






本节主要介绍皮尔逊pearson相关系数和斯皮尔曼spearman等级相关系数,根据数据条件选择不同的相关系数进行研究。
1.总体和样本
举个例子,考察一批草莓的质量,通过草莓颜色、口感、大小等指标来衡量,由于测量本身对草莓的包装和质量都有破坏性,影响售卖,所以我们往往抽取部分草莓进行测量,用部分草莓的检测数据来确定这批草莓的质量。
所要考察对象的全部个体叫做总体,在这个例子中,我们把这批草莓的大小叫做总体数据。每个研究对象叫个体,每个草莓的大小叫做个体数据。从总体中所抽取的n个体构成的向量叫做总体的一个样本。这三个基本概念是我们入门数理统计学必学的,数理统计学主要任务就是用样本来推断总体,用有效的方法去收集和分析数据以对某个研究问题作出结论。在实际中,我们计算这些抽取的样本的统计量来估计总体的统计量: 例如使用样本均值、样本标准差来估计总体的均值和总体的标准差。
2.皮尔逊pearson相关系数
2.1总体皮尔逊pearson相关系数
有两组数据,和
是总体数据,
总体协方差:
协方差:X的偏差与Y的偏差乘积的数学期望,如果X、Y变化方向相同,即当X大于(小于)其均值时,Y也大于(小于)其均值,在这两种情况下,乘积为正。如果X、Y的变化方向一直保持相同,则协方差为正;同理,如果X、Y变化方向一直相反,则协方差为负; 如果X、Y变化方向之间相互无规律,即分子中有的项为正,有的项为负,那么累加后正负抵消。注意:协方差的大小和两个变量的量纲有关,因此不适合直接拿来做比较。
为了克服这一缺点,在计算协方差之前将X、Y进行标准化处理,消除量纲的影响。
,
再计算和
的协方差,即总体pearson相关系数
2.2皮尔逊pearson相关系数性质
(1)
(2)充要条件是P{Y=aX+b}=1,其中a、b为常数,且a不为0
(3)是刻画随机变量X和Y之间的线性相关程度
(4)随机变量X和Y相互独立则一定不相关,但是不相关的两个变量未必相互独立。
2.3样本皮尔逊pearson相关系数
样本协方差:
样本pearson相关系数:,其中,
是样本方差。
3.相关性可视化:绘制散点图
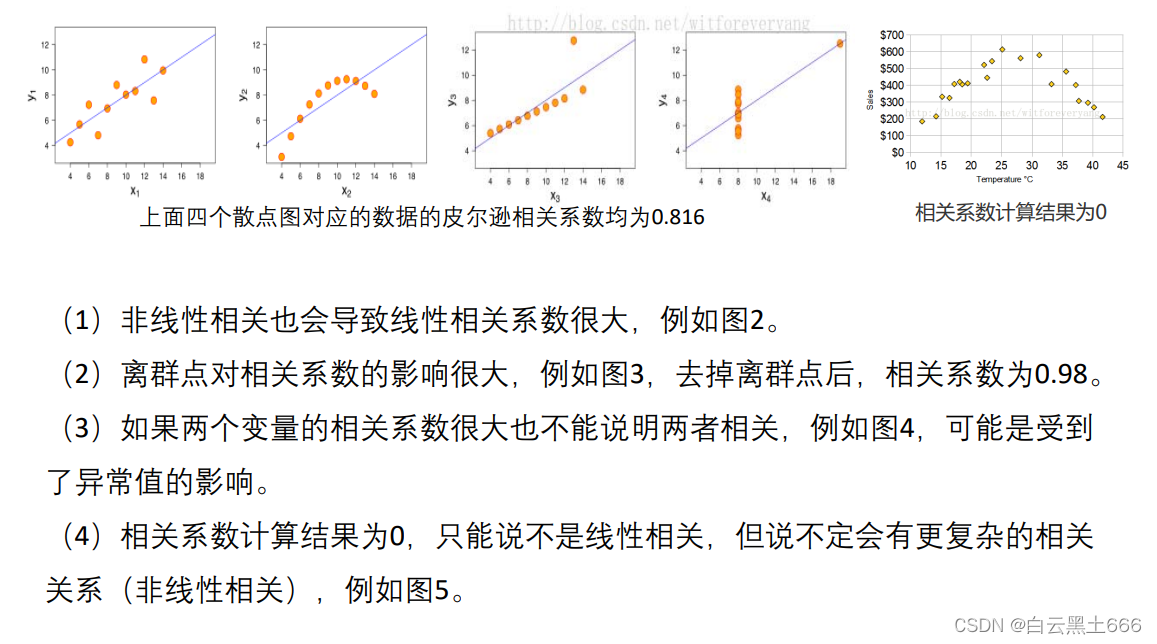
注意:1)如果两个变量本身就是线性的关系, 那么皮尔逊相关系数绝对值大的就是相关性 强,小的就是相关性弱(2)在不确定两个变量是什么关系的情况 下,即使算出皮尔逊相关系数发现很大,也不能说明那两个变量线性相关,甚至不能说他们相关我们一定要画出散点图来看才行。
4.皮尔逊相关系数进行假设检验
(1)提出原假设和备择假设 :
:
(2)在原假设成立的条件下,构造一个符合某一分布的检验统计量,服从自由度为n-2的t分布。
(3)根据样本观测值计算检验统计量
(4)根据显著性水平确定临界值,检验统计量的接受域和拒绝域
(5)作出统计决策
此外,通过P值判断法更加简单,当我们算出检验值,根据这个值我们可以算出对应的概率P,当P<,拒绝原假设。
进行皮尔逊相关系数假设检验条件:
第一, 实验数据通常假设是成对的来自于正态分布的总体。因为我们在求皮尔逊相关性系数以后,通常还会用t检验之类的方法来进行皮尔逊相关性系数检验, 而t检验是基于数据呈正态分布的假设的。
第二, 实验数据之间的差距不能太大。皮尔逊相关性系数受异常值的影响比较 大。
第三:每组样本之间是独立抽样的。构造t统计量时需要用到。
5.检验数据正态分布的方法
5.1正态分布JB检验(大样本n>30)

5.2Shapiro-wilk检验 夏皮洛‐威尔克检验(小样本3≤n≤50)

5.3Q-Q图

6.斯皮尔曼相关系数
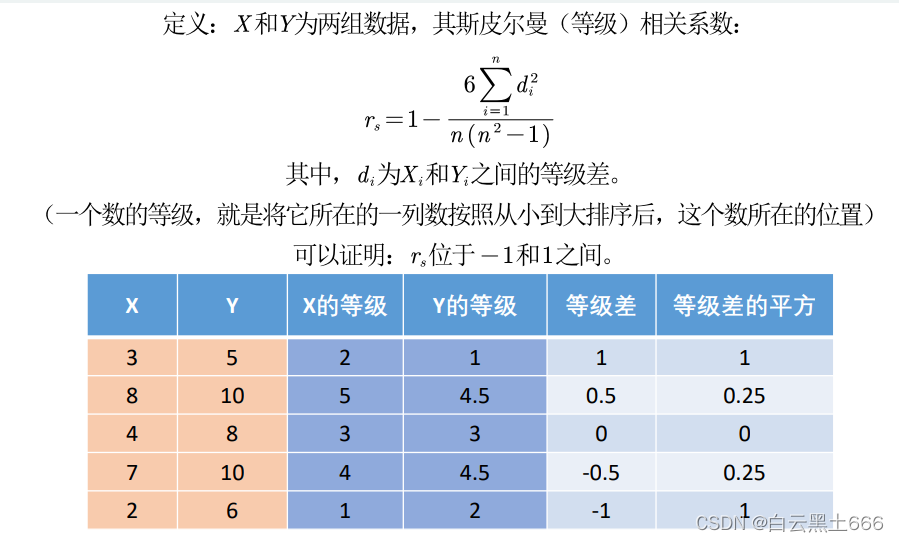
注:如果有的数值相同,则将它们所在的位置取算术平均。
斯皮尔曼相关系数假设检验:小样本查临界值表,大样本求出检验值和对应p值
% 直接给出相关系数和p值
[R,P]=corr(Test, 'type' , 'Spearman')7.总结:两个相关系数的比较
1.连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用 spearman相关系数也可以, 就是效率没有pearson相关系数高。
2.上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
3.两个定序数据之间也用spearman相关系数,不能用pearson相关系数
4.斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系 (例如线性函数、指数函数、对数函数等)就能够使用。
8.案例实践
以《现有某中学八年级所有女学生的体测样本数据》为例,
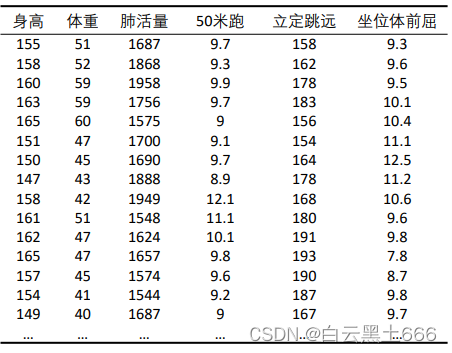
8.1矩阵散点图:先看看两组变量是否线性相关
这里使用SPSS比较方便,图形 ‐ 旧对话框 ‐ 散点图/点图 ‐ 矩阵散点图-插入总计拟合线

8.2皮尔逊相关系数计算
使用matlab计算,首先新建变量,把excel数据导入matlab,此时生成矩阵,重命名为test。这样以后需要数据就可以直接编写matlab代码导入数据
>> load('C:\Users\TQZY-JCKB\Desktop\matlab过程\matlab.mat')计算相关系数函数corrcoef,R = corrcoef(A,B)返回两个随机变量A、B(两个向量)之间的相关系数。本例中我们计算6个变量的线性相关关系,
>> R=corrcoef(test)R =
1.0000 0.0665 -0.2177 -0.1920 0.0440 0.0951
0.0665 1.0000 0.0954 0.0685 0.0279 -0.0161
-0.2177 0.0954 1.0000 0.2898 0.0248 -0.0749
-0.1920 0.0685 0.2898 1.0000 -0.0587 -0.0019
0.0440 0.0279 0.0248 -0.0587 1.0000 -0.0174
0.0951 -0.0161 -0.0749 -0.0019 -0.0174 1.0000
注意:在matlab中得到的结果可以在excel、R语言、Python中继续美化
8.3皮尔逊相关系数假设检验
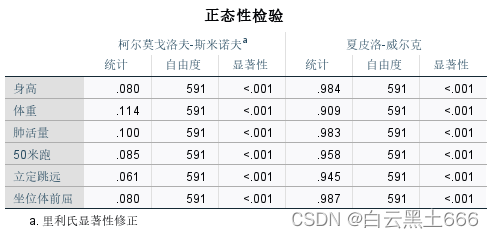
8.3.1正态检验
(1)SPSS-描述统计-探索-图-含检验的正太图,样本量小于50,一般倾向于S-W(夏皮洛-威尔克)检验结果;样本量大于50,倾向于K-S检验。
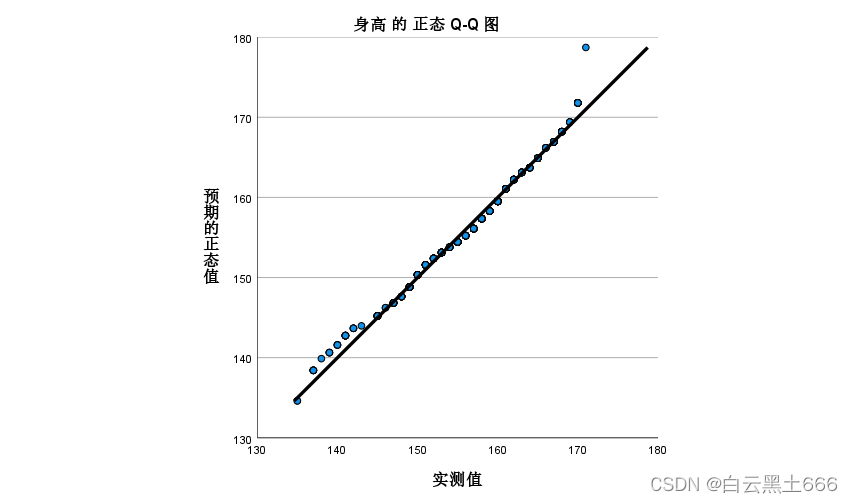
(2)Q-Q图,以身高数据为例,SPSS-分析-描述统计-Q-Q图,Q-Q图将实际数据作为X轴,将对应正态分布分位数作为Y轴,作散点图,反映变量的实际分布与理论分布的符合程度。根据身高正态Q-Q图看到,散点图上的数值似乎接近与直线很接近。
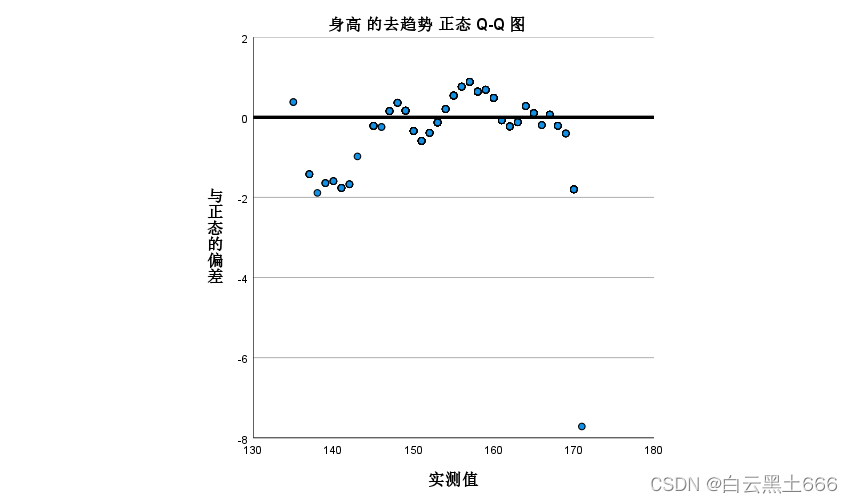
去趋势正态Q-Q图看到,实测值与正态的偏差还是比较大的,因此,不能确切说明身高样本数据服从正态分布。
下面的代码是在matlab中取矩阵的第一列绘制Q-Q图
>> qqplot(test(:,1))(3) J-B检验matlab运行代码
MATLAB中进行JB检验的语法:[h,p] = jbtest(x,alpha) 当输出h等于1时,表示拒绝原假设;h等于0则代表不能拒绝原假设。alpha就是显著性水平,一般取0.05,此时置信水平为1‐0.05=0.95 x就是我们要检验的随机变量,注意这里的x只能是向量
%%正太分布检验,检验第一列数据是否正态分布
>> [h,p]=jbtest(test(:,1),0.05)运行结果,h=1,p=0.0110, p<0.05,所以拒绝原假设,第一列数据不从正态分布。
8.3.2显著性检验
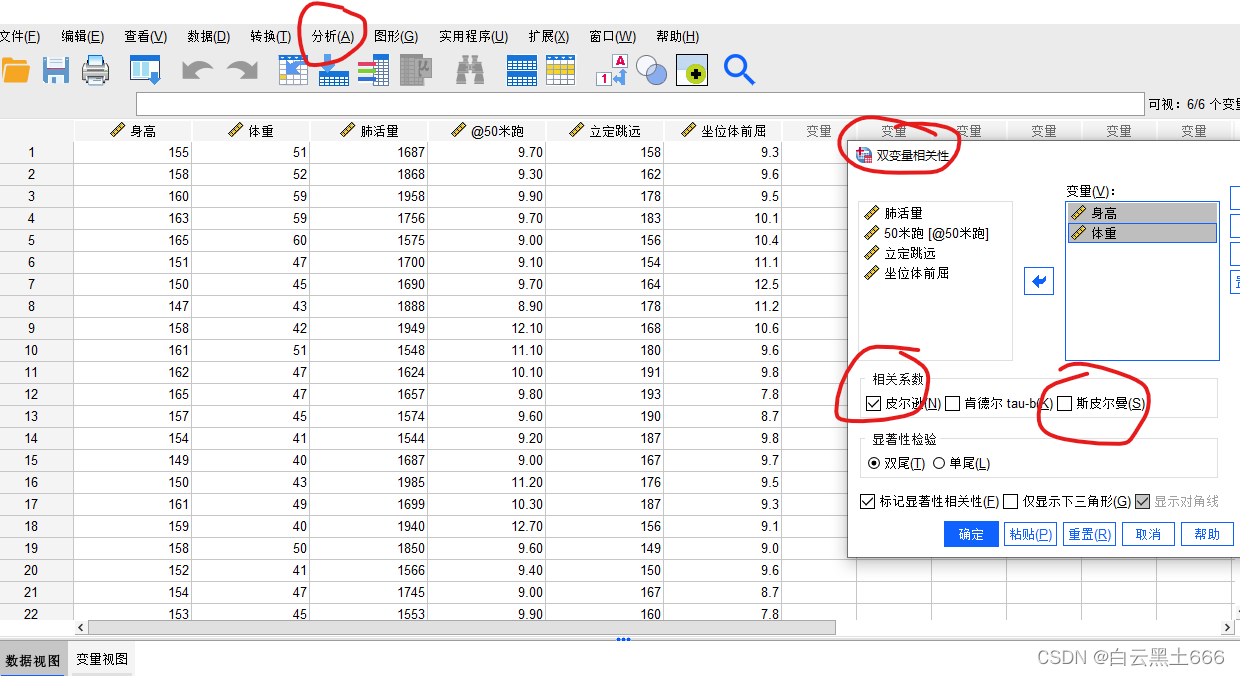
(1)SPSS-分析-相关-双变量
(2) matlab代码
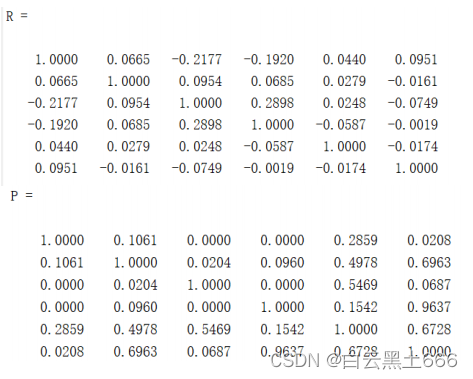
%%R是返回相关系数表,P是返回对应每个相关系数的P值,下面计算各列之间相关系数及P值
>> [R,P]=corrcoef(test)
8.4斯皮尔曼相关系数
%%X、Y列向量
>> X=[3,8,4,7,2]'
>> Y=[5 10 9 10 6]'
%%斯皮尔曼相关系数
>> coeff = corr(X , Y , 'type' , 'Spearman')
%%皮尔逊相关系数
>> r=corrcoef(X,Y)

















 3358
3358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









