







本文的pdf文件:link
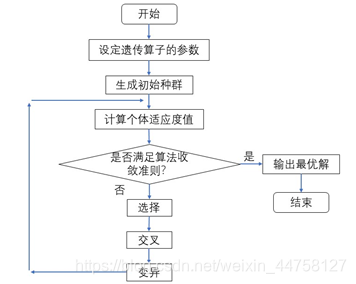
遗传算法是群智能算法中的一个分支,是一类基于种群搜索的优化算法,受自然界生物进化机制的启发,通过自然选择、变异、重组等操作,针对特定的问题取寻找出一个满意的解。其遗传进化过程简单,容易理解,是其他一些遗传算法的基础。
遗传算法的搜索特点是以编码空间代替问题的参数空间,以适应度函数为评价依据;将编码集作为遗传的基础,对个体进行遗传操作,建立一个迭代过程。首先,算法从一个由个体组成的种群开始,对每个种群个体进行适应度评价;其次,利用个体的适应度选择个体,并利用交叉和变异等遗传算子作用其上,产生后代个体;最后,在原种群个体和后代个体中选择个体生成下一代种群。
本文主要通过遗传算法来求解函数优化和TSP两个问题。函数优化是我们随时都是遇到的问题,而传统的求解方法更多的是基于数学理论来求解,通过求导等一系列数学计算来发掘函数本身的单调性等一系列性质并以此来寻找函数的极大极小值,但是普通的求解方法对问题本身要求很高,例如函数必须可导,或者必须是凸函数等,所以在面对一些非凸函数或者奇异函数时就不可以用传统求解方法,而只能采用暴力搜索等算法。但是遗传算法对于函数本身没有要求,它可以看作是一种指导性搜索算法,利用前一代所遗留的信息来指导下一代的进化,这样每一个计算得到的值都可以在此利用,不重复计算。所以遗传算法在求解一些复杂函数最优值的问题中被广泛使用。
TSP问题是一个典型的NP问题,暴力求解的复杂度非常高,但是遗传算法的提出可以使得其在可接受迭代次数内达到收敛,本文利用遗传算法来求解所给城市的最优路线。
一、问题重述
根据遗传算法求解问题,分别运用遗传算法求解低维单目标优化问题,高维单目标优化问题和TSP问题。
二、背景和发展
遗传算法是近年来迅速发展起来的一种全新的随机搜索与优化算法,其基本思想是基于达尔文的遗传学说,该算法于1975年创建。
1971年,首次将遗传算法用于函数优化。
1975年,出版了《自然系统和人工系统的自适应》,第一本系统的阐述了遗传算法的著作。
1989年,《搜索,优化和机器学习中的遗传算法》,总结了遗传算法研究的主要成果,对遗传算法及其应用做了全面而系统的阐述,同年并提出了基于自然选择远测创造性的提出了用层次化的计算机程序来表达问题的遗传程序设计方法。
1991年,提出了基于邻域交叉的交叉算子,并将其运用到TSP问题中。
目前,遗传算法已经广泛应用,主要有基于遗传算法的机器学习,遗传算法和神经网络,并行处理人工生命等领域。
三、原理分析
3.1 定义
进化计算的基本思想来源于生物学中的基本知识:生物从简单到复杂,从低级到高级的进化过程是一个自然的稳健的优化过程。这一进化过程的目的在于使生命个体更好的适应周边环境。生物种群通过“优胜劣汰”及遗传变异来达到进化的目的。
目前研究的进化算法主要有四种:遗传算法,进化规划,进化策略和遗传编程。
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,包括选择、交叉和变异操作。
标准的遗传算法主要有如下主要特点:
1,遗传算法必须通过适当的方法对问题的可行解进行编码。解空间中的可行解是个体的表现型,它在遗传算法的搜索空间中对应的编码形式是个体的基因型。
2,遗传算法基于个体的适应度来进行概率选择操作。
3,在遗传算法中,个体的重组使用交叉算子。交叉算子是遗传算法所强调的关键技术,它是遗传算法中产生个体的主要方法,也是遗传算法区别于其他进化算法的一个主要特点。
4,在遗传算法中,编译操作使用随机变异技术。
5,遗传算法擅长对离散空间的搜索,它较多地应用于组合优化问题。
直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
相关术语:
• 基因型(genotype):性状染色体的内部表现;
• 表现型(phenotype):染色体决定的性状的外部表现,或者说,根据基因型形成的个体的外部表现;
• 进化(evolution):种群逐渐适应生存环境,品质不断得到改良。生物的进化是以种群的形式进行的。
• 适应度(fitness):度量某个物种对于生存环境的适应程度。
• 选择(selection):以一定的概率从种群中选择若干个个体。一般,选择过程是一种基于适应度的优胜劣汰的过程。
• 复制(reproduction):细胞分裂时,遗传物质DNA通过复制而转移到新产生的细胞中,新细胞就继承了旧细胞的基因。
• 交叉(crossover):两个染色体的某一相同位置处DNA被切断,前后两串分别交叉组合形成两个新的染色体。也称基因重组或杂交;
• 变异(mutation):复制时可能(很小的概率)产生某些复制差错,变异产生新的染色体,表现出新的性状。
• 编码(coding):DNA中遗传信息在一个长链上按一定的模式排列。遗传编码可看作从表现型到基因型的映射。
• 解码(decoding):基因型到表现型的映射。
• 个体(individual):指染色体带有特征的实体;
• 种群(population):个体的集合,该集合内个体数称为种群。
3.2 遗传算法的基本流程
遗传算法的搜索特点是以编码空间代替问题的参数空间,以适应度函数为评价依据;将编码集作为遗传的基础,对个体进行遗传操作,建立一个迭代过程。首先,算法从一个由个体组成的种群开始,对每个种群个体进行适应度评价;其次,利用个体的适应度选择个体,并利用交叉和变异等遗传算子作用其上,产生后代个体;最后,在原种群个体和后代个体中选择个体生成下一代种群。
3.3 编码
染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。
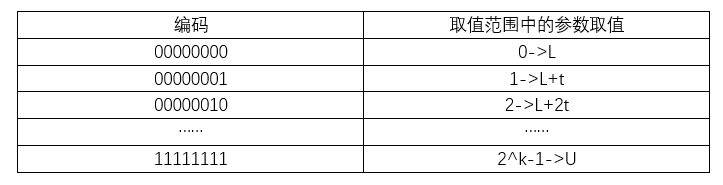
遗传算法的编码有浮点编码、二进制编码和符号编码,这里只介绍二进制编码规则。二进制编码既符合计算机处理信息的原理,也方便了对染色体进行遗传、编译和突变等操作。设某一参数的取值范围为(L,U),使用长度为k的二进制编码表示该参数,则它共有2^k种不同的编码。该参数编码时的对应关系为
易知其取值精度δ满足关系:
δ
=
(
U
−
L
)
/
(
2
k
−
1
)
δ=(U-L)/(2^k-1)
δ=(U−L)/(2k−1)
假设用长度为k的二进制编码表示该参数,编码为
x
:
b
k
b
(
k
−
1
)
b
(
k
−
2
)
b
(
k
−
3
)
…
b
2
b
1
x:b_k b_(k-1) b_(k-2) b_(k-3)…b_2 b_1
x:bkb(k−1)b(k−2)b(k−3)…b2b1,对应的解码公式为:
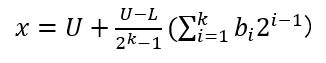
3.4 适应度函数
为了体现染色体的适应能力,区分种群中个体的好坏,遗传算法引入了对问题中的每个染色体都能进行度量的函数,即适应度函数。通过适应度函数来决定染色体的优劣程度,它体现了自然进化中的优胜劣汰原则。在简单问题的优化时,通常可以直接将目标函数换成适应度函数。在复杂问题的优化时,往往需要构造合适的评价函数,使其适应遗传算法进行优化。好的适应度函数能够真实反映优化的情况,找到问题真正的最优解,质量差的适应度函数可能是的优化后的解不可用。
3.5选择算子
选择算子体现了自然界中优胜劣汰的基本规律。个体的适应度值所度量的优劣程度决定了它在下一代是被淘汰还是被遗传,从而提高全局收敛性和计算效率。一般来说,如果该个体适应度函数值比较大,则它存在的概率也比较大。
通常采用的选择方法有:轮盘赌选择,竞争选择,随机遍历抽样选择,竞标赛选择等。其中最知名的为轮盘赌选择,其基本原理是:首先计算种群中个体的适应度值,然后计算该个体的适应度值在该种群中所占的比例,该比例就为该个体的选择概率或生存概率。
个体
x
i
x_i
xi的选择概率如下:
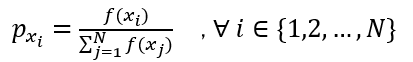
其中,
f
(
x
i
)
f(x_i)
f(xi)为个体的适应度值,N为种群的规模大小。根据这个概率分布选取N个个体产生下一代种群。
3.6 交叉算子
遗传算法的交叉操作,是指对两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体。
交叉算子体现了信息交换的思想。交叉又称为重组,是按较大的概率从种群中选择两个个体,交换两个个体的某个或某些位。其作用是组合出新的个体,在编码串空间进行有效搜索,同时降低对有效模式的破坏概率。交叉算子的设计包括如何确定交叉点的位置和如何交换两个方面,但在设计交叉算子时,需要保证前一代中有优秀个体的性状能够在后一代的新个体中尽可能得到遗传和继承。
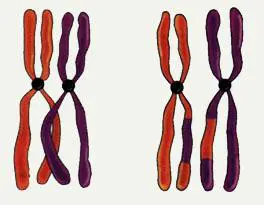
个体采用二进制编码时,常用的交叉算子有单点交叉,两点交叉和均匀交叉。
1,单点交叉(One-point Crossover):指在个体编码串中只随机设置一个交叉点,然后再该点相互交换两个配对个体的部分染色体。
2,两点交叉与多点交叉:
两点交叉(Two-point Crossover):在个体编码串中随机设置了两个交叉点,然后再进行部分基因交换。
多点交叉(Multi-point Crossover)
3,均匀交叉(也称一致交叉,Uniform Crossover):两个配对个体的每个基因座上的基因都以相同的交叉概率进行交换,从而形成两个新个体。

3.7 变异算子
变异算子是指从种群中随机选择一个个体,以变异概率对个体编码串上的某个或某些位置进行改变,经过变异后形成一个新的染色体。在遗传算法中,能够保持种群多样性的一个主要途径就是通过个体变异。
• 基本位变异(Simple Mutation):对个体编码串中以变异概率、随机指定的某一位或某几位仅因座上的值做变异运算。
• 均匀变异(Uniform Mutation):分别用符合某一范围内均匀分布的随机数,以某一较小的概率来替换个体编码串中各个基因座上的原有基因值。(特别适用于在算法的初级运行阶段)
• 边界变异(Boundary Mutation):随机的取基因座上的两个对应边界基因值之一去替代原有基因值。特别适用于最优点位于或接近于可行解的边界时的一类问题。
• 非均匀变异:对原有的基因值做一随机扰动,以扰动后的结果作为变异后的新基因值。对每个基因座都以相同的概率进行变异运算之后,相当于整个解向量在解空间中作了一次轻微的变动。
• 高斯近似变异:进行变异操作时用符号均值为P的平均值,方差为P**2的正态分布的一个随机数来替换原有的基因值。
四、问题求解
4.1 低维单目标优化问题
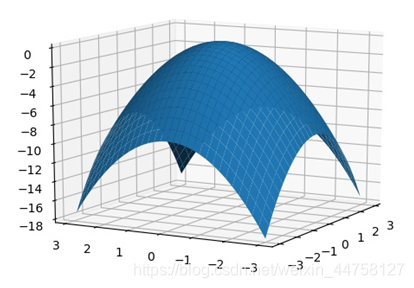
4.1.1 凸函数
求解函数f(x)的最大值,设置函数为
f
(
x
,
y
)
=
−
(
x
2
+
y
2
)
f(x,y)=-(x^2+y^2)
f(x,y)=−(x2+y2)
其函数图像如图所示,根据遗传算法求解其最大值。
设置编码长度为24,种群数量为200,交叉概率为0.8,变异概率为0.01。由于每一代都会产生一个最优得适应度值,迭代100代,得到其收敛曲线如图:

最终得到其在(0,0)处得最优解为0 。
4.1.2 非凸函数
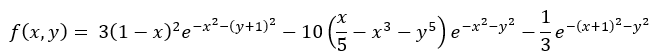
其图像如图所示
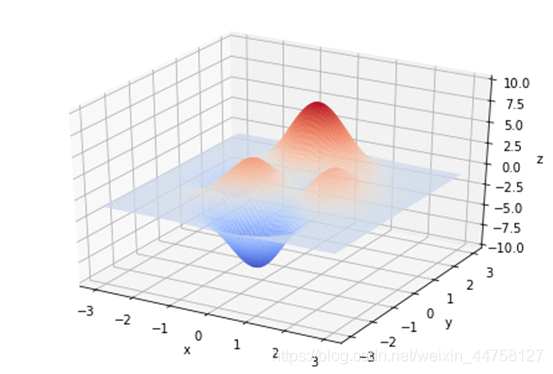
根据遗传算法求解得:

最优的基因型: [1 1 0 0 1 0 1 0 1 0 1 0 1 0 1 1 1 0 0 0 1 0 1 0 1 0 0 0 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 0 1 1 1 1]
(x, y): (0.023550332996268963, 1.4934538896950418)
得到其最大值为:0.026285520703649645
4.2 高维单目标优化问题
f
(
m
,
x
,
y
,
z
)
=
s
i
n
(
√
(
m
2
+
x
2
)
+
√
(
y
2
+
z
2
)
)
f(m,x,y,z)=sin(√(m^2+x^2 )+√(y^2+z^2 ))
f(m,x,y,z)=sin(√(m2+x2)+√(y2+z2))
其收敛过程为:
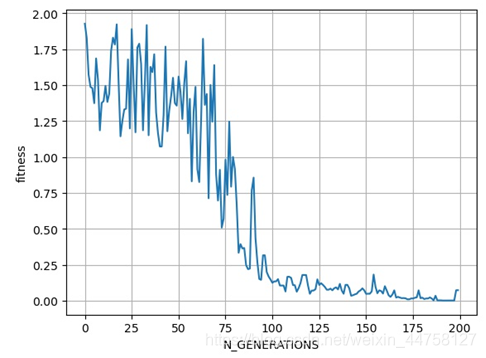
得到其在(x, y, m, z): (4.184986900388413, -2.2360853693536145, 3.0514268905774884, -1.4670375863932121)取得最优解0.0728843932140556。
4.3 TSP问题
旅行商问题,给定N个城市得坐标,商人随机选择其中一个城市开始旅行,要求为通过随给得所有城市且每个城市只能通过一次,求解如何安排才可以是的路径得长度最小。

由于给出的只是经纬度的数据,理论上应该根据具体的换算公式计算出实际距离,但是本题只是为了使用遗传算法,所以就直接根据经纬度的点来做的,并未做具体的转化。根据给出每个城市得坐标,得到城市的分布散点图如图:
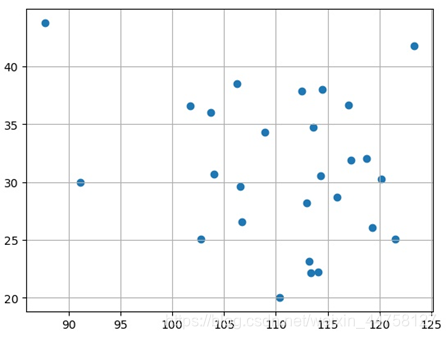
由于TSP问题与求解函数最优解不同,需要对各个城市进行编码,我们选择城市并对其进行顺序排列,每个城市都有一个序号代表,并对其序号进行二进制编码。
每两个城市之间都可以互通,两个城市之间的距离用两点之间的距离直接衡量,最后的总距离为整个路径总长,并以此为适应度值,由此问题转化为求解最小路径总和。
选择种群数为100,迭代次数为500,变异概率为0.1。
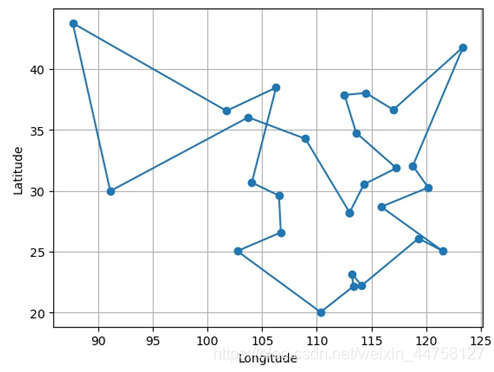
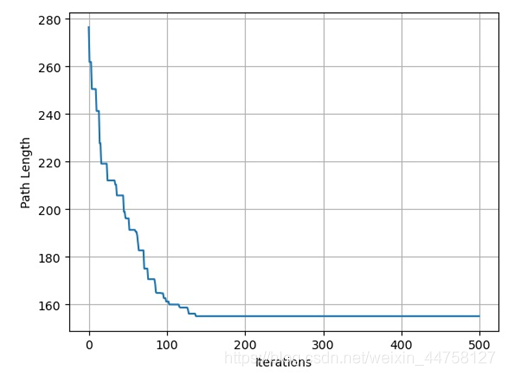
得到其路径为:[21, 20, 1, 2, 7, 3, 22, 0, 23, 24, 19, 26, 17, 25, 13, 18, 14, 12, 10, 4, 8, 5, 6, 9, 11, 16],路径总长为:155.0823114848274
五、结果分析
由遗传算法的原理及对三类问题的求解可以得知各个因素对结果的影响。
适应度函数是求解问题的关键,比如在求解TSP问题时,选择路径长度作为适应度函数,而在求解函数的最大值问题是则是直接以函数值作为适应度值,因此在求解实际问题时根据问题的特点设置适当的适应度函数可以使算法更快的收敛。
编码长度决定了种群数量的大小,如果编码长度为N,则这个种群的最大数量为2^N,而种群数量决定了之后的一系列遗传变异等操作,只有保持了种群数量足够多,才有可能产生交叉变异等操作,算法可以很快收敛,但是种群数量的增多会导致运算量上升。
交叉和变异是种群中个体更新的主要方式,由于很多问题的表示函数并不是简单的凸函数只有一个极值点,而是非凸函数,所以可能存在多个极值点,而大多数算法根据起始点的不同,很大概率只能找到局部最优点,而无法找到全局最优点,但是遗传算法根据交叉和变异,使得种群中随时可能产生新的个体,所以往往可以找到较优的结果。
六、遗传算法的拓展
虽然GA在许多优化问题中都有成功的应用 ,但其本身也存在一些不足 .例如局部搜索能力差、存在未成熟收敛和随机漫游等现象 ,从而导致算法的收敛性能差 ,需要很长时间才能找到最优解 ,这些不足阻碍了遗传算法的推广应用。
6.1 关于编码方式的改进
二进制编码不能直接反映问题的固有结构 ,精度不高 ,个体长度大 ,占用计算机内存多。
Gray编码是将二进制编码通过一个变换进行转换得到的编码 ,其目的就是克服 Hamming悬崖的缺点。
动态编码 (dynamic encoding)GA是当算法收敛到某局部最优时增加搜索的精度 ,从而使得在全局最优点附近可以进行更精确的搜索 ,增加精度的办法是在保持串长不变的前提下减小搜索区域。
对于问题的变量是实向量的情形 ,可以直接采用实数进行编码 ,这样可以直接在解的表现型上进行遗传操作 ,从而便于引入与问题领域相关的启发式信息以增加算法的搜索能力。
复数编码的GA是为了描述和解决二维问题 ,基因用 x+yi 表示 ;其还可以推广到多维问题的描述中。
多维实数编码,使无效交叉发生的可能性大大降低 ,同时其合理的编码长度也有助于算法在短时间内获得高精度的全局最优解。
在组合优化中 ,可以使用有序串编码 ,例如VRP问题。
当问题的表示是树和图时 ,我们还可以使用结构式编码。
6.2 关于选择策略的改进
轮盘赌法是使用最多的选择策略 ,但这种策略可能会产生较大的抽样误差 ,于是对此提出了很多的改进方法 ,如繁殖池选择,Boltzmann选择等等 .但是这几种策略都是基于适应值比例的选择 ,常常会出现早熟收敛现象和停滞现象。
非线性排名选择,这种选择不仅避免了上述问题 ,而且可以直接使用原始适应值进行排名选择 ,而不需对适应值进行标准化 ;但这种选择在群体规模很大时 ,其额外计算量 (如计算总体适应值和排序 )也相当可观 ,甚至在进行并行实现时有时要带来一些同步限制。
基于局部竞争机制的选择如
(
λ
+
μ
)
(λ+μ)
(λ+μ)选择,它使双亲和后代有同样的生存竞争机会在一定程度上避免了这些问题。
七、python代码
7.1 函数优化
import numpy as np
import matplotlib.pyplot as plt
DNA_SIZE = 24
POP_SIZE = 300 # 种群数量
CROSSOVER_RATE = 0.8 # 交叉概率
MUTATION_RATE = 0.01 # 变异概率
N_GENERATIONS = 200 # 迭代次数
X_BOUND = [-5, 5] # X的范围
Y_BOUND = [-5, 5] # Y的范围
# m_BOUND = [-5, 5]
# z_BOUND = [-5, 5]
# 定义函数
# def F(x, y, m, z):
# # f = np.sin(np.sqrt(x**2 + y**2))
# # f = -(x**2+y**2)
# f = np.sin(np.sqrt(m**2 + x**2)+np.sqrt(y**2 + z**2))
# return f
def F(x, y):
f = -(x**2+y**2)
return f
# 根据编码翻译为真实数据
def translateDNA(pop):
x_pop = pop[:, 1::2]
y_pop = pop[:, ::2]
# m_pop = pop[:, 2::4]
# z_pop = pop[:, 3::4]
x = x_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(X_BOUND[1]-X_BOUND[0])+X_BOUND[0]
y = y_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(Y_BOUND[1]-Y_BOUND[0])+Y_BOUND[0]
# m = m_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(m_BOUND[1]-m_BOUND[0])+m_BOUND[0]
# z = z_pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*(z_BOUND[1]-z_BOUND[0])+z_BOUND[0]
return x, y, m, z
# 计算适应度值
def get_fitness(pop):
x, y = translateDNA(pop)
# x, y, m, z =translateDNA(pop)
pred = F(x, y)
return (pred - np.min(pred))
# 交叉和变异
def crossover_and_mutation(pop, CROSSOVER_RATE = 0.8):
new_pop = []
for father in pop: # 遍历种群中的每一个个体,将该个体作为父亲
child = father
if np.random.rand() < CROSSOVER_RATE:
mother = pop[np.random.randint(POP_SIZE)]
cross_points = np.random.randint(low=0, high=DNA_SIZE*2)
child[cross_points:] = mother[cross_points:]
mutation(child)
new_pop.append(child)
return new_pop
# 变异
def mutation(child, MUTATION_RATE=0.003):
if np.random.rand() < MUTATION_RATE:
mutate_point = np.random.randint(0, DNA_SIZE)
child[mutate_point] = child[mutate_point]^1
# 选择
def select(pop, fitness):
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True, p=(fitness)/(fitness.sum()) )
return pop[idx]
def print_info(pop):
fitness = get_fitness(pop)
max_fitness_index = np.argmax(fitness)
print("max_fitness:", fitness[max_fitness_index])
x, y = translateDNA(pop)
# x, y, m, z = translateDNA(pop)
print("最优的基因型:", pop[max_fitness_index])
print("(x, y):", (x[max_fitness_index], y[max_fitness_index]))
# print("(x, y, m, z):", (x[max_fitness_index], y[max_fitness_index], m[max_fitness_index], z[max_fitness_index]))
if __name__ == "__main__":
pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE*2))
fitness_record = []
for _ in range(N_GENERATIONS): # 迭代N代
x, y = translateDNA(pop)
# x, y, m, z = translateDNA(pop)
pop = np.array(crossover_and_mutation(pop, CROSSOVER_RATE))
fitness = get_fitness(pop)
pop = select(pop, fitness) # 选择生成新的种群
fitness = get_fitness(pop)
max_fitness_index = np.argmax(fitness)
fitness_record.append(fitness[max_fitness_index]) # 记录每一代的最优值
print_info(pop)
# 画出适应度值得变化函数
plt.figure(1)
axis_x = [i for i in range(len(fitness_record))]
plt.plot(axis_x, fitness_record)
plt.grid()
plt.xlabel('N_GENERATIONS')
plt.ylabel('fitness')
plt.show()
# 画出函数图像,只能可视化低维函数
# fig = plt.figure(2)
# ax = fig.gca(projection='3d')
# x = np.arange(-5, 5, 0.1)
# y = np.arange(-5, 5, 0.1)
# x, y =np.meshgrid(x, y)
# # z = -(x**2+y**2)
# z = np.sin(np.sqrt(x ** 2 + y ** 2))
# surf = ax.plot_surface(x, y, z)
# plt.show()
7.2 TSP
import numpy as np
import matplotlib.pyplot as plt
import math
import random
# 载入数据
city_condition=[[106.54,29.59],
[91.11,29.97],
[87.68,43.77],
[106.27,38.47],
[123.38,41.8],
[114.48,38.03],
[112.53,37.87],
[101.74,36.56],
[117,36.65],
[113.6,34.76],
[118.78,32.04],
[117.27,31.86],
[120.19,30.26],
[119.3,26.08],
[115.89,28.68],
[113,28.21],
[114.31,30.52],
[113.23,23.16],
[121.5,25.05],
[110.35,20.02],
[103.73,36.03],
[108.95,34.27],
[104.06,30.67],
[106.71,26.57],
[102.73,25.04],
[114.1,22.2],
[113.33,22.13]]
city_condition = np.array(city_condition)
# 展示地图
plt.figure(1)
plt.scatter(city_condition[:, 0], city_condition[:, 1])
plt.grid()
plt.show()
# 距离矩阵
city_count = len(city_condition)
Distance = np.zeros([city_count, city_count])
for i in range(city_count):
for j in range(city_count):
Distance[i][j] = math.sqrt((city_condition[i][0]-city_condition[j][0])**2+(city_condition[i][1]-city_condition[j][1])**2)
count = 100 # 种群数
improve_count = 100 # 改良次数
itter_time = 500 # 进化次数
retain_rate = 0.3 # 设置强者的定义概率,即种群前30%为强者
random_select_rate = 0.5 # 设置弱者的存活概率
mutation_rate = 0.1 # 变异率
origin = 15 # 设置起点
index = [i for i in range(city_count)]
index.remove(15)
# 总距离
def get_total_distance(x):
distance = 0
distance += Distance[origin][x[0]]
for i in range(len(x)):
if i == len(x)-1:
distance += Distance[origin][x[i]]
else:
distance += Distance[x[i]][x[i+1]]
return distance
def improve(x):
i = 0
distance = get_total_distance(x)
while i<improve_count:
u=random.randint(0,len(x)-1)
v = random.randint(0, len(x)-1)
if u!=v:
new_x=x.copy()
t=new_x[u]
new_x[u]=new_x[v]
new_x[v]=t
new_distance=get_total_distance(new_x)
if new_distance<distance:
distance=new_distance
x=new_x.copy()
else:
continue
i+=1
# 自然选择
def selection(population):
# 对总距离从小到大进行排序
graded = [[get_total_distance(x), x] for x in population]
graded = [x[1] for x in sorted(graded)]
# 选出适应性强的染色体
retain_length = int(len(graded) * retain_rate)
parents = graded[:retain_length]
# 选出适应性不强,但是幸存的染色体
for chromosome in graded[retain_length:]:
if random.random() < random_select_rate:
parents.append(chromosome)
return parents
# 交叉繁殖
def crossover(parents):
# 生成子代的个数,以此保证种群稳定
target_count = count - len(parents)
# 孩子列表
children = []
while len(children) < target_count:
male_index = random.randint(0, len(parents) - 1)
female_index = random.randint(0, len(parents) - 1)
if male_index != female_index:
male = parents[male_index]
female = parents[female_index]
left = random.randint(0, len(male) - 2)
right = random.randint(left + 1, len(male) - 1)
# 交叉片段
gene1 = male[left:right]
gene2 = female[left:right]
child1_c = male[right:] + male[:right]
child2_c = female[right:] + female[:right]
child1 = child1_c.copy()
child2 = child2_c.copy()
for o in gene2:
child1_c.remove(o)
for o in gene1:
child2_c.remove(o)
child1[left:right] = gene2
child2[left:right] = gene1
child1[right:] = child1_c[0:len(child1) - right]
child1[:left] = child1_c[len(child1) - right:]
child2[right:] = child2_c[0:len(child1) - right]
child2[:left] = child2_c[len(child1) - right:]
children.append(child1)
children.append(child2)
return children
# 变异
def mutation(children):
for i in range(len(children)):
if random.random() < mutation_rate:
child = children[i]
u = random.randint(1,len(child)-4)
v = random.randint(u+1, len(child)-3)
w = random.randint(v+1, len(child)-2)
child = children[i]
child = child[0:u]+child[v:w]+child[u:v]+child[w:]
# 得到最佳纯输出结果
def get_result(population):
graded = [[get_total_distance(x), x] for x in population]
graded = sorted(graded)
return graded[0][0], graded[0][1]
#初始化种群
population = []
for i in range(count):
# 随机生成个体
x = index.copy()
random.shuffle(x)
improve(x)
population.append(x)
register = []
i = 0
distance, result_path = get_result(population)
while i < itter_time:
parents = selection(population) # 选择繁殖个体群
children = crossover(parents) # 交叉繁殖
mutation(children) # 变异操作
population = parents + children # 更新种群
distance, result_path = get_result(population)
register.append(distance)
i = i + 1
print(distance)
print(result_path)
result_path = [origin] + result_path + [origin]
X = []
Y = []
for index in result_path:
X.append(city_condition[index, 0])
Y.append(city_condition[index, 1])
plt.figure(2)
plt.plot(X, Y, '-o')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.grid()
plt.show()
plt.figure(3)
plt.plot(list(range(len(register))), register)
plt.xlabel('Iterations')
plt.ylabel('Path Length')
plt.grid()
plt.show()














 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









