论文“Deep Residual Learning for Image Recognition”中提出了一种新的架构。 他们提出了一个残差学习框架。 这些层被公式化为参考层输入的学习残差函数,而不是学习未参考的函数。 他们表明,这些残差网络更容易优化,并且可以从显着增加的深度中获得准确性。 ResNet-50 中的“50”指的是 50 层。 ResNet 模型在 ImageNet 挑战赛中仅以 3.57% 的错误率赢得了比赛。
卷积神经网络
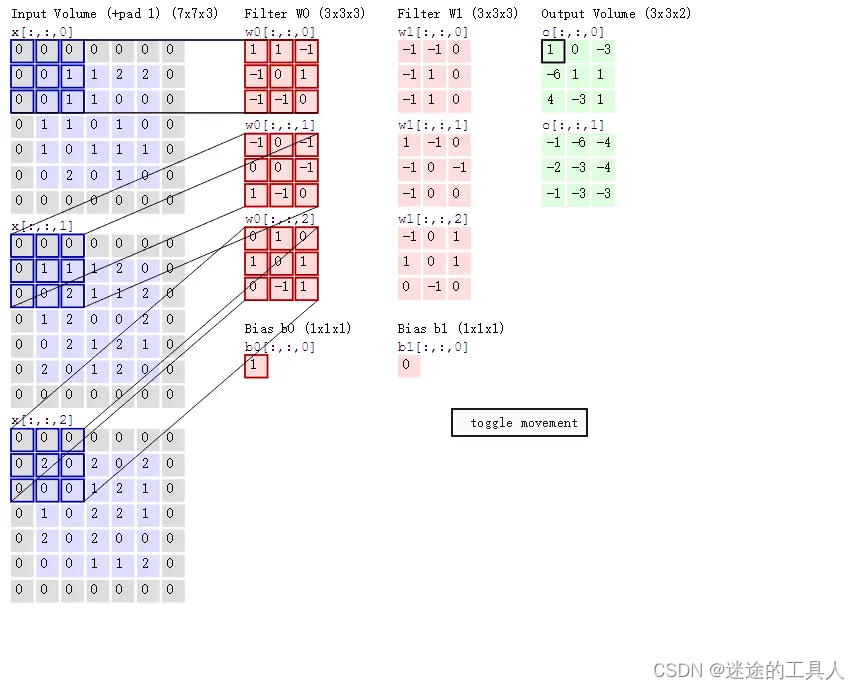
一个卷积神经网络主要由以下5层组成:
数据输入层/ Input layer
卷积计算层/ CONV layer
📌卷积层的作用就像筛子一样,专门挑选并提取图片或声音等数据里的重要特征,帮助电脑更好地理解和识别不同的模式。
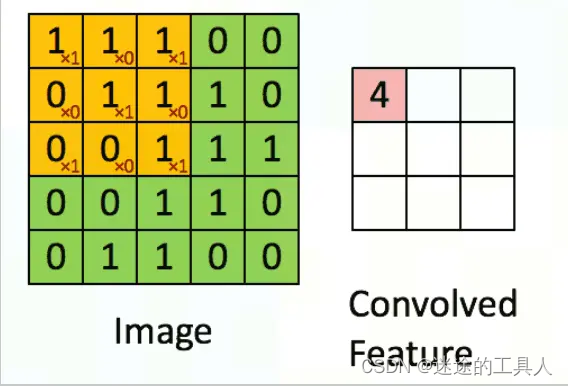
多通道卷积
一般卷积过程如下图所示,其中:
输入的图像的宽度 W = 5
卷积核 F = 3
填充值 P = 1
步长 S = 2
输出的特征 N = 3
初始通道数 3;输出通道数:2
池化层 / Pooling layer
👋
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
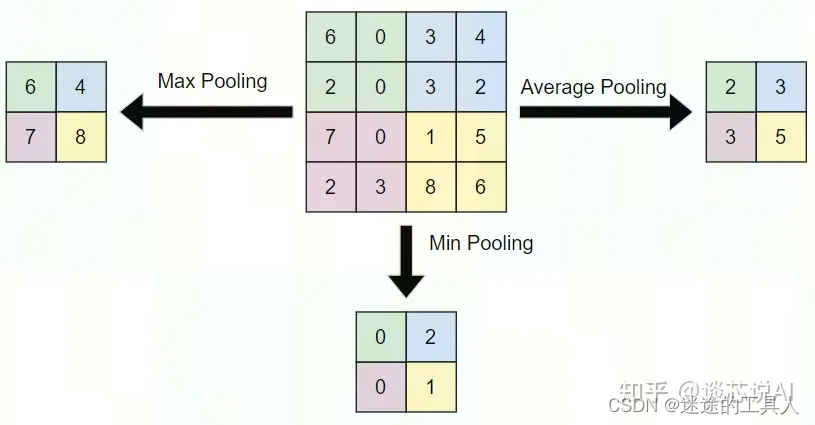
池化层不改变三维矩阵的深度,可以缩小矩阵的大小。池化操作可以认为是将一张分辨率高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而到达减少整个神经网络参数的目的。池化层本身没有可以训练的参数。一般有三种池化策略:
- 最大池化:把卷积后函数区域内元素的最大值作为函数输出的结果,对输入图像提取局部最大响应,选取最显著的特征。
- 平均池化:把卷积后函数区域内元素的算法平均值作为函数输出结果,对输入图像提取局部响应的均值。
- 最小池化:把卷积后函数区域内元素的最小值作为函数输出的结果,对输入图像提取局部最小响应,选取最小的特征(一般不用,因为现在使用大多是 relu激活,使用最小池化,会导致无意义)。如下图。
归一化
👋 归一化的作用就是让数据的大小和范围保持一致,帮助模型更稳定、高效地学习。
在深度学习中,归一化(Normalization)是指对输入数据进行一定的变换,使其在某些方面具有标准化的特性,通常是将输入数据缩放到均值为0,标准差为1的范围。归一化的目的是为了提高模型的训练稳定性、加速收敛速度,并有助于模型对不同尺度和分布的数据更好地适应。
对于图像分类任务中的预训练模型,归一化通常包括以下两个步骤:
- 零均值化(Zero-centered): 将输入数据的均值调整为零,即减去数据的全局均值。这有助于防止训练过程中的梯度消失或梯度爆炸问题。
- 标准化(Standardization): 将零均值化后的数据除以其标准差,使数据的标准差变为1。这有助于确保数据的尺度一致,防止某些特征对模型的训练产生过大的影响。
对于图像数据,还有一种特殊的归一化方式,即将像素值缩放到[0, 1]范围内。这可以通过将像素值除以255(如果图像数据的像素范围是0-255)来实现。
归一化对于深度学习模型的训练和性能非常重要。在预训练模型中,如果模型在训练阶段使用了某种特定的数据预处理方式,那么在使用该模型进行预测时,输入数据也需要按照相同的方式进行预处理,以确保模型的输入数据与训练时一致。这样可以保证预训练模型在新任务上的表现更为稳定和可靠。
ReLU激励层 / ReLU layer 作用?
🔔激活函数就像是给神经网络的计算过程加入调料,让网络能够捕捉到更复杂的数据规律,提高处理能力。
卷积神经网络基础(卷积,池化,激活,全连接) - 知乎 (zhihu.com)
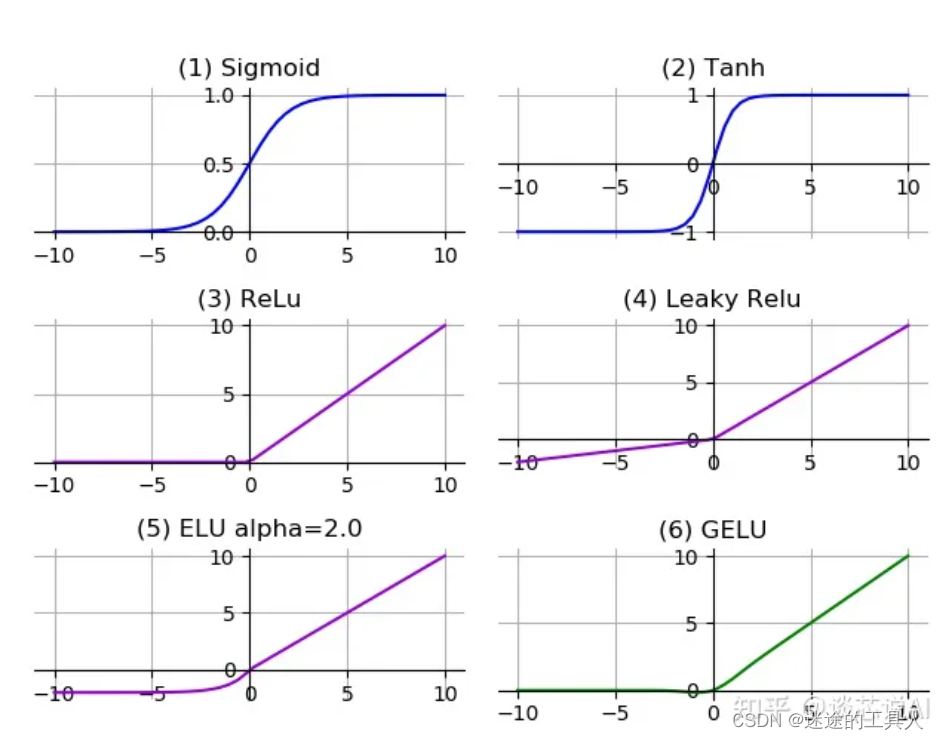
定义
💡激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
疑问?
-
为什么说没有激活函数的模型就是线性变化输出?

-
为什么神经网络的每一层 输出=Wx+b,不能是 输出=W logx+b 之类的吗,这样结果不就是线性的吗?

白话解释激活函数

全连接层 / FC layer
👋全连接层就像是一个信息汇总员,把前面提取到的各种特征综合起来,做出最终的决策或分类。
全连接层,指的是每一个结点都与上一层的所有结点相连(示意图如上图所示),用来把前面几层提取到的特征综合起来。由于其全连接的特性,一般全连接层的参数也是最多的。

举个例子,一张画着猫咪的图片,经过几十层卷积的特征提取,很有可能已经提取出了几十个甚至上百个特征,那我们如何根据这几十上百个特征来最终确认,这是一只猫呢?
把上面的问题细化并且简化一下,不说几十上百个特征,就说卷积层只提取了3个特征:分别是鼻子,耳朵和眼睛。实际上,有鼻子、耳朵和眼睛这三个特征的动物有很多,我们并不能只根据某个动物有鼻子、耳朵和眼睛,就把它简单的认为是一只猫。
那么就需要一种方法,把鼻子、耳朵和眼睛这三个特征进一步融合,使得神经网络看到这三个特征的融合集合之后,可以区分这是一只猫而不是一只狗。
上面的例子比较简单,实际网络中卷积提取的特征远远不止3个,而是成百上千个,将这些特征进一步融合的算法,就是全连接。
**或者说,全连接,可以完成****特征的进一步融合。使得神经网络最终看到的特征是个全局特征(一只猫),而不是局部特征(眼睛或者鼻子)。**对于这个问题有个比较形象的回答,大意是说:
假设你是一只蚂蚁,你的任务是找小面包。这时候你的视野比较窄,只能看到很小一片区域,也就只能看到一个大面包的部分。
当你找到一片面包之后,你根本不知道你找到的是不是全部的面包,所以你们所有的蚂蚁开了个会,互相把自己找到的面包的信息分享出来,通过开会分享,最终你们确认,哦,你们找到了一个大面包。
上面说的蚂蚁开会的过程,就是全连接,这也是为什么,全连接需要把所有的节点都连接起来,尽可能的完成所有节点的信息共享。
说到这,大概就能理解全连接的作用了吧。
ViT(Vision Transformer)
👋摘要
虽然 Transformer 架构已成为 NLP 任务的事实标准,但它在 CV
中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们证明了这种对 CNNs
的依赖是不必要的,直接应用于图像块序列 (sequences of image patches) 的纯 Transformer
可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 (ImageNet、CIFAR-100、VTAB
等),与 SOTA 的 CNN 相比,Vision Transformer (ViT) 可获得更优异的结果,同时仅需更少的训练资源。

Transformer
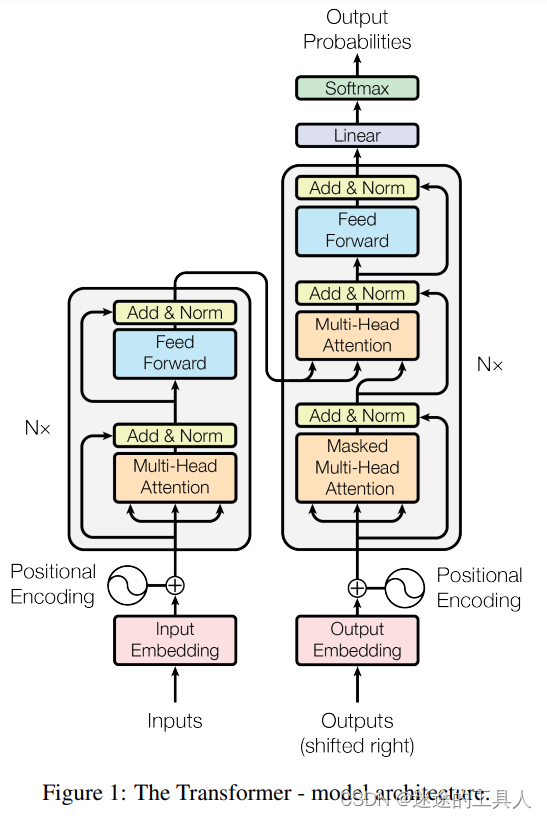
Multi-Head Attention
推荐文章【史上最小白之Attention详解_target attention-CSDN博客】
📌第一眼看这个图你的关注点在哪里?


Feed Forward Net(前馈网络)

ADD & Norm

shifted right

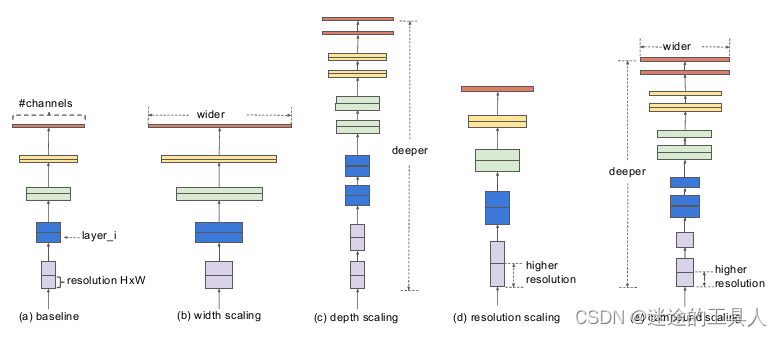
EfficientNet网络解读(复合模型缩放)
📌 算力增长时代的产物 ↓↓↓见下面的NAS
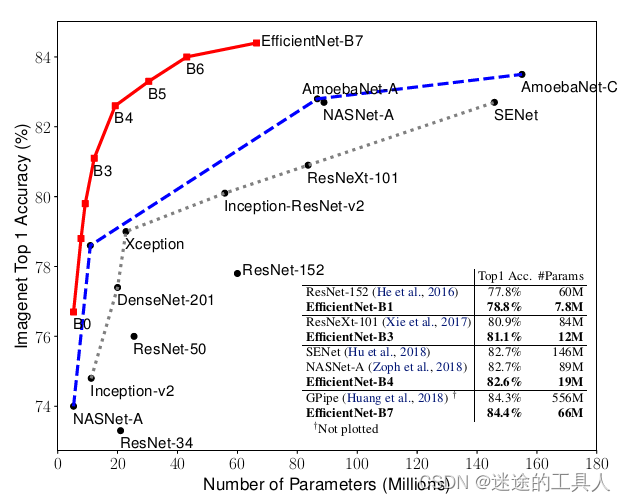
卷积神经网络(cnn)通常是以固定的资源成本开发,然后在更多资源加入进来时扩大规模,以达到更高精度。例如,ResNet[1]可以通过增加层数将
ResNet-18扩展到
ResNet-200,GPipe[2] 通过将
CNN baseline扩展4倍,在
ImageNet[3]上实现了84.3%
的准确率。 传统的模型缩放实践是任意增加 CNN 的深度或宽度,或使用更大的输入图像分辨率进行训练和评估。
虽然这些方法确实提高了准确性,但它们通常需要长时间的手动调优,并且仍然会经常产生次优的性能。
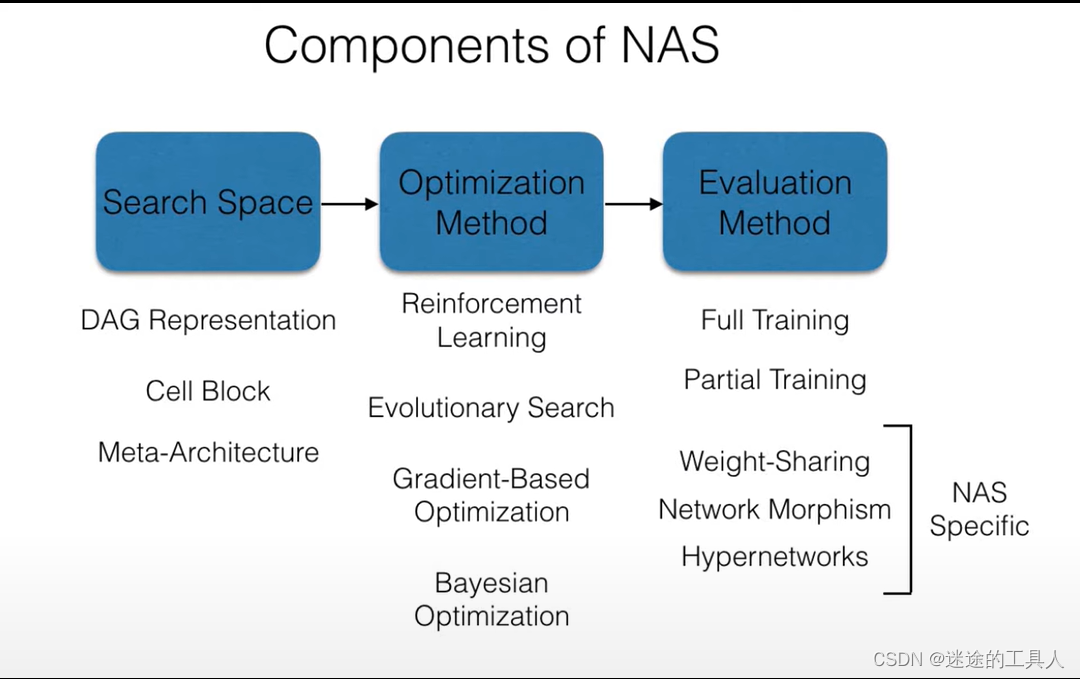
NAS
🔔 NAS代表神经架构搜索(Neural Architecture
Search)。它是一种自动化的方法,旨在通过搜索神经网络的结构和超参数来优化神经网络模型的性能和效率。
传统的神经网络模型结构通常是由人工设计的,需要经过大量的试验和调整来找到最佳的结构和超参数。而NAS则通过自动化的方式,利用搜索算法(如进化算法、遗传算法、强化学习等)在给定的搜索空间中,搜索最优的神经网络结构和超参数组合。
NAS的工作流程通常包括以下步骤:
- 定义搜索空间:确定神经网络的结构和超参数的搜索空间,包括网络的层数、每层的节点数、激活函数、连接方式等。
- 搜索策略:选择合适的搜索算法来在搜索空间中探索潜在的神经网络结构和超参数组合,例如进化算法、遗传算法、强化学习等。
- 性能评估:对于每个候选的神经网络结构和超参数组合,评估其在验证集或测试集上的性能,通常使用准确率、损失函数值等指标来衡量。
- 更新策略:根据性能评估结果,更新搜索策略,调整搜索空间或搜索算法的参数,以便更好地搜索潜在的最优解。
NAS的优势在于它可以自动发现适合特定任务的神经网络结构和超参数组合,从而提高了模型的性能和效率。它已经被广泛应用于图像分类、目标检测、语音识别等领域,并取得了显著的成果。
基于EfficientNet-b3的图像分类模型微调(又名迁移学习)
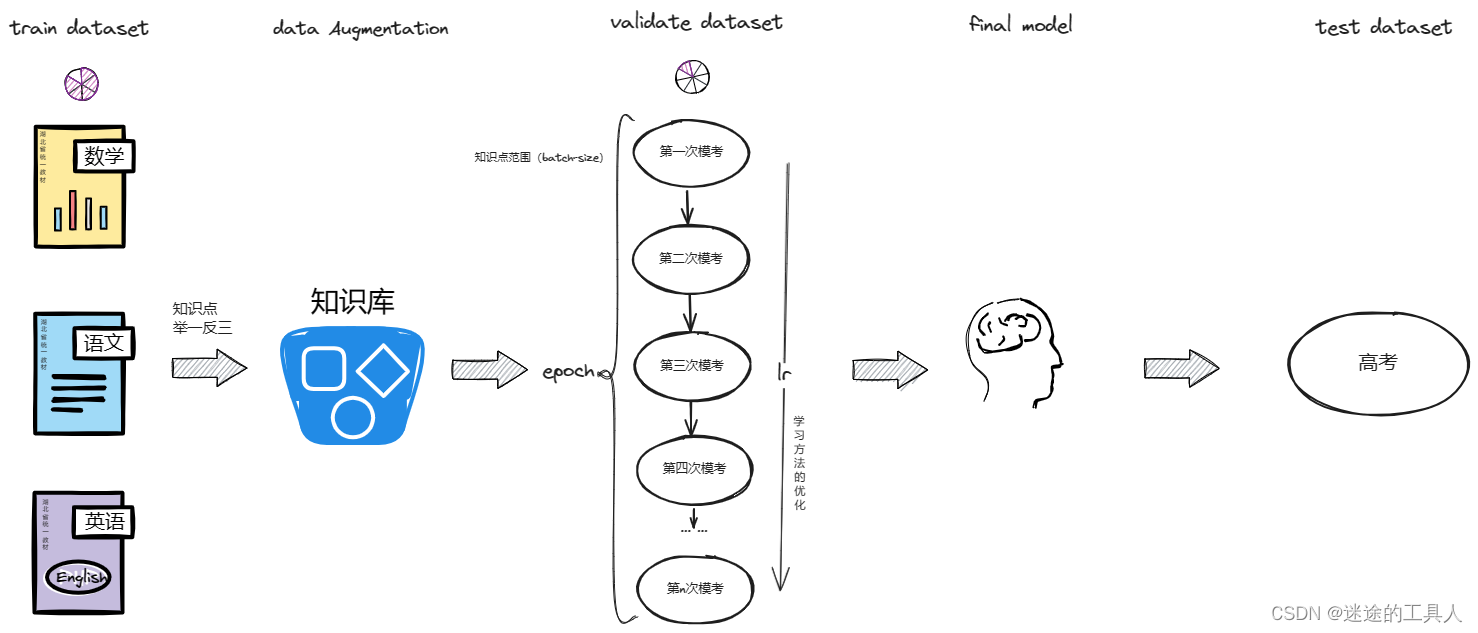
第一阶段:准备数据集,数据处理
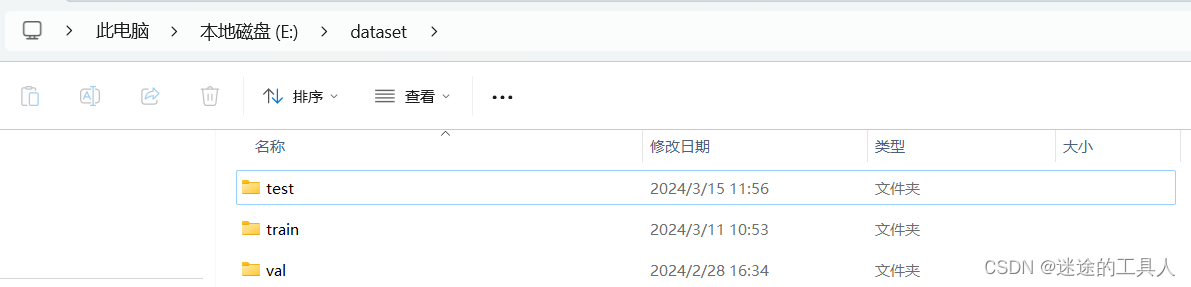
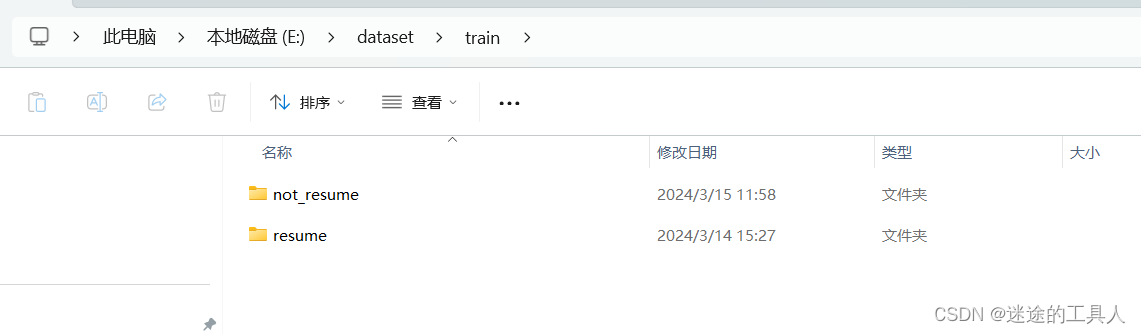
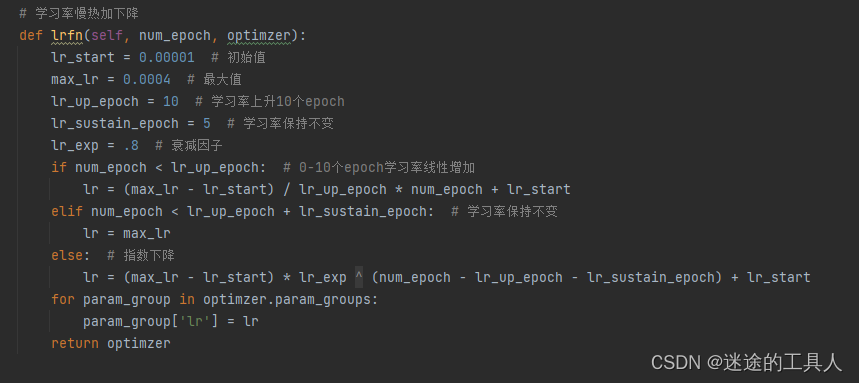
第二阶段:学习参数设置,优化
第三阶段:测试集验证
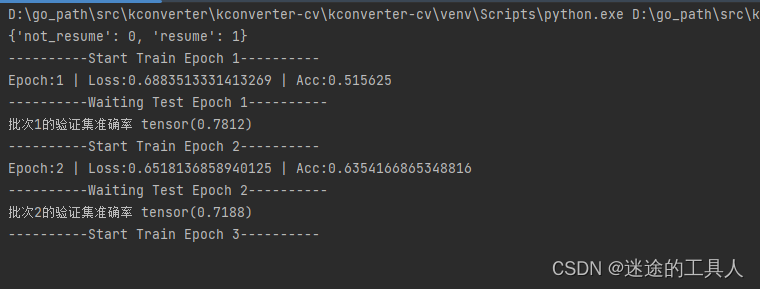
训练过程输出















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









