







 本文通过对电信客户数据的分析,探讨了流失客户特征,包括合同类型、互联网服务、付款方式等,发现签订长期合同、使用电子支付、开通互联网服务的客户流失率更低。使用特征工程和多种模型(如逻辑回归、决策树、随机森林)进行预测,模型预测准确性超过80%。建议针对老年用户、无亲属用户推出定制服务,强化安全服务推广,优化支付方式以降低用户流失。
本文通过对电信客户数据的分析,探讨了流失客户特征,包括合同类型、互联网服务、付款方式等,发现签订长期合同、使用电子支付、开通互联网服务的客户流失率更低。使用特征工程和多种模型(如逻辑回归、决策树、随机森林)进行预测,模型预测准确性超过80%。建议针对老年用户、无亲属用户推出定制服务,强化安全服务推广,优化支付方式以降低用户流失。
研究背景
用户流失率的下降能够提高公司利润,了解用户倾向有利于提高用户黏性,延长用户生命周期。面对如今高昂的获客成本,也可以相对地降低营销投入,做到精准营销。
提出问题
1、流失客户有哪些显著性特征?
2、尝试找到合适的模型预测流失用户
3、针对性给出增加用户黏性、预防流失的建议
数据集描述
数据集来自DataFountain,该数据集有21个变量,7043个数据点,每条记录包含了唯一客户的特征。
用户属性
customerID :用户ID。
gender:性别。(Female & Male)
SeniorCitizen :老年人 (1表示是,0表示不是)
Partner :是否有配偶 (Yes or No)
Dependents :是否有家属 (Yes or No)
tenure :客户存留时长(0-72个月)
服务需求
PhoneService :是否开通电话服务业务 (Yes or No)
MultipleLines:是否开通了多线业务(Yes 、No or No phoneservice 三种)
InternetService:是否开通互联网服务 (No, DSL数字网络,fiber optic光纤网络 三种)
OnlineSecurity:是否开通网络安全服务(Yes,No,No internetserive 三种)
OnlineBackup:是否开通在线备份业务(Yes,No,No internetserive 三种)
DeviceProtection:是否开通了设备保护业务(Yes,No,No internetserive 三种)
TechSupport:是否开通了技术支持服务(Yes,No,No internetserive 三种)
StreamingTV:是否开通网络电视(Yes,No,No internetserive 三种)
StreamingMovies:是否开通网络电影(Yes,No,No internetserive 三种)
交易倾向
Contract:签订合同方式 (按月,一年,两年)
PaperlessBilling:是否开通电子账单(Yes or No)
PaymentMethod:付款方式(bank transfer,credit card,electronic check,mailed check)
MonthlyCharges:月费用
TotalCharges:总费用
研究对象
Churn:该用户是否流失(Yes or No)
#导入数据集
options(scipen = 200)
df <- read.csv("F:/telco-customer-churn/WA_Fn-UseC_-Telco-Customer-Churn.csv")`
特征工程
1、数据预处理
1.1、特征类型处理
#SeniorCitizen转换为因子变量
df <- within(df,{
SeniorCitizen <- factor(SeniorCitizen,levels = c(0,1),labels = c("No","Yes"))
})
1.2、缺失值处理
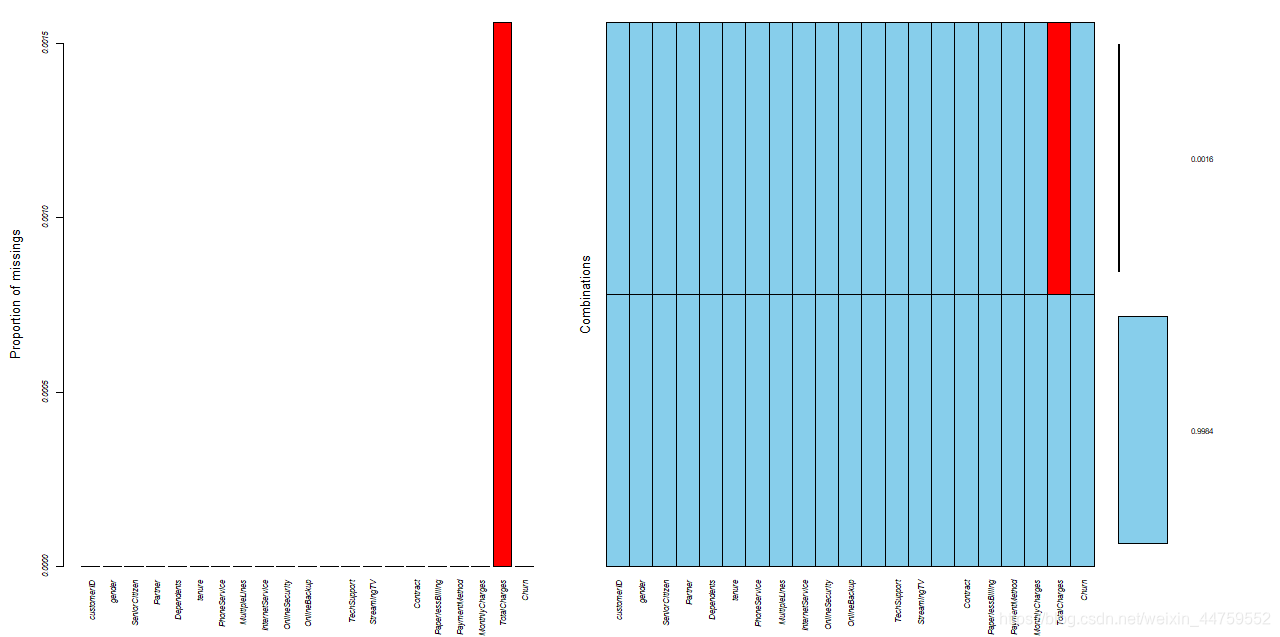
colSums(is.na(df))
mean(is.na(df$TotalCharges))
library(VIM)
opar <- par(no.readonly = T)
par(cex=0.72,font.axis=3)
aggr(df,prop=T,numbers=T)
par(opar)
#只有TotalCharges列有11个缺失值,占比大约0.156%

hist(df$TotalCharges,breaks = 50,prob=T,main = "histogram of TotalCharges")
df$TotalCharges[is.na(df$TotalCharges)] <- median(df$TotalCharges,na.rm = T)
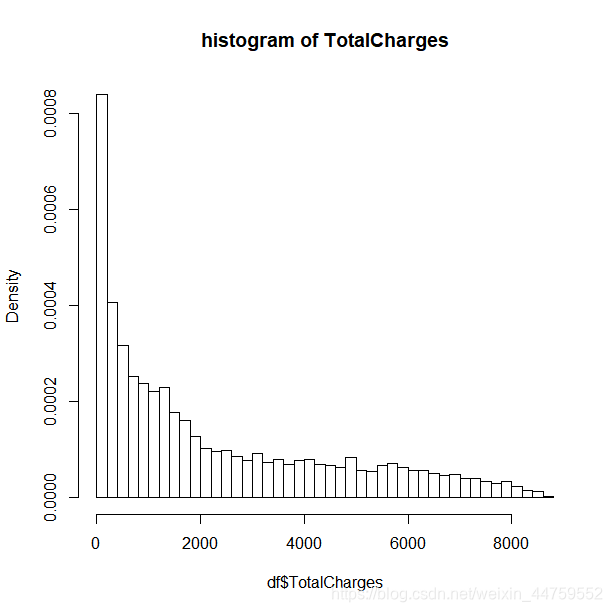
TotalCharges是数值型数据,从直方图可以看到该列数据是偏态分布。根据正态分布选均值、中位数填充,偏态分布选中位数填充的原则,我选择用TotalCharges列的中位数去填充这11个缺失值。
1.3、异常值处理
layout(matrix(c(1,2),1,2,byrow = T))
boxplot(df$MonthlyCharges,xlab="MonthlyCharges")
boxplot(df$TotalCharges,xlab="TotalCharges")
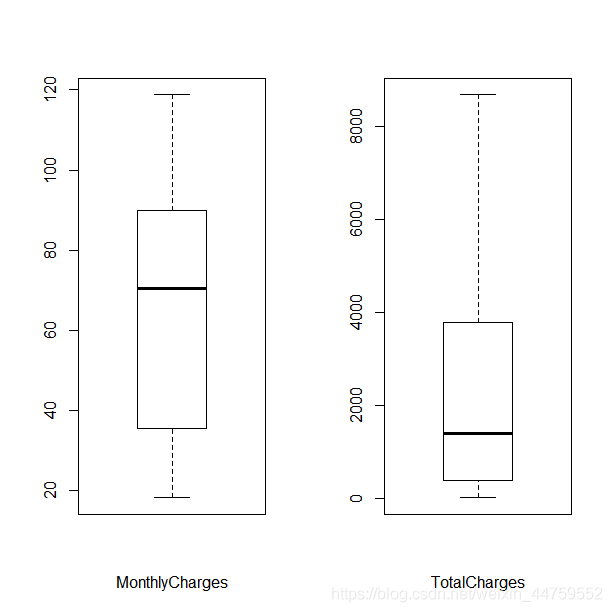
通过箱线图可以看到MonthlyCharges、TotalCharges两个特征无极端异常值,但总费用量纲差异大,对特征进行分箱离散化处理
library(Hmisc)
describe(df[c("MonthlyCharges","TotalCharges")])
#根据描述性统计量将变量按0.25,0.5,0.75分位数分成4份
c_u_t <- function(x,n=1) {
result <- quantile(x,probs = seq(0,1,1/n))
result[1] <- result[1]-0.001
return(result)
}
df <- transform(df,
MonthlyCharges_c = cut(df$MonthlyCharges,
breaks = c_u_t(df$MonthlyCharges,n=4),labels = c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6999
6999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









