







from sklearn.feature_extraction.text import CountVectorizer
import jieba
"""
单词 作为 特征
句子、短语、单词、字母
特征: 特征词
方法1:CountVectorizer(stop_words[]) # stop_words[] 停用词表 不需要统计的特征词放进列表里
"""
def count_demo1():
data = ["life is short ,i like like python", "life is too long, i dislike python"]
transfer = CountVectorizer()
data_new = transfer.fit_transform(data)
print(transfer.get_feature_names()) # 统计每个样本特征词出现的个数
print(data_new.toarray())
return None
def cut_word(text):
"""
进行中文分词: "我爱北京天安门" -> "我 爱 北京 天安门"
:param string:
:return:
"""
return " ".join(list(jieba.cut(text)))
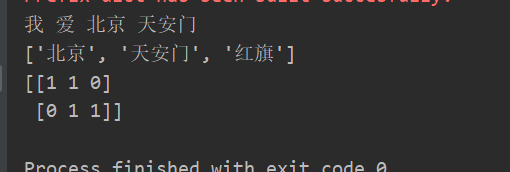
def count_demo2():
data = ["我爱北京天安门", "天安门上红旗升"] # 因为中文没有空格,直接转换是短句,需要分词
# jieba分词
for i in range(len(data)):
data[i] = cut_word(data[i]) # 迭代分词
transfer = CountVectorizer()
data_new = transfer.fit_transform(data)
print(transfer.get_feature_names()) # 统计每个样本特征词出现的个数
print(data_new.toarray())
return None
if __name__ == '__main__':
# count_demo1()
print(cut_word("我爱北京天安门"))
count_demo2()
运用 jieba 分词来提取















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









