









简单方便的 nn.DataParallel
DataParallel 可以帮助我们(使用单进程控)将模型和数据加载到多个 GPU 中,控制数据在 GPU 之间的流动,协同不同 GPU 上的模型进行并行训练(细粒度的方法有 scatter,gather 等等)。
DataParallel 使用起来非常方便,我们只需要用 DataParallel 包装模型,再设置一些参数即可。需要定义的参数包括:参与训练的 GPU 有哪些,device_ids=gpus;用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总:
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
值得注意的是,模型和数据都需要先 load 进 GPU 中,DataParallel 的 module 才能对其进行处理,否则会报错:
# 这里要 model.cuda()
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
# 这里要 images/target.cuda()
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
汇总一下,DataParallel 并行训练部分主要与如下代码段有关:
# main.py
import torch
import torch.distributed as dist
gpus = [0, 1, 2, 3]
torch.cuda.set_device('cuda:{}'.format(gpus[0]))
train_dataset = ...
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=...)
model = ...
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
在使用时,使用 python 执行即可:
python main.py
使用 torch.distributed 加速并行训练
在 pytorch 1.0 之后,官方终于对分布式的常用方法进行了封装,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题,目前已经很成熟了~
与 DataParallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,我们只需要编写一份代码,torch 就会自动将其分配给 n个进程,分别在n个 GPU 上运行。
在 API 层面,pytorch 为我们提供了 torch.distributed.launch 启动器,用于在命令行分布式地执行 python 文件。在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 通过参数传递给 python,我们可以这样获得当前进程的 index:
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
print(args.local_rank)
接着,使用 init_process_group 设置GPU 之间通信使用的后端和端口:
dist.init_process_group(backend='nccl')
之后,使用 DistributedSampler 对数据集进行划分。如此前我们介绍的那样,它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
然后,使用 DistributedDataParallel 包装模型,它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
最后,把数据和模型加载到当前进程使用的 GPU 中,正常进行正反向传播:
torch.cuda.set_device(args.local_rank)
model.cuda()
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
汇总一下,torch.distributed 并行训练部分主要与如下代码段有关:
# main.py
import torch
import argparse
import torch.distributed as dist
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
在使用时,调用 torch.distributed.launch 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
(1)torch.distributed.launch相关的环境变量
- torch.ditributed.launch参数解析:
nnodes: 表示有多少个节点,可以通俗的理解为有多少台机器,比如,–nnodes=2,是指有两个节点(即两台机器)参与训练
nproc_per_node: 表示每个节点上有多少个进程,每个进程一般独占一块GPU,但是这并不绝对,要看具体的实现;
node_rank: 指节点的编号,比如上例中在机器A上启动时,–node_rank=0,
指A机器的节点编号是0;在机器B上启动时,–node_rank=1,指B机器上的节点编号是1
master_addr:master节点的ip地址
master_port:master节点的port号,在不同的节点上master_addr和master_port的设置是一样的,用来进行通信
- torch.ditributed.launch相关环境变量解析:
WORLD_SIZE: 通俗的解释下,就是一共有多少个进程参与训练,WORLD_SIZE =nproc_per_node*nnodes,不同的进程中,WORLD_SIZE是唯一的;
RANK:进程的唯一表示符,不同的进程中,这个值是不同的,上述在AB两台机器上共启动了8个进程,则不同进程的RANK号是不同的
LOCAL_RANK:同一节点下,LOCAL_RANK是不同的,常根据LOCAL_RANK来指定GPU,但GPU跟LOCAL_RANK不一定一一对应,因为进程不一定被限制在同一块GPU上。
试验train.py
import torch
import torch.distributed as dist
import os
import time
print(os.environ)
dist.init_process_group('nccl')
time.sleep(30)
dist.destroy_process_group()
在A机器上调用如下命令python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 0 --master_addr='10.100.37.21' --master_port='29500' train.py, 在B机器上调用如下命令python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 1 --master_addr='10.100.37.21', --master_port='29500' train.py
机器A的显示信息如下:
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 0 --master_addr='10.100.37.21' --master_port='29500' train1.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
environ({'XDG_SESSION_ID': '40164', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51550 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'OLDPWD': '/home/zhangwd', 'SSH_TTY': '/dev/pts/80', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/usr/local/cuda/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd/code/demo/self-supervised/pytorch_dist', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51550 10.100.37.21 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1013', 'DISPLAY': 'localhost:11.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '0', 'LOCAL_RANK': '0'})
environ({'XDG_SESSION_ID': '40164', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51550 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'OLDPWD': '/home/zhangwd', 'SSH_TTY': '/dev/pts/80', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/usr/local/cuda/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd/code/demo/self-supervised/pytorch_dist', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51550 10.100.37.21 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1013', 'DISPLAY': 'localhost:11.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '2', 'LOCAL_RANK': '2'})
environ({'XDG_SESSION_ID': '40164', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51550 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'OLDPWD': '/home/zhangwd', 'SSH_TTY': '/dev/pts/80', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/usr/local/cuda/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd/code/demo/self-supervised/pytorch_dist', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51550 10.100.37.21 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1013', 'DISPLAY': 'localhost:11.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '1', 'LOCAL_RANK': '1'})
environ({'XDG_SESSION_ID': '40164', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51550 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'OLDPWD': '/home/zhangwd', 'SSH_TTY': '/dev/pts/80', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/usr/local/cuda/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd/code/demo/self-supervised/pytorch_dist', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51550 10.100.37.21 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1013', 'DISPLAY': 'localhost:11.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '3', 'LOCAL_RANK': '3'})
机器B的显示信息如下:
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 1 --master_addr='10.100.37.21' --master_port='29500' train1.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
environ({'XDG_SESSION_ID': '4475', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51380 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'SSH_TTY': '/dev/pts/4', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', 'MKL_INTERFACE_LAYER': 'LP64,GNU', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_MKL_INTERFACE_LAYER_BACKUP': '', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51380 10.100.37.100 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1005', 'DISPLAY': 'localhost:12.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '4', 'LOCAL_RANK': '0'})
environ({'XDG_SESSION_ID': '4475', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51380 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'SSH_TTY': '/dev/pts/4', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', 'MKL_INTERFACE_LAYER': 'LP64,GNU', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_MKL_INTERFACE_LAYER_BACKUP': '', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51380 10.100.37.100 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1005', 'DISPLAY': 'localhost:12.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '7', 'LOCAL_RANK': '3'})
environ({'XDG_SESSION_ID': '4475', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51380 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'SSH_TTY': '/dev/pts/4', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', 'MKL_INTERFACE_LAYER': 'LP64,GNU', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_MKL_INTERFACE_LAYER_BACKUP': '', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51380 10.100.37.100 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1005', 'DISPLAY': 'localhost:12.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '5', 'LOCAL_RANK': '1'})
environ({'XDG_SESSION_ID': '4475', 'TERM': 'xterm', 'SHELL': '/bin/bash', 'SSH_CLIENT': '172.16.104.139 51380 22', 'CONDA_SHLVL': '2', 'CONDA_PROMPT_MODIFIER': '(pytorch1.8) ', 'SSH_TTY': '/dev/pts/4', 'http_proxy': 'http://172.16.17.164:3128', 'USER': 'zhangwd', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_EXE': '/home/zhangwd/anaconda3/bin/conda', 'MKL_INTERFACE_LAYER': 'LP64,GNU', '_CE_CONDA': '', 'CONDA_PREFIX_1': '/home/zhangwd/anaconda3', 'MAIL': '/var/mail/zhangwd', 'PATH': '/home/zhangwd/bin:/home/zhangwd/.local/bin:/home/zhangwd/anaconda3/envs/pytorch1.8/bin:/home/zhangwd/anaconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'CONDA_MKL_INTERFACE_LAYER_BACKUP': '', 'CONDA_PREFIX': '/home/zhangwd/anaconda3/envs/pytorch1.8', 'PWD': '/home/zhangwd', 'LANG': 'en_US.UTF-8', 'https_proxy': 'http://172.16.17.164:3128', '_CE_M': '', 'SHLVL': '1', 'HOME': '/home/zhangwd', 'LANGUAGE': 'en_US:en', 'CONDA_PYTHON_EXE': '/home/zhangwd/anaconda3/bin/python', 'LOGNAME': 'zhangwd', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '172.16.104.139 51380 10.100.37.100 22', 'CONDA_DEFAULT_ENV': 'pytorch1.8', 'LESSOPEN': '| /usr/bin/lesspipe %s', 'XDG_RUNTIME_DIR': '/run/user/1005', 'DISPLAY': 'localhost:12.0', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', '_': '/home/zhangwd/anaconda3/envs/pytorch1.8/bin/python', 'MASTER_ADDR': '10.100.37.21', 'MASTER_PORT': '29500', 'WORLD_SIZE': '8', 'OMP_NUM_THREADS': '1', 'RANK': '6', 'LOCAL_RANK': '2'})
环境变量中’MASTER_ADDR’: ‘10.100.37.21’, ‘MASTER_PORT’: ‘29500’, ‘WORLD_SIZE’: ‘8’, ‘OMP_NUM_THREADS’: ‘1’, ‘RANK’: ‘6’, ‘LOCAL_RANK’: ‘2’,是跟我们的分布式训练相关的几个变量。
(2) DistributedDataParallel是如何做同步的
- 在开始试验之前我们先说明
DataParallel,当我们使用DataParallel去做分布式训练时,假设我们使用四块显卡去做训练,数据的batch_size设置为8,则程序启动时只启动一个进程,每块卡会分配batch_size=2的资源进行forward操作,当4快卡的forward操作做完之后,主进程会收集所有显卡的结果进行loss运算和梯度回传以及参数更新,这些都在主进程中完成,也就是说主进程看到看到的forward运算的结果是batch_size=8的。 - 当我们用
DistributedDataParallel去做分布式训练时,假设我们使用4块显卡训练,总的batch_size设置为8,程序启动时会同时启动四个进程,每个进程会负责一块显卡,每块显卡对batch_size=2的数据进行forward操作,在每个进程中,程序都会进行的loss的运算、梯度回传以及参数更新, 与DataParallel的区别是,每个进程都会进行loss的计算、梯度回传以及参数更新。这里抛出我们的问题,既然每个进程都会进行loss计算与梯度回传是怎么保证模型训练的同步的呢?
试验:
- 数据类
datasets.py: 这个数据类随机生成224x224大小的图像和其对应的随机标签0-8
class RandomClsDS(Dataset):
def __init__(self):
pass
def __len__(self):
return 10000
def __getitem__(self, item):
image = torch.randn(3,224, 224)
label = np.random.randint(0,9)
return image, label
- 训练类train.py
import os
import sys
sys.path.append(os.path.join(os.path.dirname(__file__), os.path.pardir))
from datasets.datasets import XRrayDS, RandomClsDS
import torch
import torch.nn as nn
import torch.distributed as dist
import torchvision
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
def reduce_val(val):
world_size = dist.get_world_size()
with torch.no_grad():
dist.all_reduce(val, async_op=True)
val /= world_size
return val
local_rank = int(os.environ['LOCAL_RANK'])
world_size = int(os.environ['WORLD_SIZE'])
rank = int(os.environ['RANK'])
dist.init_process_group('nccl',world_size=world_size, rank=rank)
torch.cuda.set_device(local_rank)
train_ds = RandomClsDS()
train_dataloader = torch.utils.data.DataLoader(train_ds, batch_size=2, num_workers=1)
train_dataloader = tqdm(train_dataloader)
model = torchvision.models.resnet18(num_classes=9)
model = torch.nn.parallel.DistributedDataParallel(model.cuda(), device_ids=[local_rank], output_device=local_rank)
criterion = torch.nn.CrossEntropyLoss()
for index, (images, labels) in enumerate(train_dataloader):
if index > 1:
# print(model.module.fc.weight.grad[0][0])
pass
output = model(images.cuda())
loss = criterion(output, labels.long().cuda())
print(loss)
loss.backward()
loss = reduce_val(loss)
print(model.module.fc.weight.grad[0][0])
break
试验过程1
执行CUDA_VISIBLE_DEVICES=2,3,6,7 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' train.py命令,显示结果如下:
CUDA_VISIBLE_DEVICES=2,3,6,7 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' train.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor(2.5341, device='cuda:0', grad_fn=<NllLossBackward>)
tensor(2.0336, device='cuda:2', grad_fn=<NllLossBackward>)
tensor(2.3375, device='cuda:1', grad_fn=<NllLossBackward>)
tensor(2.5774, device='cuda:3', grad_fn=<NllLossBackward>)
tensor(-0.0832, device='cuda:2')
tensor(-0.0832, device='cuda:0')
tensor(-0.0832, device='cuda:3')
tensor(-0.0832, device='cuda:1')
解析:
试验中程序通过DistributedDataParallel并行启动了4个进程,过程中只象征性的计算了一次forward操作并针对结果计算了loss,结果如图
tensor(2.5341, device='cuda:0', grad_fn=<NllLossBackward>)
tensor(2.0336, device='cuda:2', grad_fn=<NllLossBackward>)
tensor(2.3375, device='cuda:1', grad_fn=<NllLossBackward>)
tensor(2.5774, device='cuda:3', grad_fn=<NllLossBackward>)
过程中,每个进程的loss都不相同,但是当做了loss.backward()操作时,4块显卡上的模型的梯度更新却是相同的,如图
tensor(-0.0832, device='cuda:2')
tensor(-0.0832, device='cuda:0')
tensor(-0.0832, device='cuda:3')
tensor(-0.0832, device='cuda:1')
猜测:DistributedDataParallel在做loss回传时,内部应该有同步机制,不同进程中的loss**会先计算完,然后内部可能做了reduce操作,然后回传计算更新梯度,这样也解释了4个进程中的loss是不同的,但是更新之后模型参数的梯度是相同的,然后调用优化器的参数更新步骤,那么每个进程中的模型在一次迭代后,参数的更新结果也是相同的。**上述的过程,我重复了很多遍会发现不同进程间loss的打印一定在grad的打印之前出现,猜测在loss.backward()操作的前或后应该有同步机制,个人猜测这个同步机制应该在loss.backward()中???,待求证。
试验过程2
上述的代码改为如下启动,即模拟在两个节点上(即两台机器上,本例中还是同一台机器)启动训练过程:
命令1: CUDA_VISIBLE_DEVICES=2,3 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' train.py
命令2: CUDA_VISIBLE_DEVICES=6,7 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=1 --master_addr='10.100.37.21' --master_port='29500' train.py
只启动命令1时,程序会被堵塞:
CUDA_VISIBLE_DEVICES=2,3 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' train.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
直到命令2同时启动时, 程序才能正常执行:
CUDA_VISIBLE_DEVICES=2,3 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' train.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor(1.9137, device='cuda:0', grad_fn=<NllLossBackward>)
tensor(2.3257, device='cuda:1', grad_fn=<NllLossBackward>)
tensor(0.0404, device='cuda:0')tensor(0.0404, device='cuda:1')
(3) 分布式训练时,torch.utils.data.distributed.DistributedSampler做了什么?
试验用到的code
import os
import sys
import torch
import torch.nn as nn
import torch.distributed as dist
import torchvision
from torch.utils.data import Dataset, DataLoader
import numpy as np
class InnerDS(Dataset):
def __init__(self, n=8):
self.n = n
def __len__(self):
return self.n
def __getitem__(self, item):
np_img = np.random.rand(3,224,224)
image = torch.from_numpy(np_img).float()
label = np.random.randint(0,9)
return image, label, item
local_rank = int(os.environ['LOCAL_RANK'])
world_size = int(os.environ['WORLD_SIZE'])
rank = int(os.environ['RANK'])
dist.init_process_group('nccl',world_size=world_size, rank=rank)
torch.cuda.set_device(local_rank)
# case 1
# ds = InnerDS(8)
# sampler = torch.utils.data.distributed.DistributedSampler(ds)
# dataloader = DataLoader(ds, batch_size=4, drop_last=True)
# case 2
# ds = InnerDS(8)
# sampler = torch.utils.data.distributed.DistributedSampler(ds)
# dataloader = DataLoader(ds, batch_size=4, sampler=sampler, drop_last=True)
# case 3
# ds = InnerDS(8)
# sampler = torch.utils.data.distributed.DistributedSampler(ds)
# dataloader = DataLoader(ds, batch_size=4, sampler=sampler, drop_last=True)
# case 4
# ds = InnerDS(6)
# sampler = torch.utils.data.distributed.DistributedSampler(ds)
# dataloader = DataLoader(ds, batch_size=4, sampler=sampler, drop_last=False)
# case 5
# ds = InnerDS(5)
# sampler = torch.utils.data.distributed.DistributedSampler(ds)
# dataloader = DataLoader(ds, batch_size=4, sampler=sampler, drop_last=False)
# case 6
# ds = InnerDS(10)
# sampler = torch.utils.data.distributed.DistributedSampler(ds)
# dataloader = DataLoader(ds, batch_size=4, sampler=sampler, drop_last=False)
# case 7
ds = InnerDS(10)
sampler = torch.utils.data.distributed.DistributedSampler(ds)
dataloader = DataLoader(ds, batch_size=4, sampler=sampler, drop_last=True)
for epoch in range(2):
# case 3+
# sampler.set_epoch(epoch)
for index,(_,labels, items) in enumerate(dataloader):
print(items.cuda())
# print('epoch:\t', epoch)
dist.barrier()
试验过程:
执行code: case 1, 不使用torch.utils.data.distributed.DistributedSampler, 结果显示,每块卡上(每个进程)每个epoch中都迭代了所有的数据。
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([0, 1, 2, 3], device='cuda:0')
tensor([0, 1, 2, 3], device='cuda:1')
tensor([4, 5, 6, 7], device='cuda:1')
tensor([4, 5, 6, 7], device='cuda:0')
tensor([0, 1, 2, 3], device='cuda:1')
tensor([0, 1, 2, 3], device='cuda:0')
tensor([4, 5, 6, 7], device='cuda:0')
tensor([4, 5, 6, 7], device='cuda:1')
执行code: case 2, 使用torch.utils.data.distributed.DistributedSampler, 结果显示,数据被平分到两块卡上,每个epoch被分配到每块卡上的数据都一样。
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([4, 7, 2, 1], device='cuda:0')
tensor([0, 3, 5, 6], device='cuda:1')
tensor([0, 3, 5, 6], device='cuda:1')
tensor([4, 7, 2, 1], device='cuda:0')
为了解决case 2中每块卡上分配的数据相同的问题,执行code: case 3, 在每个epoch中加入sampler.set_epoch(epoch)
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([0, 3, 5, 6], device='cuda:1')
tensor([4, 7, 2, 1], device='cuda:0')
tensor([5, 2, 7, 1], device='cuda:0')
tensor([4, 6, 3, 0], device='cuda:1')
执行code: case 4, 数据集里有6例数据,在两张卡,batch_size=4, drop_last=False时,每张卡上平均分配了3例数据;当drop_last=True时,不足4例数据的会被丢掉,在数据集只有6例数据时,每张卡上分配的3例数据都会被丢掉;
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([2, 3, 1], device='cuda:0')
tensor([5, 0, 4], device='cuda:1')
tensor([5, 0, 4], device='cuda:1')
tensor([2, 3, 1], device='cuda:0')
执行code: case 5, 数据集里有5例数据,两张卡,batch_size=4, drop_last=False时,每张卡上平均分配了2.5例数据, 会向上补齐到6例数据,每张卡上三张,补齐的标准是把数据集的第一例数据(在本例1中index=4)用来补齐;如果将sampler.set_epoch(epoch)加入其中,补齐标准不变,在本例2中,第一个epoch补齐的是index=4,第二个epoch补齐的是index=0
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([4, 1, 2], device='cuda:0')
tensor([0, 3, 4], device='cuda:1')
tensor([0, 3, 4], device='cuda:1')
tensor([4, 1, 2], device='cuda:0')
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([4, 1, 2], device='cuda:0')
tensor([0, 3, 4], device='cuda:1')
tensor([4, 3, 0], device='cuda:1')
tensor([0, 2, 1], device='cuda:0')
当多进程同时工作时,执行case 6时,有的迭代中,会出现batch_size=1的情况,如果模型中存在BatchNormalize这样的模块时,运行可能报错。
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([4, 7, 3, 0], device='cuda:0')
tensor([1, 5, 9, 8], device='cuda:1')
tensor([6], device='cuda:0')
tensor([2], device='cuda:1')
tensor([1, 5, 9, 8], device='cuda:1')
tensor([4, 7, 3, 0], device='cuda:0')
tensor([6], device='cuda:0')
tensor([2], device='cuda:1')
为了避免case 6这种情况,可以引入BatchSampler这样的模块,运行case 7, 将drop_last=True
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr='10.100.37.21' --master_port='29500' exp_ds_dist_sampler.py
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
tensor([4, 7, 3, 0], device='cuda:0')
tensor([1, 5, 9, 8], device='cuda:1')
tensor([1, 5, 9, 8], device='cuda:1')
tensor([4, 7, 3, 0], device='cuda:0')
https://blog.csdn.net/searobbers_duck/article/details/115299691
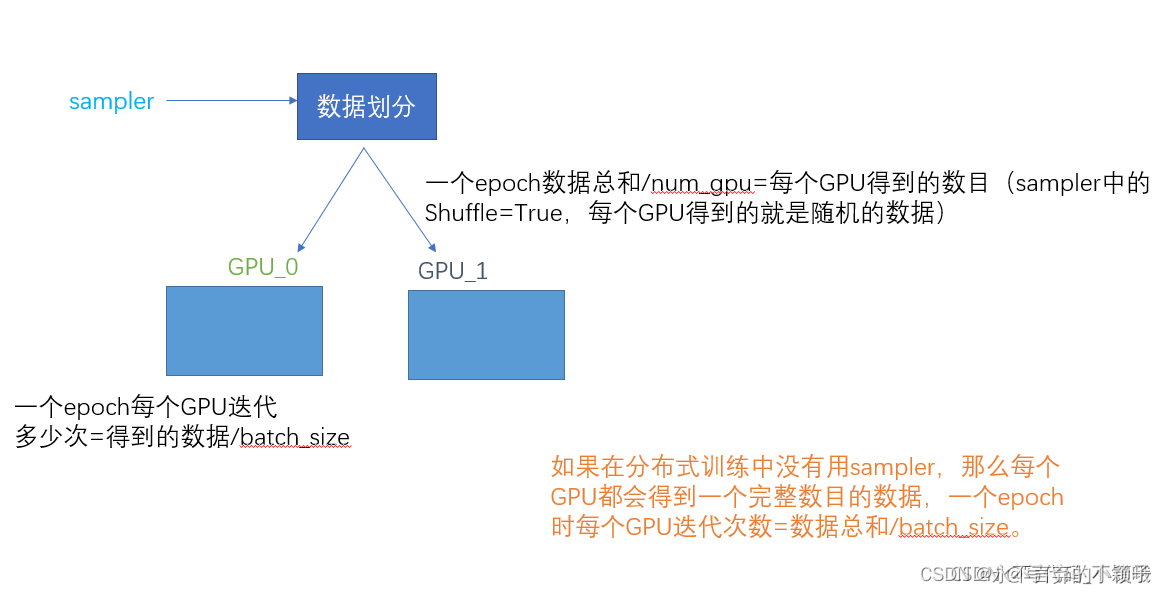
https://blog.csdn.net/shenjianhua005/article/details/121485522
使用 torch.multiprocessing 取代启动器
有的同学可能比较熟悉 torch.multiprocessing,也可以手动使用 torch.multiprocessing
进行多进程控制。绕开 torch.distributed.launch 自动控制开启和退出进程的一些小毛病~
使用时,只需要调用 torch.multiprocessing.spawn,torch.multiprocessing 就会帮助我们自动创建进程。如下面的代码所示,spawn 开启了 nprocs=4 个进程,每个进程执行 main_worker 并向其中传入 local_rank(当前进程 index)和 args(即 4 和 myargs)作为参数:
import torch.multiprocessing as mp
mp.spawn(main_worker, nprocs=4, args=(4, myargs))
这里,我们直接将原本需要 torch.distributed.launch 管理的执行内容,封装进 main_worker 函数中,其中 proc 对应 local_rank(当前进程 index),进程数 nprocs 对应 4, args 对应 myargs:
def main_worker(proc, nprocs, args):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
在上面的代码中值得注意的是,由于没有 torch.distributed.launch 读取的默认环境变量作为配置,我们需要手动为 init_process_group 指定参数:
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)
汇总一下,添加 multiprocessing 后并行训练部分主要与如下代码段有关:
# main.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
mp.spawn(main_worker, nprocs=4, args=(4, myargs))
def main_worker(proc, nprocs, args):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=gpu)
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
在使用时,直接使用 python 运行就可以了:
python main.py
使用 Apex 再加速
Apex 是 NVIDIA 开源的用于混合精度训练和分布式训练库。Apex 对混合精度训练的过程进行了封装,改两三行配置就可以进行混合精度的训练,从而大幅度降低显存占用,节约运算时间。此外,Apex 也提供了对分布式训练的封装,针对 NVIDIA 的 NCCL 通信库进行了优化。
from apex import amp
model, optimizer = amp.initialize(model, optimizer)
在分布式训练的封装上,Apex 在胶水层的改动并不大,主要是优化了 NCCL 的通信。因此,大部分代码仍与 torch.distributed 保持一致。使用的时候只需要将 torch.nn.parallel.DistributedDataParallel 替换为 apex.parallel.DistributedDataParallel 用于包装模型。在 API 层面,相对于 torch.distributed ,它可以自动管理一些参数(可以少传一点):
from apex.parallel import DistributedDataParallel
model = DistributedDataParallel(model)
# # torch.distributed
# model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
# model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)
在正向传播计算 loss 时,Apex 需要使用 amp.scale_loss 包装,用于根据 loss 值自动对精度进行缩放:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
汇总一下,Apex 的并行训练部分主要与如下代码段有关:
# main.py
import torch
import argparse
import torch.distributed as dist
from apex.parallel import DistributedDataParallel
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model, optimizer = amp.initialize(model, optimizer)
model = DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
在使用时,调用 torch.distributed.launch 启动器启动:
UDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
Horovod 的优雅实现
Horovod 是 Uber 开源的深度学习工具,它的发展吸取了 Facebook “Training ImageNet In 1 Hour” 与百度 “Ring Allreduce” 的优点,可以无痛与 PyTorch/Tensorflow 等深度学习框架结合,实现并行训练。
在 API 层面,Horovod 和 torch.distributed 十分相似。在 mpirun 的基础上,Horovod 提供了自己封装的 horovodrun 作为启动器。
与 torch.distributed.launch 相似,我们只需要编写一份代码,horovodrun 启动器就会自动将其分配给n个进程,分别在n 个 GPU 上运行。在执行过程中,启动器会将当前进程的(其实就是 GPU的)index 注入 hvd,我们可以这样获得当前进程的 index:
import horovod.torch as hvd
hvd.local_rank()
与 init_process_group 相似,Horovod 使用 init 设置GPU 之间通信使用的后端和端口:
hvd.init()
接着,使用 DistributedSampler 对数据集进行划分。如此前我们介绍的那样,它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
之后,使用 broadcast_parameters 包装模型参数,将模型参数从编号为 root_rank 的 GPU 复制到所有其他 GPU 中:
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
然后,使用 DistributedOptimizer 包装优化器。它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值:
hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), compression=hvd.Compression.fp16)
最后,把数据加载到当前 GPU 中。在编写代码时,我们只需要关注正常进行正向传播和反向传播:
torch.cuda.set_device(args.local_rank)
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
汇总一下,Horovod 的并行训练部分主要与如下代码段有关:
# main.py
import torch
import horovod.torch as hvd
hvd.init()
torch.cuda.set_device(hvd.local_rank())
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
在使用时,调用 horovodrun 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 horovodrun -np 4 -H localhost:4 --verbose python main.py
分布式 evaluation
all_reduce, barrier 等 API 是 distributed 中更为基础和底层的 API。这些 API
可以帮助我们控制进程之间的交互,控制 GPU 数据的传输。在自定义 GPU 协作逻辑,汇总 GPU
间少量的统计信息时,大有用处。熟练掌握这些 API 也可以帮助我们自己设计、优化分布式训练、测试流程。
- 训练样本被切分成了若干个部分,被若干个进程分别控制运行在若干个 GPU 上,如何在进程间进行通信汇总这些(GPU 上的)信息?
- 使用一张卡进行推理、测试太慢了,如何使用 Distributed 进行分布式地推理和测试,并将结果汇总在一起?
要解决这些问题,我们需要一个更为基础的 API,汇总记录不同 GPU 上生成的准确率、损失函数等指标信息。这个 API 就是 torch.distributed.all_reduce。
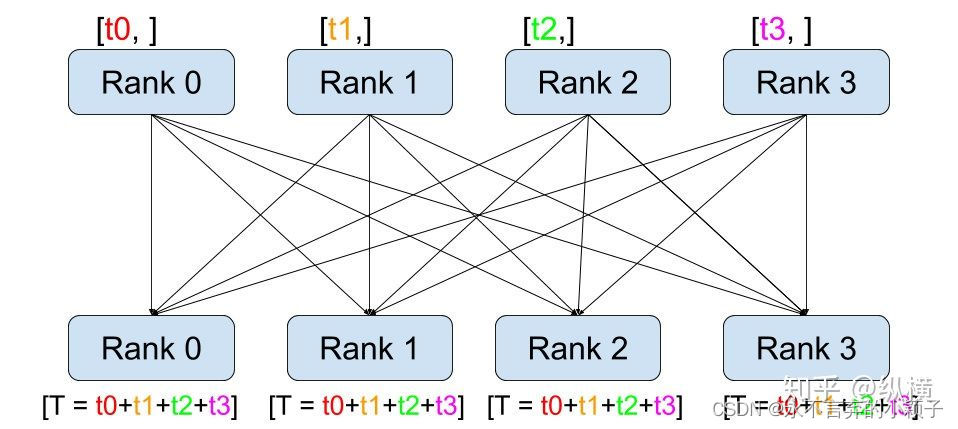
如上图所示,它的工作过程包含以下三步:
- 在调用
all_reduce(tensor, op=...)后,当前进程会向其他进程发送tensor(例如 rank 0 会发送rank 0 的 tensor 到 rank 1、2、3)。 - 同时,当前进程接受其他进程发来的 tensor(例如 rank 0 会接收 rank 1 的 tensor、rank 2 的 tensor、rank 3 的 tensor)。
- 在全部接收完成后,当前进程(例如rank 0)会对当前进程的和接收到的
tensor(例如 rank 0 的 tensor、rank 1 的 tensor、rank 2 的 tensor、rank 3 的 tensor)进行op(例如求和)操作。
使用 torch.distributed.all_reduce(loss, op=torch.distributed.reduce_op.SUM),我们就能够对不同数据切片(不同 GPU 上的训练数据)的损失函数进行求和了。接着,我们只要再将其除以进程(GPU)数量 world_size就可以得到损失函数的平均值。正确率也能够通过同样方法进行计算:
# 原始代码
output = model(images)
loss = criterion(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), images.size(0))
top1.update(acc1.item(), images.size(0))
top5.update(acc5.item(), images.size(0))
# 修改后,同步各 GPU 中数据切片的统计信息,用于分布式的 evaluation
def reduce_tensor(tensor):
rt = tensor.clone()
dist.all_reduce(rt, op=dist.reduce_op.SUM)
rt /= args.world_size
return rt
output = model(images)
loss = criterion(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
torch.distributed.barrier()
reduced_loss = reduce_tensor(loss.data)
reduced_acc1 = reduce_tensor(acc1)
reduced_acc5 = reduce_tensor(acc5)
losses.update(loss.item(), images.size(0))
top1.update(acc1.item(), images.size(0))
top5.update(acc5.item(), images.size(0))
值得注意的是,为了同步各进程的计算进度,我们在 reduce 之前插入了一个同步 API torch.distributed.barrier()。在所有进程运行到这一步之前,先完成此前代码的进程会等待其他进程。这使得我们能够得到准确、有序的输出。在 Horovod 中,我们无法使用 torch.distributed.barrier(),取而代之的是,我们可以在 allreduce 过程中指明:
def reduce_mean(tensor, world_size):
rt = tensor.clone()
hvd.allreduce(rt, name='barrier')
rt /= world_size
return rt
output = model(images)
loss = criterion(output, target)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
reduced_loss = reduce_tensor(loss.data)
reduced_acc1 = reduce_tensor(acc1)
reduced_acc5 = reduce_tensor(acc5)
losses.update(loss.item(), images.size(0))
top1.update(acc1.item(), images.size(0))
top5.update(acc5.item(), images.size(0))
使用 4 块 Tesla V100-PICE 在 ImageNet 进行了运行时间的测试,测试结果发现 Apex 的加速效果最好,但与
Horovod/Distributed 差别不大,平时可以直接使用内置的 Distributed。Dataparallel
较慢,不推荐使用。














 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









