






 本文介绍了Logit回归和Probit回归的区别,它们分别基于logistic分布和正态分布处理二值因变量。Logit模型常用于解决线性概率模型的问题,而Probit模型提供类似但更精确的拟合。文章还通过员工离职案例展示了如何应用这两种方法及其边际效应分析。
本文介绍了Logit回归和Probit回归的区别,它们分别基于logistic分布和正态分布处理二值因变量。Logit模型常用于解决线性概率模型的问题,而Probit模型提供类似但更精确的拟合。文章还通过员工离职案例展示了如何应用这两种方法及其边际效应分析。
回归是研究因变量Y对自变量X的依赖关系。当因变量Y为二值定类变量时,我们通常会选择使用logit回归,实际上还有一种方法是Probit回归。这两个区别在于模型中随机扰动项的先验服从什么分布:如果是正态分布就是probit模型,若为logistic分布就是logit模型。
1 概述
1.1 背景介绍
一般情况下,在我们研究的回归模型中,都隐含的假定了因变量(Y)是定量的,而解释变量(X)是定量、定性(或虚拟变量)。
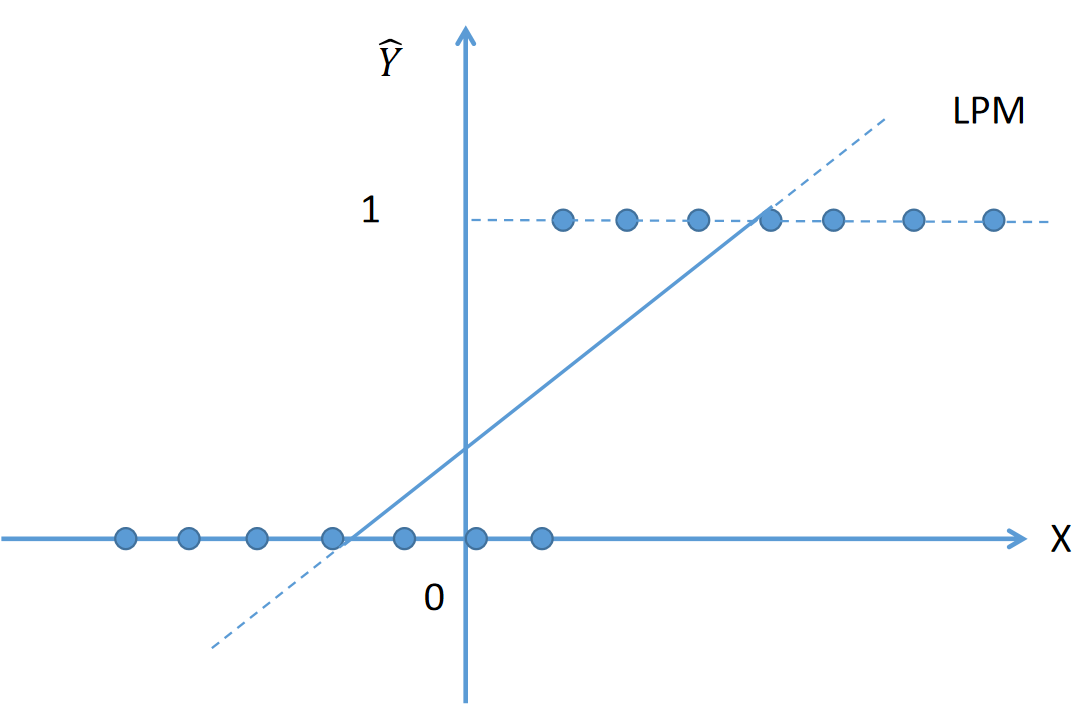
当因变量(Y)为二值定性的情况:比如一个家庭是否拥有一所住房,如拥有 Y=1,不拥有 Y=0,则被称为线性概率模型。
当因变量为二值时,X 与 Y 的关系如图中的点:
要预测的值y为期望
![]()
令
![]()
1.2 线性概率模型
若用线性概率模型拟合因变量时,则会存在以下问题:
- 由于 E(Yi / Xi) 度量给定 X 事件下 Y 发生的概率,因此概率必须落在0与1之间,LPM无法保证的估计值落在 0 与 1 之间;
- 对于给定的 X,Y = 0 或Y= 1,因此所有的 Y 值必须落在 X 轴或者 Y=1 的一条直线上。而线性模型则无法很好的模拟这样的散点。
- 线性回归模型假定 Y 估计值随 X 而线性增加,即 X 的边际或临界效应(X连续增加的每一单位中所得到的Y增量)一直保持不变(一般边际效用是递减的)。
1.3 Logit模型
标准累计 Logistic 分布的函数:
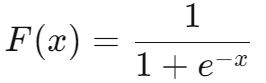
建立 logit 与线性回归的关系:
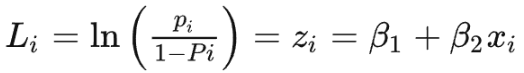
可变换为
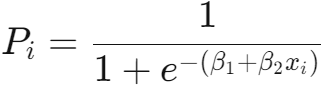
可解决上述线性概率模型的问题,可以很好的进行拟合。
1.4 Probit模型
当回归中因变量取 0 或 1 时,很容易使用 CDF(累计分布函数)取建立回归模型。当选用 logistic 时,称为logit模型;选用正态分布函数时,则是profit模型。
Logit模型是Logistic函数的累积概率函数,同样的,正态函数记为 �
Probit 变换与 Probit 回归模型如下:
![]()
对应的累计概率函数,即标准正态分布的累积概率函数:
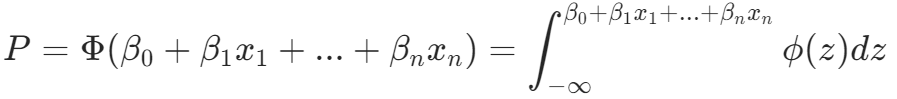
如下图
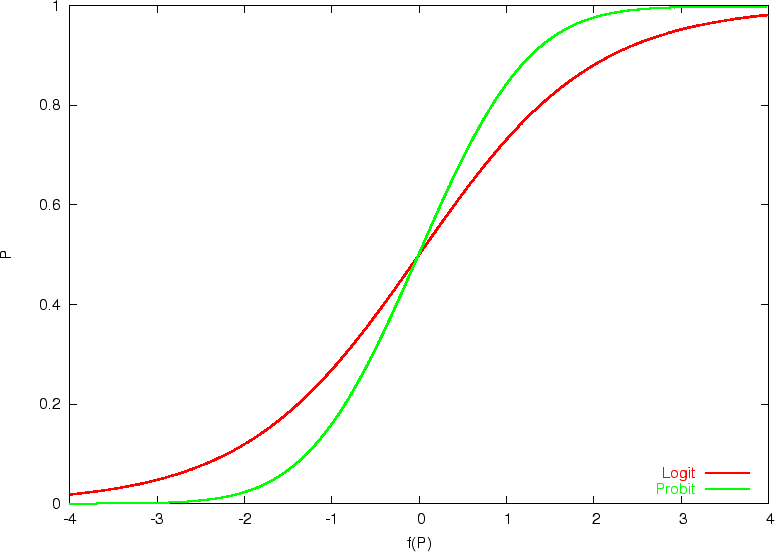
绿色曲线为Probit,红色曲线为Logit,可见Probit模型与Logit模型很相似,可用于解决上面的二分类问题。
1.5 极大似然法估计参数
个体(非群组)数据的 Probit 模型的极大似然估计,假设我们对给定个人收入 X 的情况下估计一个人拥有住房的概率感兴趣,我们还假定这个概率可由 Probit 函数表示:
![]()
我们不能实际观测Pi,只能观测到结果 Y=1(有房)和 Y=0(无房)。
每个Pi都是一个伯努利随机变量,所以可写成:
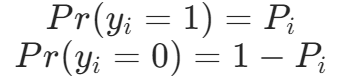
假设我们有一个 n 次观测的随机样本。令fi(Yi)表示Yi=1或 0 的概率,观测到 n 个 Y 值的联合概率,即f(Y1,...,Yn)为:
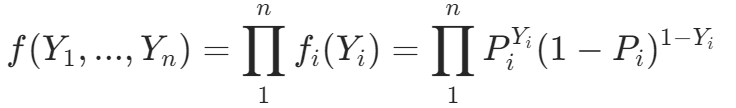
每个 Yi 都是独立的,而且有相同的 logistic 密度函数,所以可以将联合密度函数写成个别密度函数的乘积。
我们对(1)取对数,便得到对数似然函数LLF:
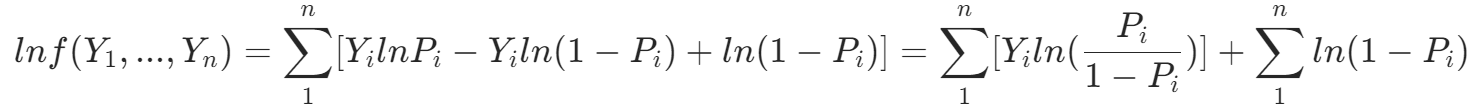
2 案例介绍
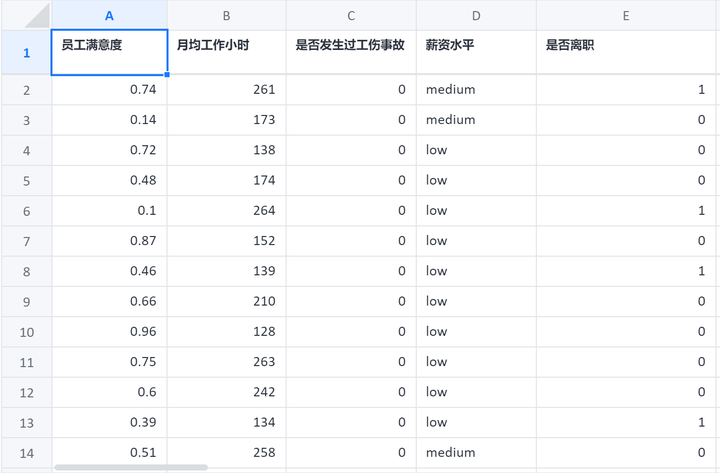
根据员工满意度、月均工作小时、工伤事故、薪资水平四个影响因素(自变量)研究员工是否离职。
● 对于连续自变量的边际效应值的意义为:该自变量每增加一个单位,带来因变量的概率上升或下降多少百分比。
● 对于哑变量化的0-1分类自变量的边际效应值意义为:该变量每升高一个单位(即分类水平从0变为1),发生因变量的概率上升或下降了多少百分比。
员工满意度显著性 值为0.000***,水平上呈现显著性,拒绝原假设,因此员工满意度会对是否离职产生显著性影响,意味着员工满意度每增加一个单位,离职概率比不离职的几率增加或减少了62.581%。
5 注意事项
- 因变量 Y 是二分类变量
- 有至少1个自变量,自变量可以是连续变量,也可以是分类变量
- 每条观测间相互独立。分类变量(包括因变量和自变量)的分类必须全面且每一个分类间互斥
- 自变量之间无多重共线性
- 自变量中分类变量较多时,可考虑使用Logistic回归
- 当自变量中连续变量较多且符合正态分布时,使用Probit回归


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









